DLSS 4 represents a substantial advancement in AI-driven rendering technologies, introducing new methods to improve
both performance and image quality in real-time graphics applications. One of the key innovations in DLSS 4 is
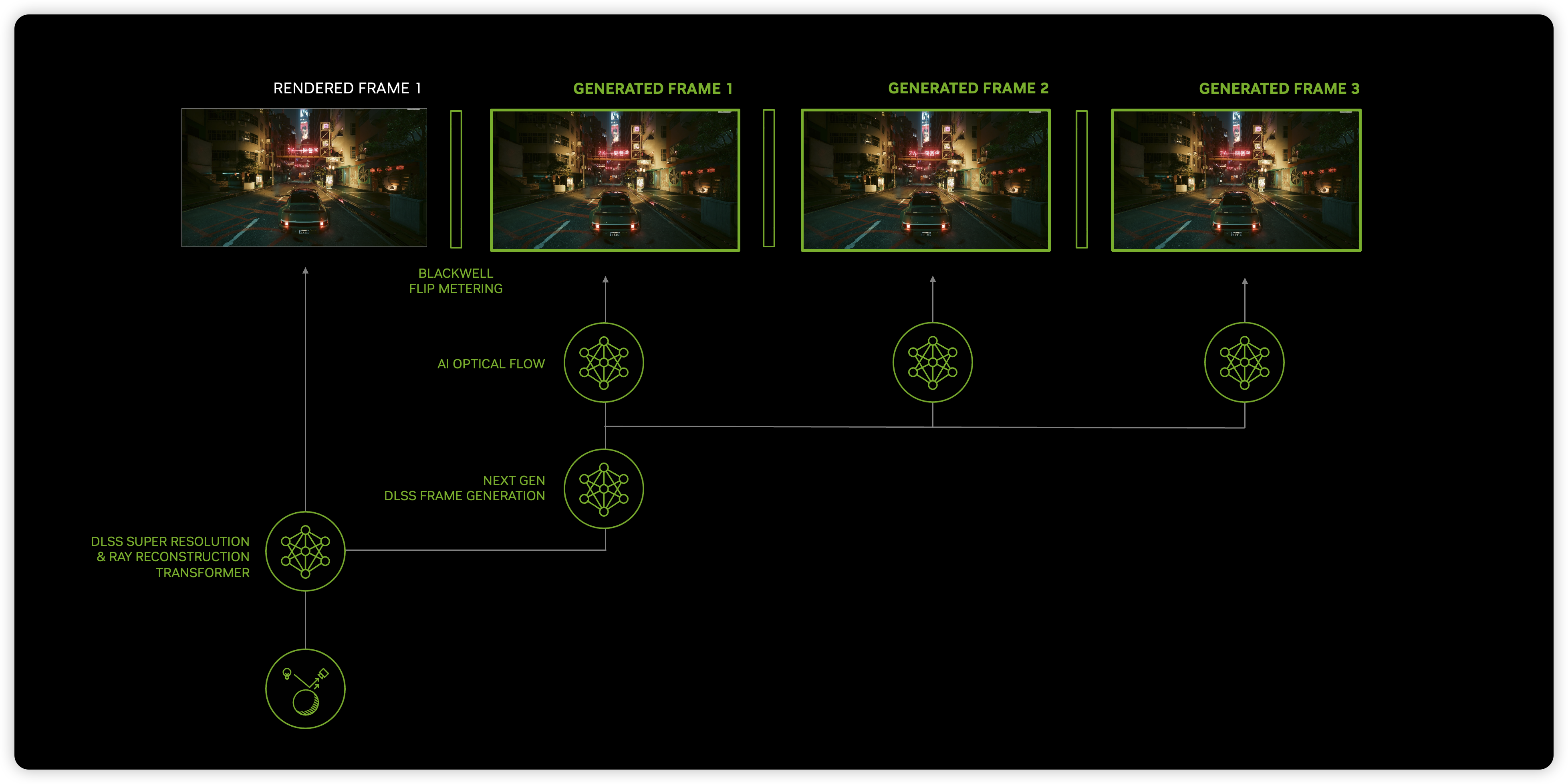
Multi Frame Generation, a technique that enables the generation of three additional frames for
every traditionally rendered frame. This approach results in a significant improvement in frame rates, effectively
achieving a fourfold increase in performance compared to native rendering. Unlike earlier methods that rely on
traditional optical flow to interpolate frames, DLSS 4 leverages an additional AI network to more efficiently and
accurately predict frame transitions, reducing artifacts and improving temporal consistency. This new approach
addresses the limitations of prior frame generation techniques by providing higher frame rates without compromising
visual stability.
In addition to Multi Frame Generation, DLSS 4 introduces transformer-based architectures for both
Ray Reconstruction and Super Resolution. Transformers, known for their capability to model complex spatial and
temporal relationships as well as supreme scalability, offer significant improvements over traditional convolutional backbones in image
reconstruction tasks. In Super Resolution, the transformer-based approach enhances detail preservation and reduces
common artifacts seen in upscaled images, while in Ray Reconstruction, it provides more accurate denoising for
ray-traced effects by capturing long-range dependencies across frames. These improvements result in more consistent
image quality across a variety of scenes and sampling patterns, addressing long-standing challenges in both
super resolution and denoising pipelines. Together, the advancements in DLSS 4 reflect an ongoing shift towards more
generalizable and efficient AI models in graphics rendering, with the goal of improving visual fidelity and
performance across diverse gaming environments.
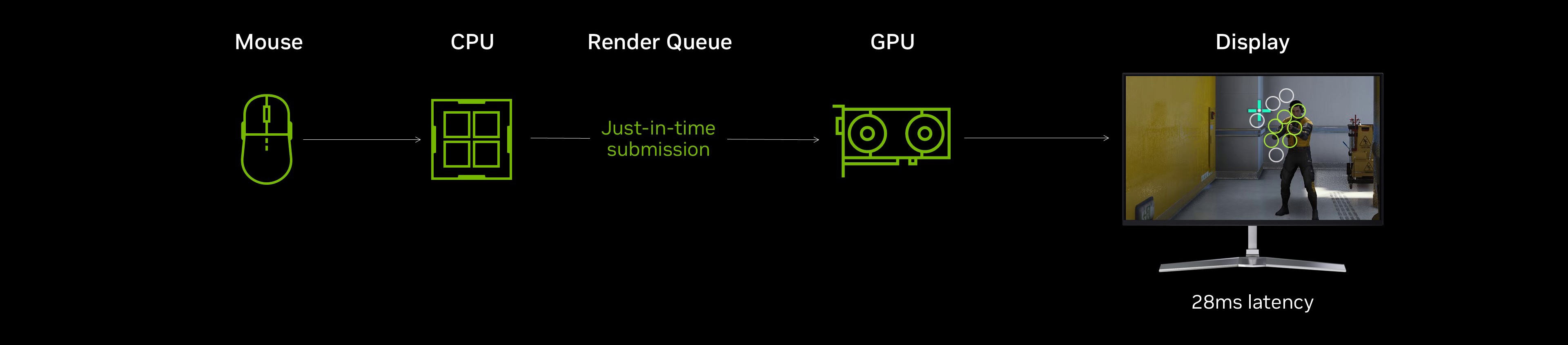
Moreover, NVIDIA also introduced Reflex Frame Warp, a technique designed to further reduce latency by
reprojecting the final rendered frame using the most recent player input. Frame Warp dynamically adjusts the output
based on updated camera and user data, ensuring that the displayed image closely aligns with the player's current
perspective. This approach lowers latency beyond what Reflex alone can achieve. Reflex Frame Warp provides an alternative trade-off for competitive games where
minimizing latency is paramount.
