
Nemotron-CC: Transforming Common Crawl into a Refined Long-Horizon Pretraining Dataset
Published:
Paper Dataset Implementation in NeMo Curator (coming soon)
Author: Dan Su*, Kezhi Kong*, Ying Lin*, Joseph Jennings, Brandon Norick, Markus Kliegl, Mostofa Patwary, Mohammad Shoeybi, Bryan Catanzaro
Posted: Markus Kliegl
Overview
We are excited to release Nemotron-CC, our high quality English Common Crawl based 6.3 trillion tokens dataset (4.4T globally deduplicated original tokens and 1.9T synthetically generated tokens).
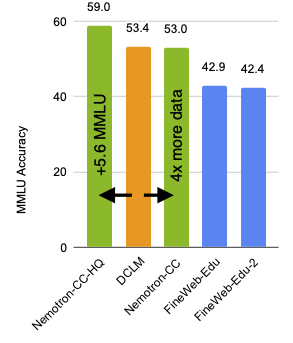
Compared to the leading open English Common Crawl dataset DCLM, Nemotron-CC enables to either create a 4x larger dataset of similar quality or increase the MMLU by more than 5 points using a high quality subset of the tokens. Having a larger dataset, in the sense of unique real tokens, is crucial when training over long horizons such as 15T tokens. Indeed, an 8B parameter model trained for 15T tokens, of which 7.2T came from Nemotron-CC, is better than the Llama 3.1 8B model: +5 on MMLU, +3.1 on ARC-Challenge, and +0.5 on average across ten diverse tasks.
- Paper: https://arxiv.org/abs/2412.02595
- Dataset: Hosted at commoncrawl.org
- Implementation in NeMo Curator (coming soon)
Technical Highlights
Our work demonstrates the following key points:
- Ensembling different model-based classifiers can help select a larger and more diverse set of high quality tokens.
- Rephrasing can effectively reduce noise and errors in low-quality data and produce diverse variants with fresh unique tokens from high-quality data, leading to better results in downstream tasks.
- Disabling traditional non-learned heuristic filters for high-quality data can further boost high quality token yield without hurting accuracy.
Our overall guiding principle is to shift from a static, non-learned, heuristic pipeline towards a more learned flywheel whose accuracy will naturally get better over time. As our data improves, so will the large language models we train, and these improved large language models will in turn improve our data as we use them to generate better synthetic data and quality classifications.
Citation
Please cite our paper if you use this dataset:
@misc{su2024nemotroncctransformingcommoncrawl,
title={Nemotron-CC: Transforming Common Crawl into a Refined Long-Horizon Pretraining Dataset},
author={Dan Su and Kezhi Kong and Ying Lin and Joseph Jennings and Brandon Norick and Markus Kliegl and Mostofa Patwary and Mohammad Shoeybi and Bryan Catanzaro},
year={2024},
eprint={2412.02595},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.02595},
}
Acknowledgments
We thank the Common Crawl Foundation for hosting the dataset. We thank Pedro Ortiz Suarez for valuable feedback that improved the paper and Greg Lindahl for help with improving the data formatting and layout.