Author: Sang-gil Lee *, Zhifeng Kong *, Arushi Goel, Sungwon Kim, Rafael Valle, Bryan Catanzaro
Posted: Sang-gil Lee
Overview
Recent years have seen significant progress in Text-To-Audio (TTA) synthesis, enabling users to enrich their creative workflows with synthetic audio generated from natural language prompts. Despite this progress, the effects of data, model architecture, training objective functions, and sampling strategies on target benchmarks are not well understood.
With the purpose of providing a holistic understanding of the design space of TTA models, we setup a large-scale empirical experiment focused on diffusion and flow matching models. Our contributions include:
AF-Synthetic, a large dataset of high quality synthetic captions obtained from an audio understanding model.
A systematic comparison of different architectural, training, and inference design choices for TTA models.
An analysis of sampling methods and their Pareto curves with respect to generation quality and inference speed.
We leverage the knowledge obtained from this extensive analysis to propose our best model dubbed Elucidated Text-To-Audio (ETTA). When evaluated on AudioCaps and MusicCaps, ETTA provides improvements over the baselines trained on publicly available data, while being competitive with models trained on proprietary data.
Finally, we show ETTA’s improved ability to generate creative audio following complex and imaginative captions — a task that is more challenging than current benchmarks.
Creative Audio Generation Showcase
Below we demonstrate ETTA can follow the captions and generate creative audio and music sounds that require blending and transformation of various sound elements using complex and imaginative captions.
AudioLDM2
TANGO2
Stable Audio Open
ETTA(Ours)
A hip-hop track using sounds from a construction site—hammering nails as the beat, drilling sounds as scratches, and metal clanks as rhythm accents.
AudioLDM2
TANGO2
Stable Audio Open
ETTA(Ours)
A saxophone that sounds like meowing of cat.
AudioLDM2
TANGO2
Stable Audio Open
ETTA(Ours)
A techno song where all the electronic sounds are generated from kitchen noises—blender whirs, toaster pops, and the sizzle of cooking.
AudioLDM2
TANGO2
Stable Audio Open
ETTA(Ours)
Dogs barking, birds chirping, and electronic dance music.
AudioLDM2
TANGO2
Stable Audio Open
ETTA(Ours)
Dog barks a beautiful and fast-paced folk melody while several cats sing chords while meowing.
AudioLDM2
TANGO2
Stable Audio Open
ETTA(Ours)
A time-lapse of a city evolving over a thousand years, represented through shifting musical genres blending seamlessly from ancient to futuristic sounds.
AudioLDM2
TANGO2
Stable Audio Open
ETTA(Ours)
An underwater city where buildings hum melodies as currents pass through them, accompanied by the distant drumming of bioluminescent sea creatures.
AudioLDM2
TANGO2
Stable Audio Open
ETTA(Ours)
A factory machinery that screams in metallic agony.
AudioLDM2
TANGO2
Stable Audio Open
ETTA(Ours)
A lullaby sung by robotic voices, accompanied by the gentle hum of electric currents and the soft beeping of machines.
AudioLDM2
TANGO2
Stable Audio Open
ETTA(Ours)
A soundscape with a choir of alarm siren from an ambulance car but to produce a lush and calm choir composition with sustained chords.
AudioLDM2
TANGO2
Stable Audio Open
ETTA(Ours)
The sound of ocean waves where each crash is infused with a musical chord, and the calls of seagulls are transformed into flute melodies.
AudioLDM2
TANGO2
Stable Audio Open
ETTA(Ours)
Mechanical flowers blooming at dawn, each petal unfolding with a soft chime, orchestrated with the gentle ticking of gears.
AudioLDM2
TANGO2
Stable Audio Open
ETTA(Ours)
The sound of a meteor shower where each falling star emits a unique musical note, creating a celestial symphony in the night sky.