While there are countless exciting potential applications for neural rendering, our focus is on enhancing the three core pillars of the gaming experience:
exceptional image quality, ultra-smooth frame rates, and minimal input latency. Additionally, every component of the DLSS technology suite is designed
with ease of adoption and seamless integration in mind. This approach not only reduces the burden on developers and NVIDIA engineers—allowing rapid
integration into mainstream games—but also ensures that GeForce users can immediately benefit from these innovations. Although this practical focus
narrows the research domain, it guarantees that DLSS delivers extreme, tangible value in real-world production settings.
Together, these innovations represent a comprehensive evolution in real-time graphics, setting a new standard for performance, visual fidelity, and responsiveness
in modern gaming environments.
2. Multi Frame Generation
The new architecture driving NVIDIA's DLSS Multi Frame Generation product builds upon the foundation laid
by advances in both optimization of existing techniques and the research driving new state of the art
video frame interpolation. We want to highlight the challenges real-time products face in this space,
some of our solutions, and the potential we continue to pursue.
2.1. Why is frame generation hard?
Traditional frame interpolation research has primarily focused on generating frames for camera and natural video
contexts.
Common benchmarks
like Vimeo-90k, Middlebury, and UCF101 exemplify this bias. Sintel, often used in optical flow research, is a
rare exception but frequently less used for interpolation.
These datasets typically have low resolutions and frame rates due to the limited data availability and high
computational costs at the time they were created.
This bias has left a gap in experience with the kind of diverse, high-resolution, high-frame-rate data prevalent in
gaming. User interface elements, so ubiquitous in gaming content, are absent in natural videos,
making existing models and datasets perform quite poorly on an important component of gaming content. Consequently, no
existing model or training dataset did well enough on image
quality to meet our standards. Developing our own benchmark, training, and testing pipeline was an important part to
drive the quality forward.
Real-time gaming applications can also leverage additional inputs like motion
vectors, depth, masks, and other intermediate representations not available in natural video
contexts. This facilitates, in particular, large motion interpolation which is currently challenging
for near real-time state-of-the-art AI interpolation approaches as illustrated in the following
example where we compare DLSS 4 Frame Generation to two recent AI interpolation approaches FILM (Reda, et al. 2022)
and MoMo (Lew, et al. 2025).
However, while motion vectors and other intermediate representations might seem to simplify the problem,
they do not make it trivial. Although motion vectors (as typically computed for DLSS Super Resolution in modern engines)
are accurate for many pixels in the scene, they are inaccurate for specular highlights,
reflections, and UI motion. Depth, while important and helpful, can often be incorrect for opaque effects like lasers
and elements (like UI) drawn on the frame after geometric rasterization.
These effects also tend to dominate the perceptual experience
for users, despite being a relatively small number of the total pixels a user can see. As an example, the following is a
version of Frame Generation running purely on geometric motion vectors computed by the game engine. We can clearly
observe strong stutter artifacts on elements not modeled by motion vectors, such as shadows and UI.
One might think it is trivial to simply render UI at higher frame rates to completely solve UI interpolation, but there
are many cases where UI can be attached and move along with world space objects, such as names floating on top of NPCs
or bullet meters on guns. Rendering these at higher frame rates would require ticking the simulation logic on the CPU at
the same rate, adding significant computational overhead and necessitating deeper engine integration. This approach
often exacerbates CPU-bound scenarios rather than alleviating them. Therefore, designing the AI network to interpolate
UI robustly becomes a critical component in ensuring smooth and visually coherent experiences in real-time applications.
Indeed, learning to teach these networks how to see the value of these few sparse inputs when they exist
and are correct (such as geometry), and how to supplement them in the very few, but critical, places when they
are wrong (like UI and particle systems), is the heart of the practical challenge we need AI for. In our experience, navigating this
perceptually critical balance between when to use, and when not to use this information is
so complex that a learning-based and neural approach was the only solution that could
raise the ceiling of image quality high enough to meet the exacting standards that gamers have.
Something must also be said about the challenge of providing this product at real time rates,
with frame multipliers that can push frame rates beyond what even the best gaming monitors can
display. In order to be able to deliver 4K experiences of 240fps, 360fps, and beyond for users,
the budget for generating multiple frames is just a few milliseconds, and the complex dance
between the neural generation DLSS process, GPU scheduling, and display pacing quickly becomes
a limiting factor. Any missteps in that complex dance present to the user as skips, stutters,
or hitches and destroys the smooth high frame rate experience users are expecting. This is,
in part, why the new Multi Frame Generation uses hardware flip metering and shifts the frame pacing logic to the Blackwell display engine, enabling the GPU to more precisely manage display timing.
All these challenges are what make frame generation such an exciting research opportunity
for us to innovate and drive gaming forward.
2.2. Our new approach
Building on the successes of DLSS 3's Frame Generation, we wanted to maintain a similar
level of image quality but be able to generate additional frames within less time.
This is not trivial. In DLSS 3's Frame Generation, a single 4K frame could be generated
(thus doubling the frame rate) in around 3.25ms on a GeForce RTX 4090. In contrast DLSS 4's Multi Frame
Generation, each of the three new frames (a quadrupling of the frame rate) can be generated in around 1ms on average on a GeForce RTX 5090 at the time of launch.
It is a remarkable new upper bound for what can be expected from a real-time interpolation
product for gaming, and there is only room for improvement going forward.
We achieved this through a combination of architectural changes to the neural networks used
for Frame Generation, leveraging new capabilities of the RTX 50 Series graphics cards, and
careful optimization to maximize internal bandwidth tensor core utilization during
algorithmic execution.
2.2.1. Architectural Changes
The new DLSS Multi Frame Generation architecture splits the neural component of DLSS 3's
Frame Generation in half. One half of the network runs once for every input frame pair
and its output is then able to be re-used. The other (much smaller) half runs once for
every generated output frame. This split architecture allowed us to understand and optimize
these networks in parallel, helping to bring the final algorithmic latency within the target.
