
Nemotron-MIND: Math Informed syNthetic Dialogues for Pretraining LLMs
Published:
[Paper] [Data 🤗]
Author: Syeda Nahida Akter, Shrimai Prabhumoye, John Kamalu, Sanjeev Satheesh, Eric Nyberg, Mostofa Patwary, Mohammad Shoeybi, Bryan Catanzaro
Overview
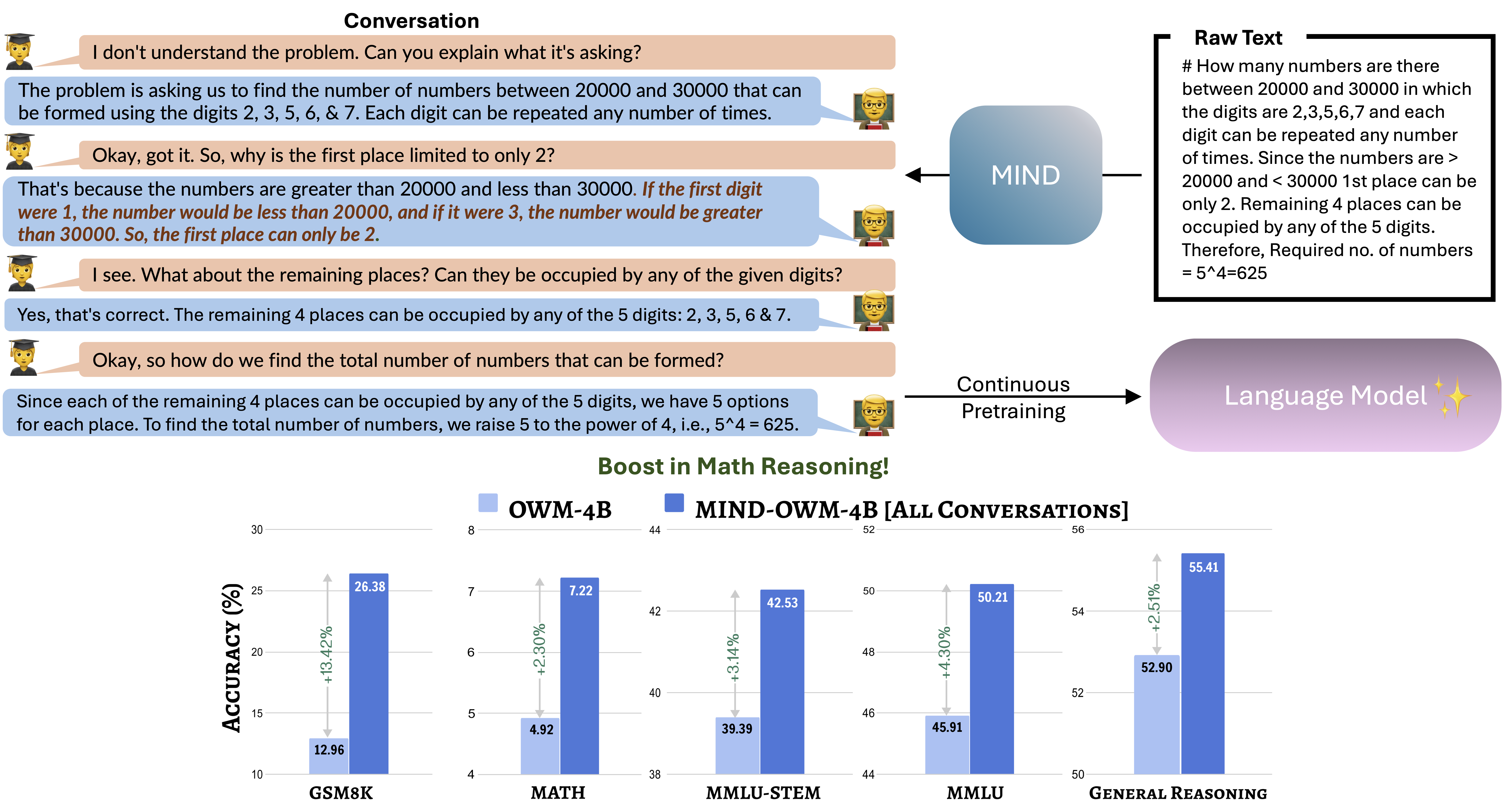
Figure 1: Continuous pretraining with all styles of conversations (MIND-OWM-4B) derived from a small subset (OWM-4B) and a 3.6x large raw corpus (OWM-14B) reveals that model trained with conversations (MIND-OWM-4B) outperforms the one trained with larger original raw corpus (OWM-14B) in GSM8K, MMLU and general reasoning—showing the significance of high-quality structured data over quantity.
Large language models (LLMs) are getting better at general tasks, but when it comes to complex reasoning—especially in mathematics—they often struggle. We hypothesize that strong reasoning ability heavily relies on the abundance of high-quality, composite, and structured pretraining corpora. Most pretraining corpora, especially synthetic ones, lack this structured scaffolding that guides models through multi-step thinking.
We introduce Math Informed syNthetic Dialogue (MIND)—a scalable method to generate high-quality, multi-turn conversations rooted in mathematical reasoning using seven conversational prompts. Instead of feeding raw or rephrased web text to an LLM, we use a pretrained model to convert mathematical content from OpenWebMath (OWM) into conversations that simulate collaborative, step-by-step problem-solving. The result is a new dataset, Nemotron-MIND, with over 138 billion tokens of structured mathematical dialogues1.
