
Nemotron-CrossThink: Scaling Self-Learning beyond Math Reasoning
Published:
[Paper] [Data 🤗]
Author: Syeda Nahida Akter, Shrimai Prabhumoye, Matvei Novikov, Seungju Han, Ying Lin, Evelina Bakhturina, Eric Nyberg, Yejin Choi, Mostofa Patwary, Mohammad Shoeybi, Bryan Catanzaro
📌 Summary:
Nemotron-CrossThink facilitates scaling RL-based self-learning beyond math, into messy, diverse, real-world reasoning tasks like law, physics, history, social sciences, etc. Nemotron-CrossThink introduces a systematic framework to:
- Curate multi-domain corpora spanning STEM, humanities, law, social science, etc.
- Apply structured templates (open-ended and multiple-choice) for scalable, verifiable rewards
- Blend and filter data for maximum generalization
- Train models that reason more broadly (+27.5–30.1% accuracy gains in math and +3.8–15.1% gains in non-math reasoning tasks), think more efficiently (28% fewer tokens used for correct responses), and adapt dynamically across tasks
Overview
Figure 1: Nemotron-CrossThink out-performs baseline models, including domain-specific training (Only Math) and Open-Reasoner-Zero (ORZ-7B), achieving consistent gains across all reasoning tasks.
Large Language Models (LLMs) have made tremendous progress in reasoning, especially in mathematical and coding domains where correctness is clearly defined. Reinforcement Learning (RL) has been pivotal in refining these abilities by rewarding correct multi-step thinking. However, extending RL beyond math—to the broader world of law, physics, social science, and humanities—remains challenging. Defining verifiable rewards becomes much harder when solutions are subjective, multi-modal, or narrative-driven.
We introduce Nemotron-CrossThink — a systematic framework for scaling RL-based self-learning to diverse reasoning domains beyond math. Instead of staying confined to rule-based problems, Nemotron-CrossThink trains models to tackle open-ended, real-world reasoning tasks by intelligently curating, blending, formatting, and filtering multi-domain corpora. By carefully designing question templates and applying lightweight difficulty filtering, Nemotron-CrossThink enables verifiable, scalable, and broadly generalizable self-learning across both structured and unstructured reasoning challenges.
Key Characteristics of Nemotron-CrossThink:
- Multi-Domain Curation: Incorporates synthetic and open-domain question-answer pairs across STEM, law, humanities, social science, and more.
- Structured Reasoning Templates: Applies open-ended and multiple-choice formats to control answer diversity and enable verifiable reward modeling even for complex domains.
- Optimal Blending Strategies: Balances data from multiple reasoning types, outperforming math-only training with significant gains across general-purpose reasoning benchmarks.
- Difficulty-Aware Filtering: Selects harder examples by eliminating easy questions solvable by smaller models, strengthening downstream robustness.
Why Nemotron-CrossThink Matters!
🧠 Broad Reasoning Generalization: Models trained with Nemotron-CrossThink achieve substantial gains across both math (+30.1% on MATH-500) and non-math (+15.1% on AGIEVAL, +12.8% on MMLU-Pro) reasoning tasks.
🚀 Efficient Thinking: By dynamically adapting response strategies across domains, Nemotron-CrossThink-trained models use 28% fewer tokens for correct answers without sacrificing rigor.
🛠 Stable and Verifiable Reward Modeling: By applying structured question and answer templates—favoring open-ended formats and concise outputs—CROSSTHINK stabilizes reward learning and improves performance by over 1.2%.
🚀 Difficulty-Aware Filtering: Filtering out easier samples based on smaller model performance yields an additional 2.15% accuracy gain for larger models like Qwen-2.5-32B, demonstrating efficacy of filtering and scalable benefits as model size grows.
How to build Nemotron-CrossThink?

Figure 2: Nemotron-CrossThink. We (a) curate QA pairs from from synthetic (Common Crawl) and open-source datasets, categorized into general-purpose reasoning ($D_{gpr}$) and mathematical reasoning ($D_{mr}$); (b) apply structured templates to convert data into multiple-choice (MCQ) and open-ended formats, promoting diverse reasoning trajectories; (c) filter out unverifiable or ill-formatted responses; (d) train an RL policy using Group Relative Policy Optimization (GRPO). The final reward is used to update the policy, iteratively improving the model’s reasoning capabilities across diverse domains.