The new split architecture not only improves latency and efficiency but also enables enhanced flow estimation
capabilities. This improvement is particularly valuable for challenging scenarios like particle effects, where
traditional methods often struggle due to the complex, dynamic, and often sparse nature of these elements. By refining
flow estimation, the new architecture helps generate higher-quality frames, preserving the motion and coherence of
particles more accurately. The following side-by-side video demonstrates this improvement, showcasing how the enhanced
architecture leads to more visually consistent and seamless results in these challenging scenarios.
3. Transformer based Ray Reconstruction
Since the introduction of DLSS, AI-powered super resolution technology has become a cornerstone of modern
gaming graphics pipelines. Nearly every game today, regardless of platform or hardware limitations, leverages
some form of super resolution to deliver high-quality visuals while keeping performance overhead manageable. However,
while super resolution boosts performance, it has also exposed new challenges in ray-traced games, particularly
when it comes to denoising.
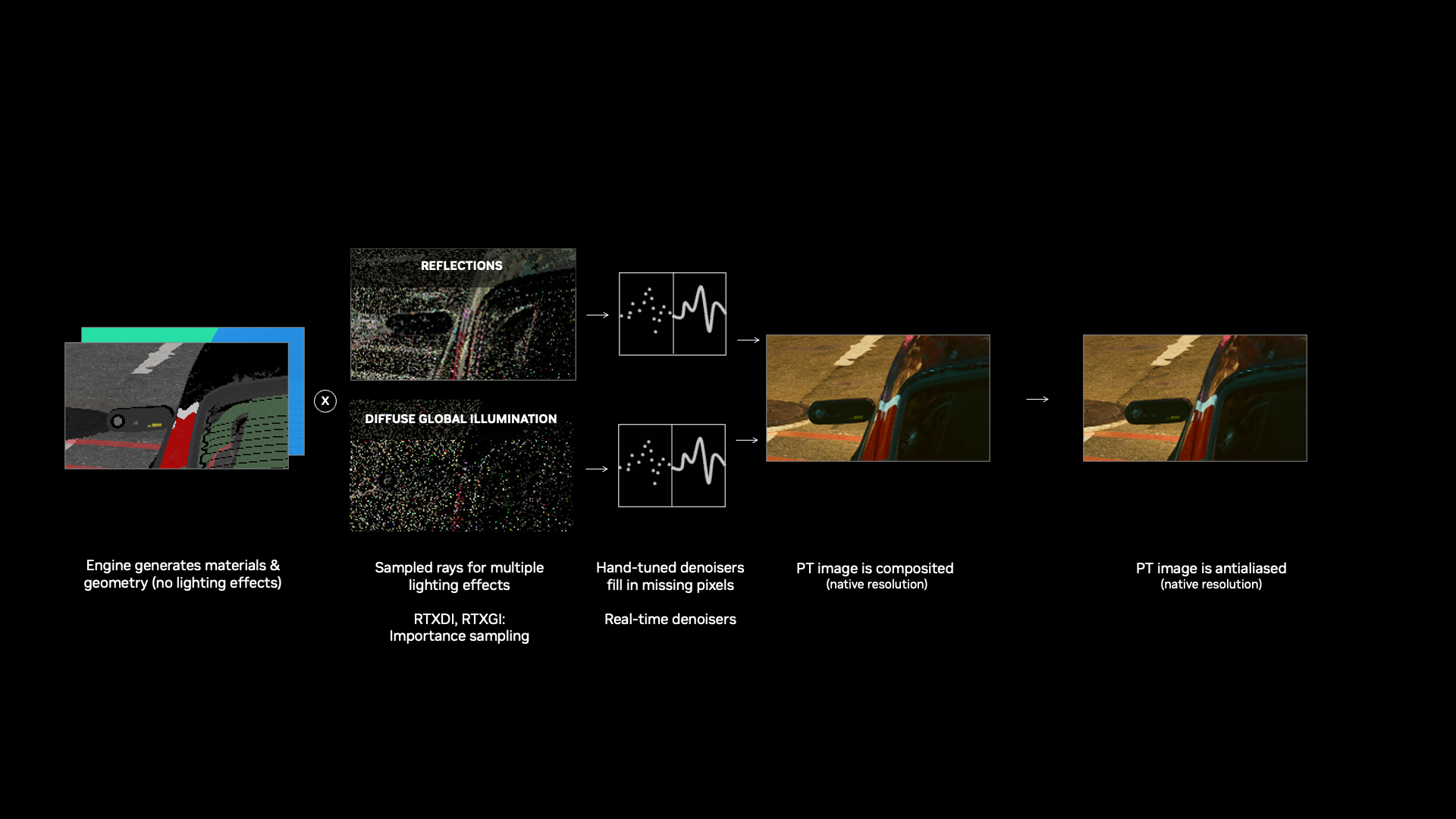
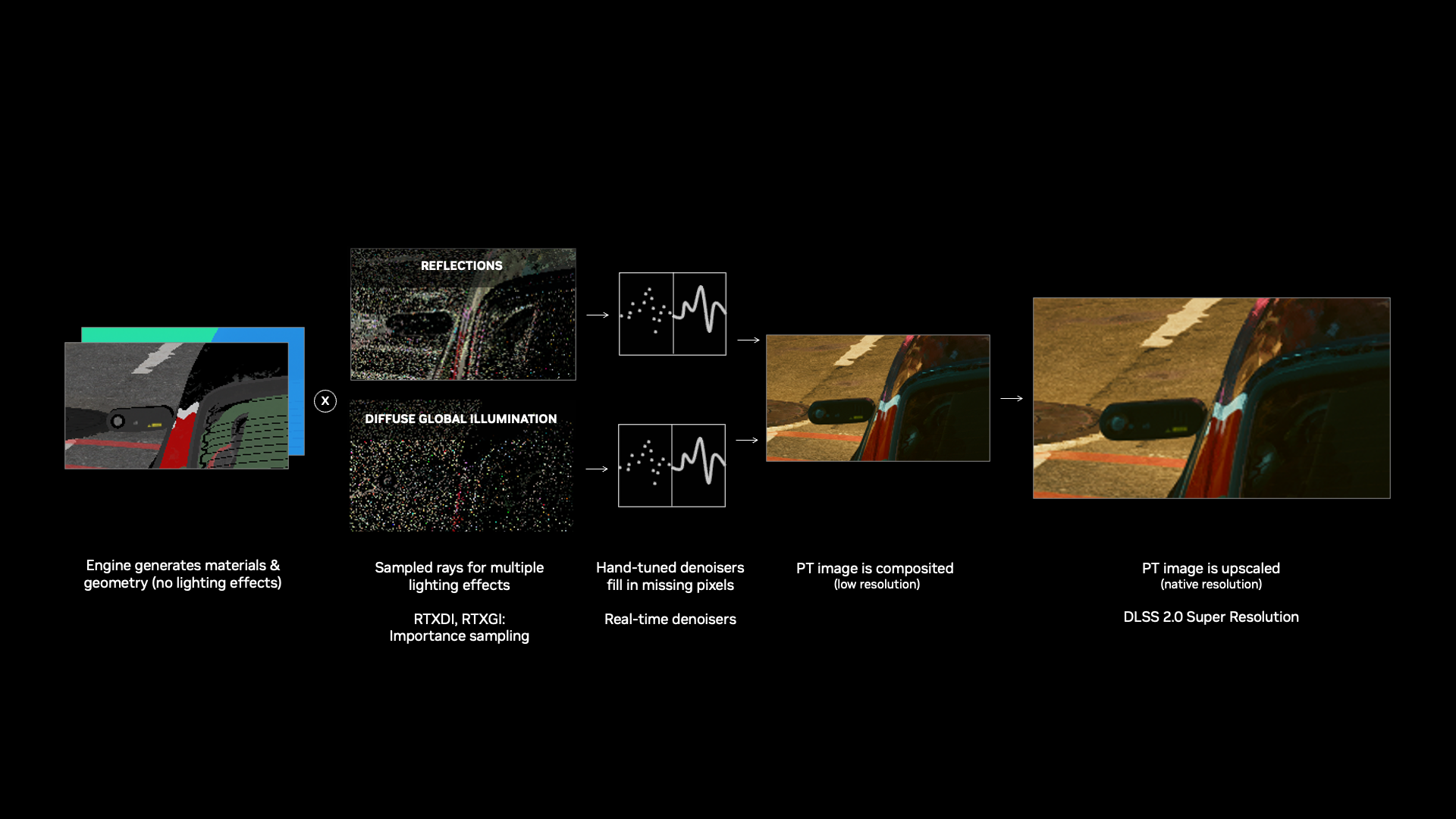
In a typical ray-traced rendering pipeline, denoising occurs at the lower input resolution before any
super resolution is applied. This means that ray-traced shading — such as reflections, global illumination,
or shadows — is processed at a reduced resolution and then passed through a super resolution model. While this workflow helps
maintain real-time performance, it compromises image quality: denoised ray-traced effects always appear
blurred and low resolution, especially in games where all lighting and shading is ray-traced. The final user
perceived image quality after super resolution is fundamentally constrained by the low-resolution shading. The following
is a comparison between full resolution ray-traced shading and low resolution ray tracing plus denoising followed
by 4x super resolution. Clearly, even though geometric details are reconstructed by the super resolution model, the shading quality remains
at the input resolution.
Traditional ray tracing denoisers rely on hand-tuned algorithms built on expert-derived heuristics to
make images look plausible, but not necessarily accurate to ground truth. These static denoisers are
constrained by fixed assumptions about lighting and materials, often introducing artifacts like
shimmering, ghosting, or inaccurate reflections. Moreover, they require extensive manual tuning to
work effectively in each game, making it time-consuming and difficult to scale them across different
environments.
DLSS Ray Reconstruction aims to fundamentally address both key limitations of traditional
denoisers: low-resolution shading and the need for expert tuning. By replacing hand-tuned denoisers with
a unified AI-driven pipeline, Ray Reconstruction processes ray-traced samples at high resolution,
ensuring that ray-traced visuals retain their fidelity even after super resolution. The result is a more accurate,
temporally stable, and dynamic solution that brings ray-traced graphics closer to ground truth
renderings without manual intervention.
The unified denoising and super resolution task in Ray Reconstruction is particularly challenging due to the need for
extremely aggressive temporal and spatial filtering to handle the sparse signals from low sample count path tracing.
These filters must preserve underlying geometry and texture details while filling in missing shading information.
Unlike traditional denoisers, which apply aggressive filtering only to shading signals before compositing with
textures and geometry, Ray Reconstruction must handle the entire scene holistically. In the example shown, the input for