AudioLDM2
TANGO2
Stable Audio Open
ETTA(Ours)
A clock shop where the ticking and chiming of various timepieces synchronize into a complex polyrhythmic composition.
AudioLDM2
TANGO2
Stable Audio Open
ETTA(Ours)
An enchanted library where each book opened releases sounds of its story—adventure tales bring drum beats, romances evoke violin strains.
AudioLDM2
TANGO2
Stable Audio Open
ETTA(Ours)
A rainstorm where each raindrop hitting different surfaces produces unique musical pitches, forming an unpredictable symphony.
AudioLDM2
TANGO2
Stable Audio Open
ETTA(Ours)
A carnival where the laughter of children and carousel music intertwine, and the sound of games and rides blend into a festive overture.
AudioLDM2
TANGO2
Stable Audio Open
ETTA(Ours)
A futuristic rainforest where holographic animals emit digital soundscapes, and virtual raindrops produce glitchy electronic rhythms.
AudioLDM2
TANGO2
Stable Audio Open
ETTA(Ours)
An echo inside a cave where droplets of water create a cascading xylophone melody, and bats’ echolocation forms ambient harmonies.
AudioLDM2
TANGO2
Stable Audio Open
ETTA(Ours)
A steampunk cityscape where steam engines puff in rhythm, and metallic gears turning produce mechanical melodies.
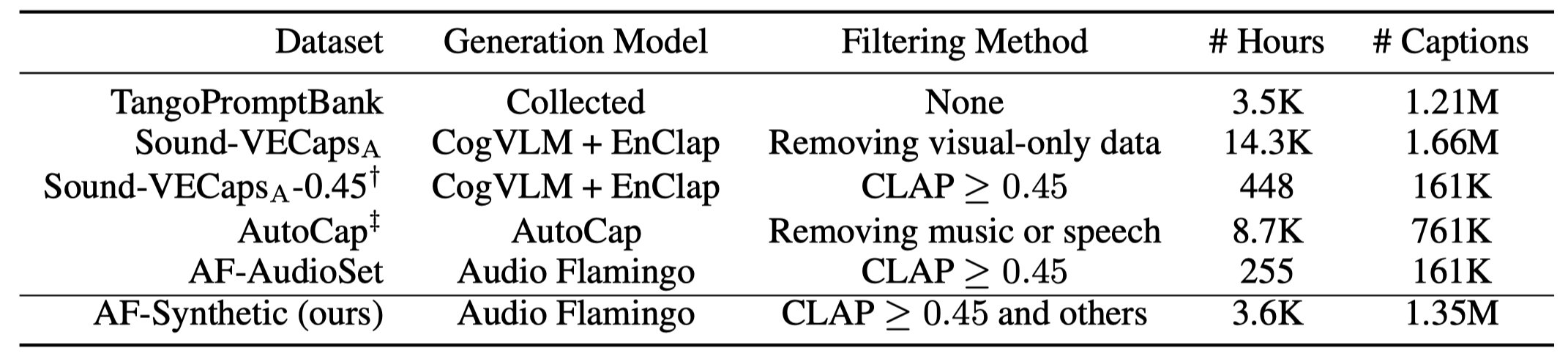
AF-Synthetic Dataset
AF-Synthetic is the first million-size synthetic caption dataset with strong audio correlations (1.35M captions with CLAP similarity >= 0.45).
Below table provides an overview of our proposed AF-Synthetic dataset compared to existing synthetic captions datasets. AF-Synthetic improves the caption generation pipeline in AF-Audioset and applies it to a variety of datasets, leading to a large-scale and high-quality synthetic dataset of captions.
ETTA Model
ETTA is built upon the Latent diffusion model (LDM) paradigm and its application to audio generation. Core components of ETTA include the VAE, LDM and an improved DiT implementation:
ETTA-VAE is a 156M variational auto-encoder (VAE) trained on our large-scale collection of publicly available datasets. ETTA-VAE compresses waveform into a compact latent space with a frame rate of 21.5Hz, and it supports 44.1kHz stereo audio.