Nemotron-CrossThink trains LLMs by curating diverse reasoning data, applying structured templates to enable verifiable rewards, and filtering for high-quality samples. Blended datasets are used to fine-tune models with Group Relative Policy Optimization (GRPO), achieving scalable and stable self-learning across multiple domains. The curated data consists of two major components:
- Nemotron-CrossThink-QA: Question-answer pairs constructed from raw CommonCrawl and open-domain books using category-specific templates inspired by MMLU-Pro. These samples cover a wide range of disciplines including physics, law, social science, and economics, following both multiple-choice and open-ended formats.
- Nemotron-CrossThink-Math: We take inspiration from PersonaMath to generate diverse math problems generated by extracting persona from CommonCrawl and prompting models to synthesize math problems of certain skills. We extract the skills from existing math benchmarks and diversify them by applying different persona. This subset emphasizes multi-step symbolic reasoning and chain-of-thought generation.
Scaling Reasoning with Nemotron-CrossThink: Results and Insights
To understand how different domain compositions affect self-learning, we compared various training blends under consistent reinforcement learning conditions using Qwen2.5-7B-Base and GRPO.
Figure 3: Nemotron-CrossThink achieves the highest overall average accuracy, outperforming single domain, naturally sampled blends and ORZ — underscoring the benefit of self-learning with diverse reasoning data.
🔥 Key Takeaways:
- The Nemotron-CrossThink achieves the highest average accuracy, outperforming math-only blends and well-established Open-Reasoner-Zero (ORZ).
- Including more diverse, real-world reasoning domains significantly boosts non-math performance compared to math-only blends—improving AGIEVAL by +2.3%, MMLU-Pro by +3.6%, and SUPERGPQA by +1.5%—while maintaining competitive math scores. Combining general-purpose reasoning with math exposes the model to varied cognitive strategies, enhancing flexibility and adaptability.
➣ Dynamic and Efficient Reasoning with Nemotron-CrossThink
💡 Reason Shorter when Needed, Think Longer when Necessary!
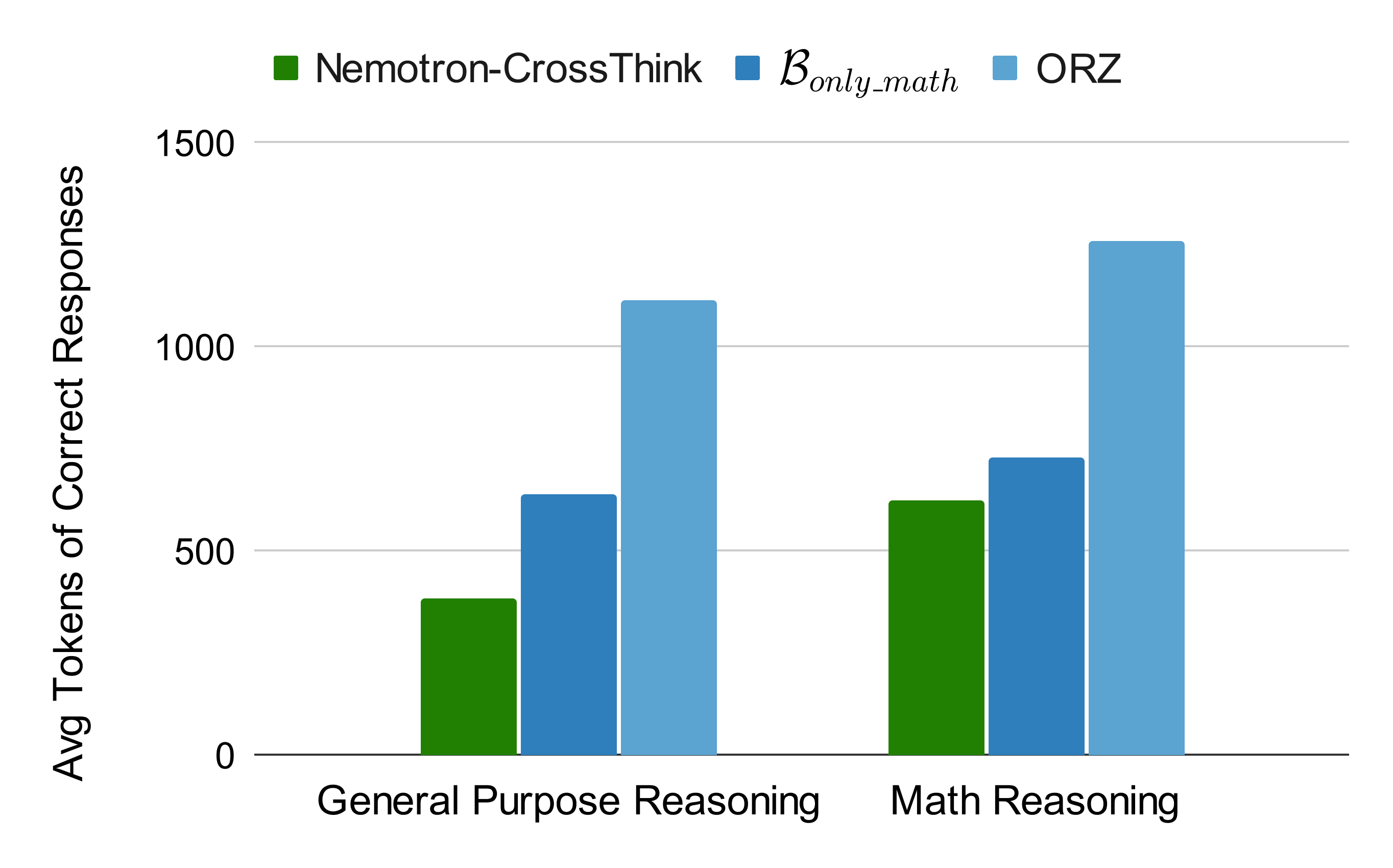
Figure 4: Token efficiency comparison of models trained on Nemotron-CrossThink (multi-domain blend) and two single domain blends ($\mathcal{B}_{only_math}$ and ORZ).
Nemotron-CrossThink not only improves accuracy but also adapts response length across domains—using 229 tokens on MMLU compared to 351 tokens for math-only training. It dynamically expands responses by 62% when shifting from general reasoning (385 tokens) to math tasks (622 tokens), while math-only models show just 12–14% change. This flexibility leads to 28% fewer tokens overall for correct answers, reducing inference cost without sacrificing rigor.