Ray Reconstruction is a low-resolution buffer filled with noise from ray tracing or path tracing, along with visible
aliasing artifacts. The challenge lies in transforming such noisy, aliased inputs into high-resolution outputs that are
not only noise-free but also anti-aliased, all while retaining intricate texture and material details. Achieving this
balance is particularly demanding, as Ray Reconstruction must smooth out noise without over-blurring or compromising the
fidelity of the original scene's textures and materials.
Traditional denoisers often trade off temporal lag for stability, introducing a delay in how quickly they respond to
scene changes in order to reduce flickering and artifacts. However, training AI-based denoisers presents a unique
challenge: there is no obvious way to bias an AI model towards stability without introducing lag. Ray Reconstruction
must strike an optimal balance, delivering temporally stable visuals without noticeable lag. Achieving this balance
pushes the Pareto frontier between stability and responsiveness, a key challenge in temporal reconstruction that Ray
Reconstruction addresses head-on.
Another significant challenge is the variety of sampling patterns used in different games. Unlike the relatively
uniform Halton jitter patterns used in super resolution algorithms, path tracing produces a wide range of sampling
patterns, including white noise, blue noise, and quasi-Monte Carlo (QMC) methods. Additionally, modern algorithms
like
ReSTIR introduce both spatial and temporal correlations that further complicate the denoising process. The AI model
behind Ray Reconstruction needs to generalize across all these sampling patterns, requiring extensive and diverse
training data to handle these variations effectively.
Initially, convolutional neural networks (CNNs) were used as the backbone for Ray Reconstruction, but they quickly
reached their limits. As we scaled up the training dataset to improve generalization, we encountered issues like
ghosting, painterly artifacts, and a lack of temporal coherence. To overcome these limitations, we had to invent a
novel transformer-based architecture specifically tailored for NVIDIA's GPU
architecture. This custom design leverages the advanced tensor cores present in NVIDIA's latest GPUs (such as the Ada
and Blackwell generations) to accelerate matrix operations and ensure maximum throughput. By co-designing our
transformer network with highly efficient CUDA kernels and optimizing data flow to make full use of on-chip memory and
FP8 precision, we minimized latency and computational overhead while preserving the high fidelity of our output.
Unlike CNNs, transformers excel at handling long-range dependencies in both space and time, allowing the model to better
capture complex spatio-temporal relationships in ray-traced data. This architecture shift significantly improved
image quality, reduced artifacts, and enabled the model to generalize across diverse game scenarios. The
transformer's attention mechanism can effectively aggregate information from individual path traced samples that may be
spatially and temporally far from each other. This is especially crucial when the input data is noisy and weakly
correlated. By contrast, a CNN is fundamentally designed for spatially correlated inputs such as natural images,
which makes it ill-suited for noisy path traced data. Consequently, the transformer-based backbone
ensures that the denoising process is both stable and adaptive, offering a substantial leap in
temporal stability, detail preservation, and overall visual fidelity. With this advancement, Ray Reconstruction has
become a highly scalable solution capable of delivering near-ground truth visuals across a wide range of games and
rendering conditions.