ETTA-LDM is a latent diffusion model (LDM) that models the data distribution in the latent space of ETTA-VAE. It is parameterized with our 1.29B Diffusion Transformer (DiT) with 24 layers, 24 heads, and a width of 1536. We use T5 embeddings to encode text prompts and cross attention to condition on the embeddings. ETTA-LDM is trained with optimal transport conditional flow matching (OT-CFM).
ETTA-DiT is our improved Diffusion Transformer (DiT) implementation. We improved the adaptive layer normalization (AdaLN), applied zero initialization to the final layers, used the tanh approximation mode of the GELU activation, used rotary position embedding (RoPE) with with rope_base=16384 for positional encoding, and applied dropout for robustness.
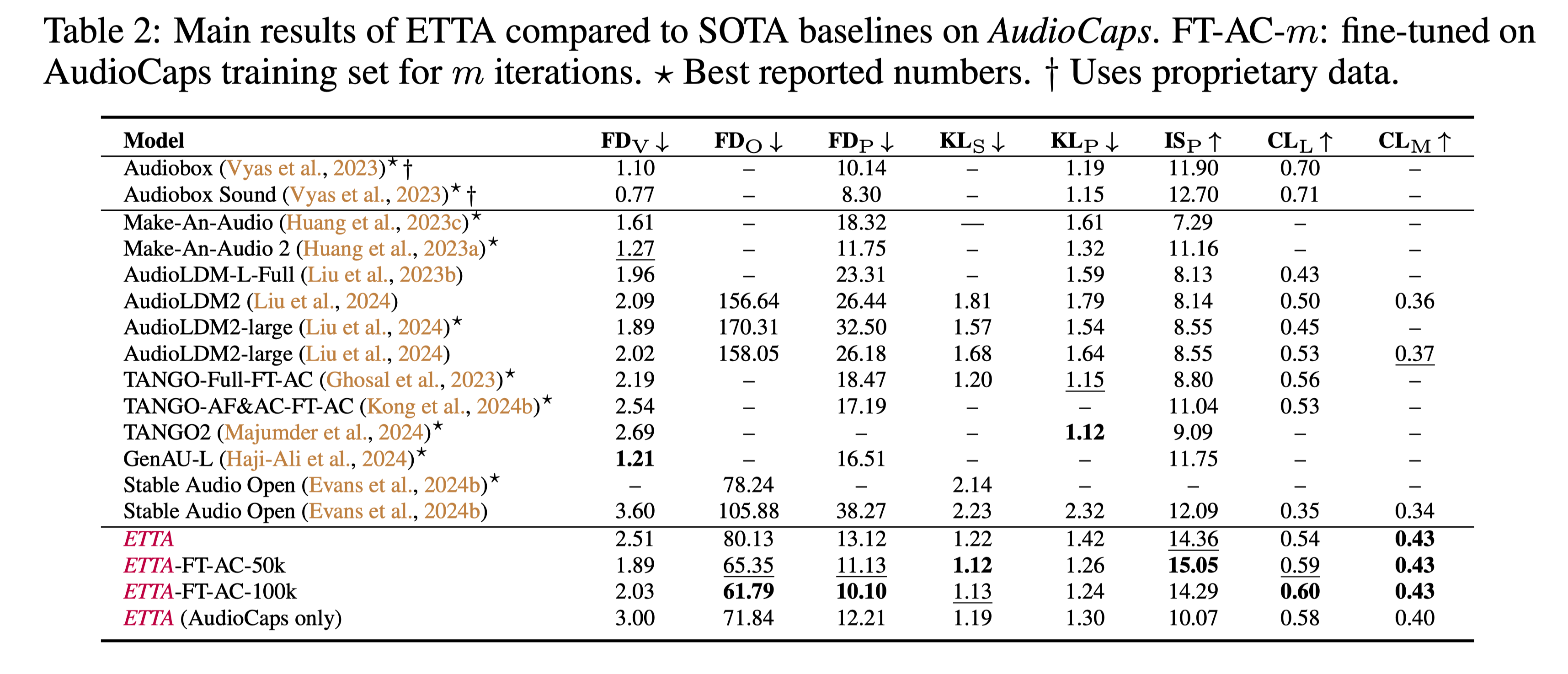
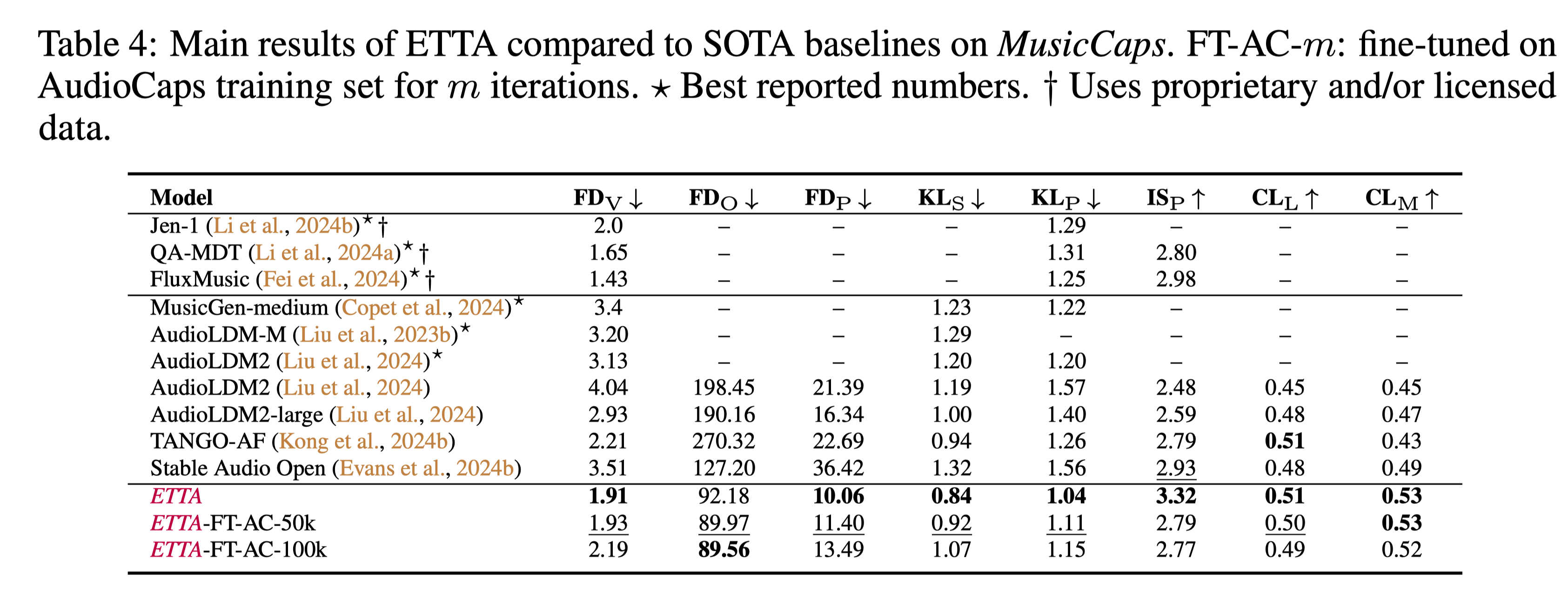
Benchmark Results
ETTA is the SOTA text-to-audio and text-to-music generation model using only publicly available data. It is also comparable to models trained with proprietary and/or licensed data.
Below table summarizes the main results of ETTA compared to SOTA baselines on AudioCaps benchmark.
Below table summarizes the main results of ETTA compared to SOTA baselines on MusicCaps benchmark.