➣ Templates, Tokens, and Thinking Styles
💡 Better formatting → Stronger reasoning.
Figure 5: [Left] Impact of Question Format. Converting all questions to open-ended format improves accuracy across benchmarks, reducing reliance on option guessing and encouraging deeper reasoning. [Right] Impact of Answer Format. Using short-form answers improves accuracy by reducing output ambiguity and avoiding penalization from rigid reward functions in rulebased training.
Training with open-ended question formats improves average benchmark performance by +1.21%, as it forces models to reason from scratch rather than guess among options—eliminating reward hacking and enhancing generalization. Additionally, using short-form answers (only outputting the option label) yields another +1.20% gain by reducing output ambiguity and avoiding noisy supervision. These findings highlight that thoughtful formatting of both questions and answers directly strengthens reasoning and reward alignment during RL.
➣ Selective Difficulty: The Key to Stronger Self-Learning
💡 Focusing on harder examples leads to more accurate, more generalizable models!
Figure 6: Difficulty-Based Filtering. Filtering Nemotron-CrossThink to retain only hard examples yields consistent gains across all tasks, highlighting the effectiveness of selective training on challenging data.
Filtering out easy questions—those solved by a smaller model in zero-shot—boosts average accuracy by +2.15%, despite training on less data. Models trained only on harder examples achieve consistent gains across all benchmarks, with up to 8% improvements on complex tasks like MMLU-Pro, GPQA-Diamond, and AGIEVAL. This suggests that selectively training on challenging examples can yield more robust and generalizable models, likely due to stronger gradient signals and a focus on harder-to-learn reasoning patterns.
Conclusion
We introduce Nemotron-CrossThink that pushes reinforcement learning beyond math, enabling LLMs to reason across law, physics, social science, and more. By combining multi-domain data curation, structured templates, and difficulty-aware filtering, it achieves +27.5–30.1% gains on math, +3.8–15.1% on non-math tasks, and uses 28% fewer tokens for correct responses. This finding demonstrates that integrating multi-domain, multi-format data in RL leads to more accurate, efficient, and generalizable LLMs.
Citation
@misc{akter2025nemotroncrossthinkscalingselflearningmath,
title={Nemotron-CrossThink: Scaling Self-Learning beyond Math Reasoning},
author={Syeda Nahida Akter and Shrimai Prabhumoye and Matvei Novikov and Seungju Han and Ying Lin and Evelina Bakhturina and Eric Nyberg and Yejin Choi and Mostofa Patwary and Mohammad Shoeybi and Bryan Catanzaro},
year={2025},
eprint={2504.13941},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2504.13941},
}