This GPU-centric approach not only meets the stringent performance requirements of real-time rendering but also pushes the
boundaries of what transformer models can achieve in an AI-driven graphics pipeline.
3.1. Design and Optimization Philosophy
While initial experiments with the transformer-based network showed significant improvements over
the previous CNN model, it came with a prohibitively high computational cost.
We derived a more efficient network architecture to make this cost more practical and built a highly
optimized implementation that also took advantage of tensor core advances in the NVIDIA Ada Lovelace and NVIDIA Blackwell architectures,
realizing an industry first, real-time vision transformer model. Compared to the previous CNN model,
the transformer model packs four times the computations and twice the number of parameters, in a
similar frame budget.
We achieved this breakthrough by co-designing the network architecture alongside highly efficient CUDA kernels, ensuring
that the architecture's computational patterns align with the theoretical peak performance of the underlying hardware.
By carefully balancing compute throughput and memory bandwidth usage, we were able to unlock significantly more
efficiency from tensor cores. To further optimize performance, we ensured that both training and inference are conducted
in FP8 precision, which is directly accelerated by the next-generation tensor cores available on Blackwell GPUs. This
required meticulous optimizations across the entire software stack, from low-level instructions to compiler
optimizations and library-level improvements, ensuring that the model achieves maximum efficiency and accuracy within
the real-time performance budget.
3.2. Results
In this section, we analyze the improvements achieved by the transformer-based Ray Reconstruction model compared to
the previous convolutional-based model. The following results demonstrate the advantages of transformers in handling
complex ray-traced visuals, particularly in challenging areas such as surface details, temporal stability, and
disocclusion regions. To start, we highlight the transformer model's ability to produce outputs that are remarkably
close to the reference ground truth images, which are rendered using tens of thousands of samples per pixel. This
fidelity ensures that the transformer model's output is less painterly and significantly more faithful to the
path-traced reference obtained through pure accumulation. The following image comparison illustrates this closeness to
the reference image in a static scene, the left side of the swiper is ray reconstruction output while the right side is
ground truth:
Your text here
Reference
Transformer-based DLSS-RR
3.2.1. Improved Surface Details: The transformer model shows significantly improved surface details,
especially in areas with fine textures and high-frequency features. Unlike the previous CNN-based denoisers, which
tended to oversmooth these areas to reduce noise, the transformer effectively preserves subtle details, such as small
cracks, surface patterns, and reflections. This improvement enhances the overall realism of the scene. For all the comparisons
below, the CNN model is on the left and the transformer model is on the right.
CNN
Transformer
CNN
Transformer
CNN
Transformer
CNN
Transformer
CNN
Transformer
The following is one more side by side comparison between the CNN and transformer models. The CNN model on the left is running
at Quality mode with roughly 1.5x scaling ratio on both width and height while the transformer model on the right is running at
performance mode, meaning both width and height are upscaled by 2x. Clearly, the transformer model is able to deliver more surface
details while running at a lower scaling ratio.
3.2.2. Reduced Ghosting and Disocclusion Artifacts: Ghosting artifacts occur when a denoiser struggles to handle
fast-moving objects or dynamic lighting changes across frames. The transformer model demonstrates better handling of
these scenarios by leveraging its attention mechanism to track spatial-temporal relationships more effectively. As a
result, fast-moving objects retain their clarity, and the visual output remains sharp even in highly dynamic scenes.
Relatedly, disocclusion areas, where previously hidden parts of the
scene become visible due to object or camera movement, are particularly challenging for denoisers. These regions often
have very few temporally accumulated samples, leading to visible noise or artifacts. The transformer model shows
marked improvements in handling disocclusions, producing smoother and more accurate results by better generalizing
from available spatial context and efficiently filling in missing information.
3.2.3. Enhanced Temporal Stability: Temporal stability is critical for maintaining a coherent visual
experience across frames, particularly in games and real-time applications. Traditional models often struggle to
balance temporal stability with responsiveness to scene changes, resulting in flickering or lag. The transformer-based
model achieves a better balance, reducing flickering while maintaining responsiveness to changes in the scene. This
improvement is particularly evident in complex lighting transitions and dynamic environments, as demonstrated in the following video.
The left side of the video shows the CNN model while the right side shows the transformer model.
3.2.4. Improved Skin and Hair Rendering: Rendering realistic skin and hair is a complex task due to
their fine structures, translucency, and dynamic movement. The transformer-based model introduces dedicated support
for these challenging elements, enabling better preservation of fine details, smoother transitions, and more natural
lighting effects. These improvements are particularly noticeable in close-up scenes and dynamic animations, where
traditional models often fail to capture the subtle nuances. The following examples demonstrate how the transformer
model outperforms previous approaches, with the left side showing the CNN model and the right side showing the
transformer model.
Overall, the transformer-based Ray Reconstruction model demonstrates significant improvements across key visual
quality metrics, addressing longstanding challenges in real-time ray tracing. The following video showcases these
improvements in a real-world scene, highlighting the enhanced surface details, reduced ghosting, improved disocclusion
quality, and better temporal stability achieved with our transformer-based approach.
4. Transformer based Super Resolution
While transformers were initially introduced to address the challenges in Ray Reconstruction, we discovered during our
research that the same architecture also provided meaningful image quality improvements in super resolution tasks.
The attention mechanism inherent to transformers enables the model to capture long-range dependencies and better
understand the relationships between pixels across both spatial and temporal domains. This allowed the network to more
effectively preserve fine details, reduce artifacts, and adapt to different sampling patterns in upscaled images. As a
result, the transformer-based backbone achieved better generalization and visual consistency compared to traditional
convolutional networks, making it a natural evolution for super resolution pipelines as well. The shift to
transformers has fundamentally improved not only denoising, but also the entire AI-driven super resolution process, pushing
the boundaries of image quality and performance in modern gaming graphics.
4.1. Enhanced Surface Detail Preservation
One of the most significant improvements observed with the
transformer-based approach is its superior ability to preserve and reconstruct fine surface details. Traditional
convolutional networks often struggle with maintaining the intricate textures and patterns present in complex
surfaces, leading to loss of detail or over-smoothing. The transformer model's attention mechanism allows it to better
understand the contextual relationships between different texture elements, resulting in more accurate preservation of
surface characteristics. This improvement is particularly noticeable in areas with complex materials such as fabric,
foliage, and architectural details, where the model maintains crisp, defined textures even at higher super resolution
factors. The comparison video demonstrates this enhancement, with the transformer model (right) showing noticeably
more detailed and accurate surface textures compared to the CNN model (left).
CNN
Transformer
CNN
Transformer
The improvement in surface details is particularly noticeable when pixels are in motion. Traditional methods, which
rely on constant resampling of previous frame buffers, often suffer from over-blurring during motion, resulting in a
significant loss of fine detail. In contrast, the transformer model effectively mitigates this issue, delivering
sharper and more coherent textures even in dynamic scenes.
Furthermore, the enhanced surface details are not merely a result of artificial sharpening; they are genuinely more
accurate when compared to ground truth images rendered with hundreds of samples per pixel. This fidelity underscores
the model's ability to faithfully reconstruct textures and materials, closely aligning with the original scene. The
following comparisons demonstrate these improvements: on the left is the reference image, the middle shows the output
of the CNN model, and the right displays the output of the transformer model.
4.2. Reduced Artifacting in Complex Scenes
The transformer architecture has demonstrated remarkable
capability in minimizing common super resolution artifacts that have historically plagued super resolution techniques.
Traditional approaches often introduce ringing artifacts around sharp edges, aliasing in high-frequency patterns, and
unwanted smoothing in areas of fine detail. Through its ability to process global context and understand complex
feature relationships, the transformer model significantly reduces these issues. The model shows particular strength
in handling challenging scenarios such as diagonal lines, repeating patterns, and high-contrast edges, where
traditional methods typically struggle. The comparison footage clearly illustrates this improvement, with the
transformer model (right) showing fewer artifacts and cleaner image reconstruction compared to the CNN baseline
(left), especially in scenes with complex geometry and detailed textures.
CNN
Transformer
CNN
Transformer
4.3. Enhanced Anti-Aliasing Quality
This section focuses on the improved anti-aliasing capabilities
of the transformer model. One of the most notable improvements is the better reconstruction of straight geometric
edges,
which traditional CNN-based approaches often render as wobbly or uneven. The transformer model ensures these edges
remain smooth and true to their original form.
Additionally, it excels in handling moiré patterns, not only making them temporally stable—an area where CNN models
already outperform traditional super resolution models—but also reconstructing the underlying texture patterns with greater
fidelity. Finally, the transformer model reduces over-sharpening artifacts that often plague high-contrast edges,
ensuring a more natural and visually pleasing result. The following enlarged pixel peeping examples demonstrate these
improvements: better reconstruction of straight geometric edges, proper handling of moiré patterns, and reduced
over-sharpening on high-contrast edges. In all these results, CNN is on the left and transformer is on the right.
CNN
Transformer
CNN
Transformer
CNN
Transformer
5. Reflex Frame Warp
Traditional game rendering follows a pipeline where player input is processed by the CPU, queued for
the GPU, rendered, and then sent to the display. This process introduces latency, as the camera
perspective on screen always lags slightly behind the latest player input. NVIDIA Reflex, first introduced in 2020, effectively eliminated
the render queue delay in this process by better pacing the CPU. This resulted in improving responsiveness in competitive and single-player games alike.
However, there was still room to improve in the rest of the pipeline. Reflex Frame Warp builds
on this technology by incorporating Frame Warp, a late-stage reprojection technique that updates frames
based on the latest player input just before they are displayed, further reducing latency up to 75%.
5.1. Reprojection
Post-render reprojection is a class of technique which mitigates latency by warping an already rendered frame to a more recent camera position.
Reprojection has been used to great effect in the field of Virtual Reality but bringing this technology to the desktop
comes with its own set of unique challenges. The desktop cannot rely on dedicated hardware/sensors for input and moreover, any issues
with reprojection can be more visually apparent on a desktop monitor. Chiefly, reprojection can introduce visual artifacts
in the form of disocclusions—gaps where the scene reveals previously unseen areas due to the camera shift.
5.2. Disocclusions
To address disocclusions, we first minimize their occurrence in
the first place. While simple solutions such as rendering a guard band around the screen border and
layered rendering help reduce missing information, they do not fully address interior disocclusions,
especially in fast-moving gameplay.
To go further, we explored predictive rendering; instead of always rendering from a strictly
player-centered viewpoint, we extrapolate camera movement from user input and render at a predicted
position. The predicted frame is then warped to the true viewpoint before display, correcting any
deviation from actual player movement. This ensures that while predictive rendering reduces hole
size by anticipating camera shifts, the final image always aligns with the player's true perspective,
preserving aiming precision and user feel. Even with simple ballistic prediction, this approach
significantly lowers average disocclusion size while maintaining near-zero performance impact.
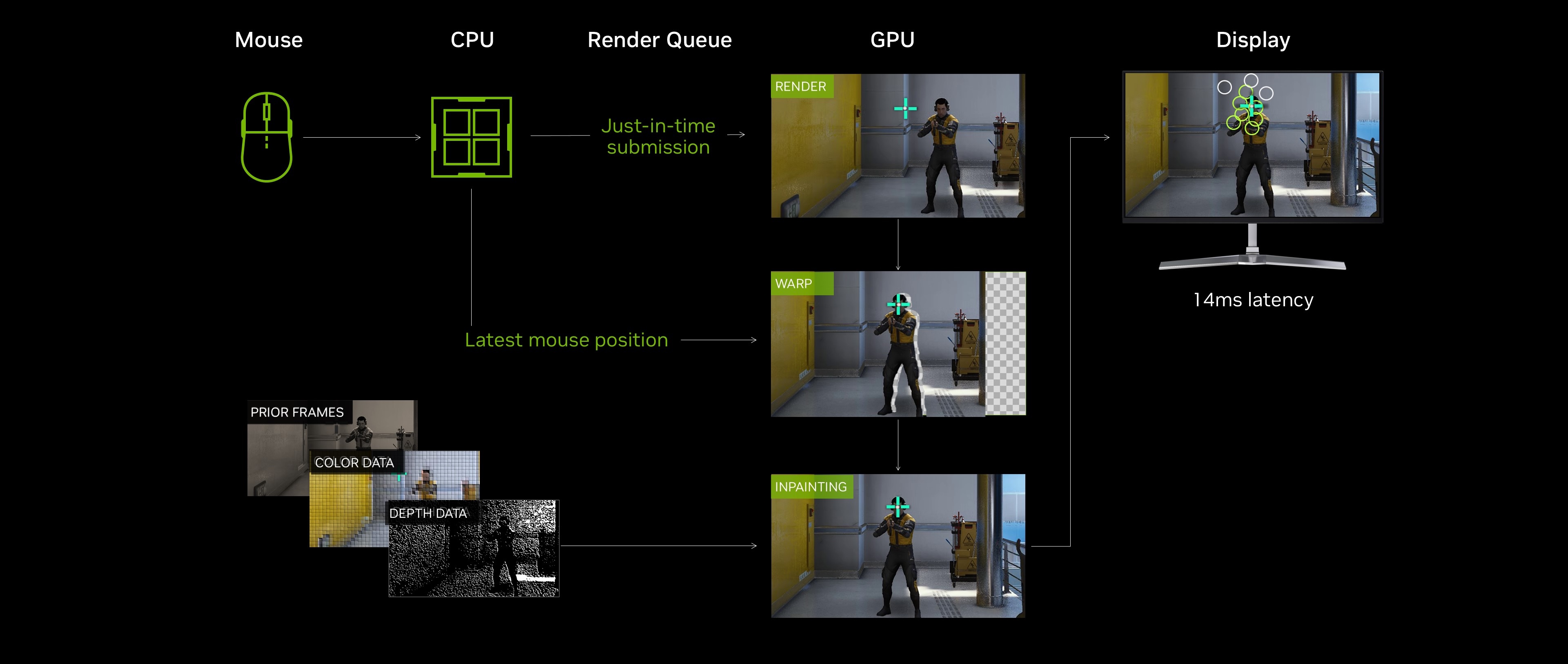
5.3. Inpainting
The remaining holes from reprojection need to be filled plausibly: a
classic problem for AI. Frame Warp addresses this using a latency-optimized approach that incorporates
historical frame data, G-buffers from predictive rendering, and upcoming camera information to
reconstruct missing areas. By leveraging temporal and spatial data, the system ensures that newly revealed
regions preserve visual consistency while dynamically adjusting algorithm fidelity to maximize
latency savings.
5.4. Latency savings
Reflex Frame Warp delivers tangible improvements in real-world scenarios. In THE FINALS, enabling
Reflex Low Latency mode reduces latency from 56ms to 27ms, while enabling Reflex Frame Warp with Frame Warp
further cuts it to 14ms—an overall 75% latency reduction. In CPU-limited scenarios such as VALORANT
running at 800+ FPS on an RTX 5090, Reflex Frame Warp brings latency down to under 3ms, one of the lowest figures
recorded for a first-person shooter.
6. Optimization
To meet real-time performance requirements, we implemented several high-level optimizations in our DLSS 4 transformer
network. First, we fused non-DL logic (such as data format conversion and buffering) with DL kernels to minimize data
transfer and keep the dataflow local. Second, we vertically fused consecutive transformer layers into a single kernel,
ensuring that intermediate results remain on-chip and maximizing available bandwidth. Finally, by training our network
with FP8 Tensor Core formats and adapting associated non-Tensor Core logic, we dramatically increased throughput while
preserving accuracy. Together, these optimizations allow our network to fully leverage NVIDIA's advanced GPU
architecture for faster, more efficient performance.
7. Conclusion
DLSS 4 represents a significant evolution in real-time graphics, introducing new advancements that push the boundaries
of both performance and image quality through AI-driven rendering. At the core of this release are two major
innovations: Multi Frame Generation and Transformer-based Ray Reconstruction and Super
Resolution. These advancements tackle long-standing challenges in rendering pipelines by simultaneously
boosting frame rates and visual fidelity, critical requirements for next-generation gaming experiences.
Real-time frame generation presents unique challenges not typically encountered in traditional video interpolation
research. Existing models and datasets, primarily developed for natural video content, struggle with gaming-specific
elements like user interfaces (UI), high frame rates, and diverse scene dynamics. Additionally, gaming engines provide
intermediate inputs such as motion vectors and depth maps, but these are often inaccurate for effects like
reflections, specular highlights, and UI motion. Teaching the network to effectively use these inputs where reliable
and supplement them where they are not — particularly in perceptually critical areas — required an AI-based approach.
Achieving the necessary image quality within real-time performance constraints made frame generation a particularly
complex task.
In addition to further improving frame generation, DLSS 4 incorporates transformer-based Ray Reconstruction and Super Resolution
to further enhance image quality. The transformer model demonstrates significant improvements in surface detail
preservation, artifact reduction, disocclusion handling, and temporal stability. These improvements result from our
co-design of network architectures alongside efficient CUDA kernel implementations, allowing DLSS 4 to fully leverage
the latest NVIDIA hardware, particularly the tensor cores introduced in the Ada and Blackwell architectures.
Furthermore, Frame Warp provides an additional step forward in minimizing latency by reprojecting
the final rendered frame using the most up-to-date player input right before the image is displayed. This real-time
reprojection ensures that the on-screen view aligns closely with the user's current perspective, significantly reducing
input lag. Frame Warp offers an alternative approach for those
who prioritize lower latency, delivering a more responsive experience in both competitive and single-player games.
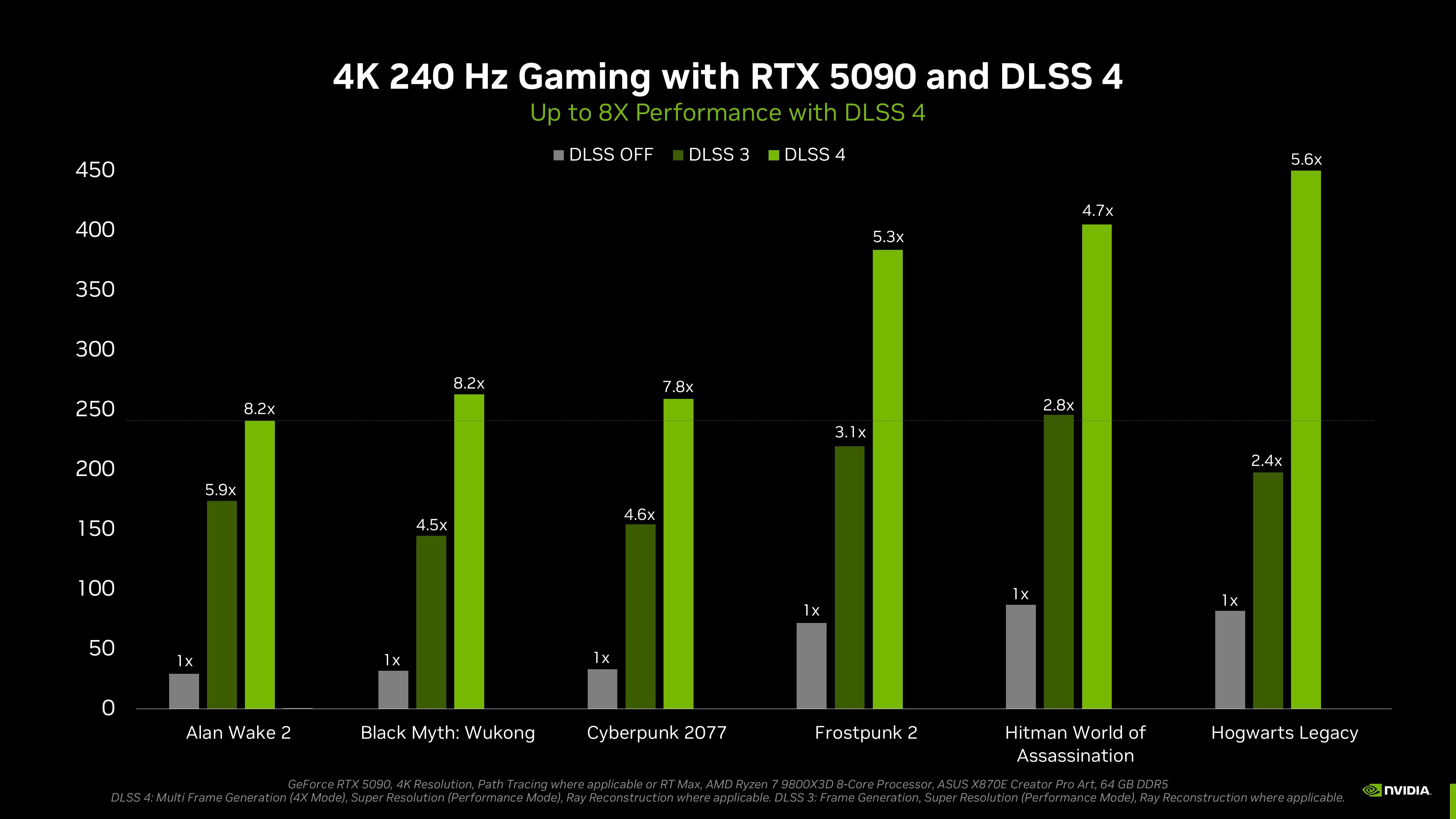
In real-world gaming scenarios, DLSS 4 delivers transformative improvements in both visual quality and frame rates compared to native rendering. As demonstrated in titles like Avowed, enabling DLSS 4 can boost frame rates from 35 FPS to an impressive 215 FPS while maintaining equivalent or superior image quality. This represents a remarkable 6x increase in frame rates, simultaneously reducing input latency from 114ms down to just 43ms—a 62% reduction that significantly enhances responsiveness and gameplay feel.
What's particularly noteworthy is that DLSS 4 also builds substantially upon the already impressive foundation laid by DLSS 3, delivering enhanced visual fidelity through its transformer-based architecture while simultaneously achieving even greater frame rate increases. The transformer-based approach provides improved detail preservation and reduced artifacts compared to the previous CNN-based implementation, all while further increasing frame rates.
Across a wide range of popular titles including Alan Wake 2, Black Myth: Wukong, Cyberpunk 2077, and Hogwarts Legacy, DLSS 4 consistently delivers frame rate multipliers ranging from 4.7x to as high as 8.2x over native rendering. This consistent improvement in smoothness across diverse gaming environments highlights how AI has fundamentally changed the traditional tradeoff between image quality and frame rates—a paradigm shift where both visual fidelity and gameplay fluidity can be dramatically improved simultaneously rather than requiring compromise between the two. This breakthrough represents one of the most significant advances in real-time computer graphics of the past decade.
The results presented in this report illustrate that DLSS 4 is more than an incremental improvement — it is a complete
AI-driven rendering technology suite that sets a new industry standard for real-time graphics. By addressing the
unique challenges of gaming applications through learning-based approaches and optimizing the entire software stack,
DLSS 4 delivers both state-of-the-art performance and visual fidelity. These advancements demonstrate that AI is now a
core pillar of future rendering technologies, enabling games to achieve unprecedented levels of smoothness,
responsiveness, and realism.
A. References
Andreev, D. (2010). Real-time Frame Rate Up-conversion for Video Games. Presented at SIGGRAPH 2010.
Link
Reda, F. A., Sun, D., Saurous, R. A., Milanfar, P., & Pritch, Y. (2022). FILM: Frame Interpolation for Large Motion.
In Proceedings of the European Conference on Computer Vision (ECCV).
Link
Lew, J., Choi, J., Shin, C., Jung, D., & Yoon, S. (2025). Disentangled Motion Modeling for Video Frame Interpolation.
In Proceedings of The Thirty-Ninth AAAI Conference on Artificial Intelligence 2025, to be published.
Link
Chaitanya, C. R. A., Kaplanyan, A. S., Schied, C., Salvi, M., Lefohn, A., Nowrouzezahrai, D., & Aila, T. (2017).
Interactive Reconstruction of Monte Carlo Image Sequences using a Recurrent Denoising Autoencoder.
In ACM Transactions on Graphics (TOG), 36(4), Article 98.
Link
Liu, E. (2020). DLSS 2.0 - Image Reconstruction for Real-Time Rendering with Deep Learning. Presented at GTC 2020.
Link
Liu, E. (2024). Revolutionizing Ray Tracing with DLSS 3.5: AI-Powered Ray Reconstruction. Presented at High-Performance Graphics (HPG) 2024.
Link
Yang, L., Liu, S., & Salvi, M. (2020). A Survey of Temporal Antialiasing Techniques.
In Computer Graphics Forum, 39(2), 607–621.
Link
Balint, M., Wolski, K., Myszkowski, K., Seidel , H.-P., & Mantiuk, R. (2023).
Neural Partitioning Pyramids for Denoising Monte Carlo Renderings.
In SIGGRAPH '23 Conference Proceedings.
Link
Thomas, M. M., Liktor, G., Peters, C., Kim, S., Vaidyanathan, K., & Forbes, A. G. (2022).
Temporally Stable Real-Time Joint Neural Denoising and Supersampling.
In Proceedings of High-Performance Graphics (HPG) 2022.
Link
NVIDIA Corporation. (2025). NVIDIA DLSS 4.0: Multi Frame Generation and Transformer-Based Upscaling for Real-Time Rendering.
Link
A. Core Contributors
Frame Generation
Robert Pottorff, Jarmo Lunden, Gagan Daroach, Andrzej Sulecki,
Wiktor Kondrusiewicz, Michal Pestka, Megamus Zhang, Shawn He, Ziad Ben Hadj Alouane, Zhekun Luo, Ethan Tillison, Sungbae Kim, Kirill Dmitriev, Anand Purohit
Ray Reconstruction
James Norton, Juho Marttila, Jussi Rasanen, Karthik Vaidyanathan,
Pietari Kaslela, David Tarjan, Sophia Zalewski, Abhijit Bhelande, Pekka Janis
Super Resolution
Gregory Massal, Loudon Cohen, Antoine Froger, Anjul Patney
Reflex Frame Warp
Loudon Cohen, Gene Liu, Ziad Ben Hadj Alouane, Robert Pottorff, Josef Spjut, Seth Schneider
Technical Strategy & Leadership
Jason Mawdsley, Timo Roman, Andrew Tao, Bryan Catanzaro, Edward Liu
A. Citation
Please cite this work as "DLSS 4" Below is the BibTeX entry for citation:
@misc{dlss4,
author = {NVIDIA Corporation},
title = {{DLSS 4: Transforming Real-Time Graphics with AI}},
howpublished = {\url{https://research.nvidia.com/labs/adlr/DLSS4/}},
note = {Technical Report},
year = {2025}
}