Key Characteristics of Nemotron-MIND:
- Dynamic Conversations: Unlike static text, these dialogues capture the iterative nature of human reasoning, where participants ask questions, clarify doubts, and build upon each other’s ideas.
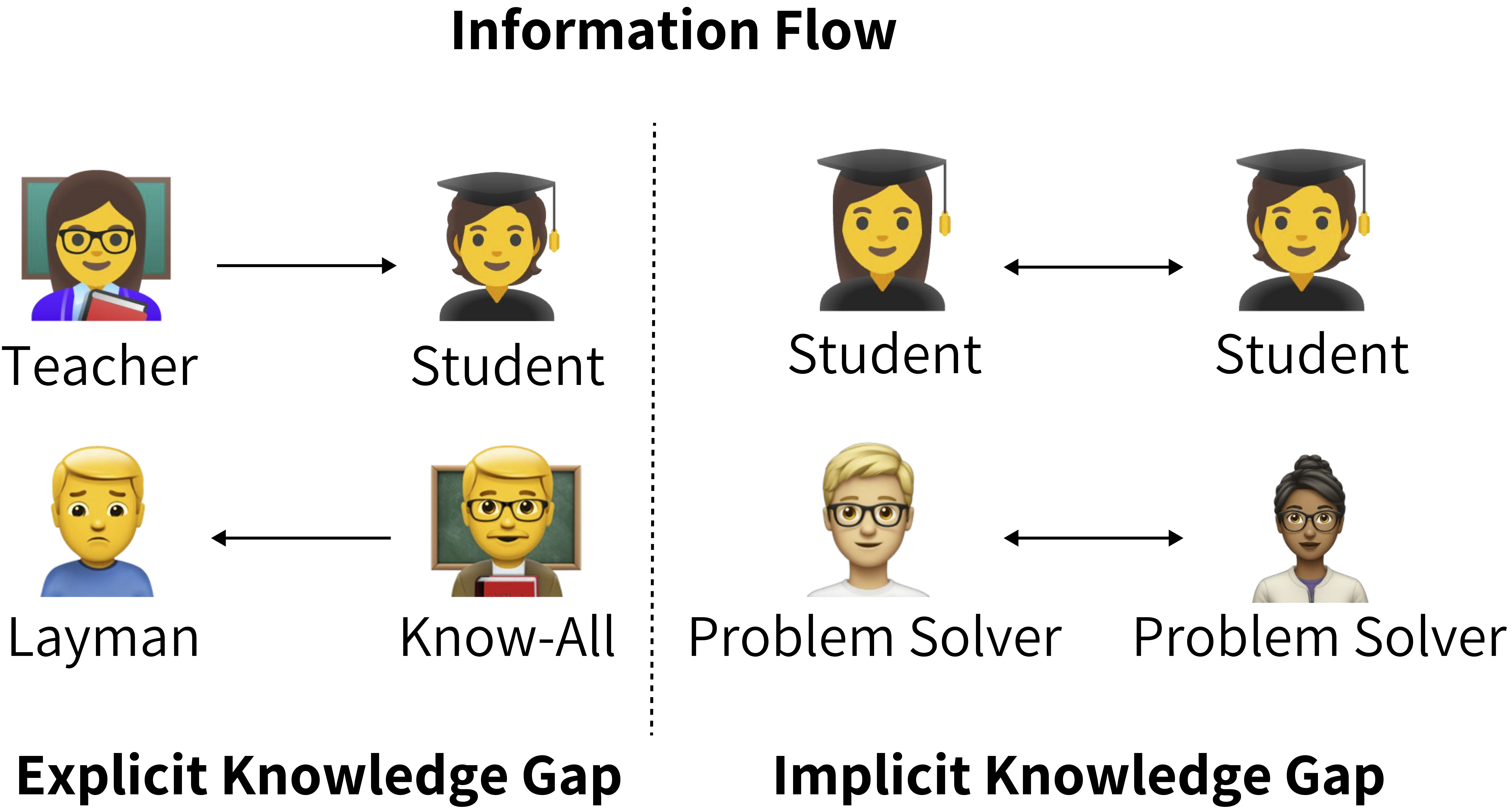
- Knowledge Imbalance: By designing conversations between participants with different levels of understanding, the dialogues naturally incorporate explanations and justifications, enhancing the model’s reasoning capabilities.
- Scalable Generation: Leveraging an open-source LLM, Nemotron-MIND can generate diverse conversational styles, ensuring a wide coverage of mathematical concepts and problem types.
Why Nemotron-MIND Matters?
- Efficiency: A 7B model pretrained on just seven conversational data generated using 4B tokens of raw data outperforms a counterpart trained on 14B tokens of raw data (Figure 1), showcasing the power of structured dialogues.
- Accuracy Gains: Significant improvements observed across benchmarks:
- GSM8K: +13.42%
- MATH: +2.30%
- MMLU: +4.55%
- General Reasoning Tasks: +2.51% (Average of 10 diverse reasoning tasks)
- Data Quality Over Quantity: The results underscore that the structure and quality of training data can be more impactful than sheer volume.
- Potential for Infinite Data: Nemotron-MIND enables the continuous generation of synthetic data from a single document by employing infinite conversational styles—effectively transforming finite raw data into an infinite source of high-quality structured supervision without human annotation.
How Does Nemotron-MIND Work?
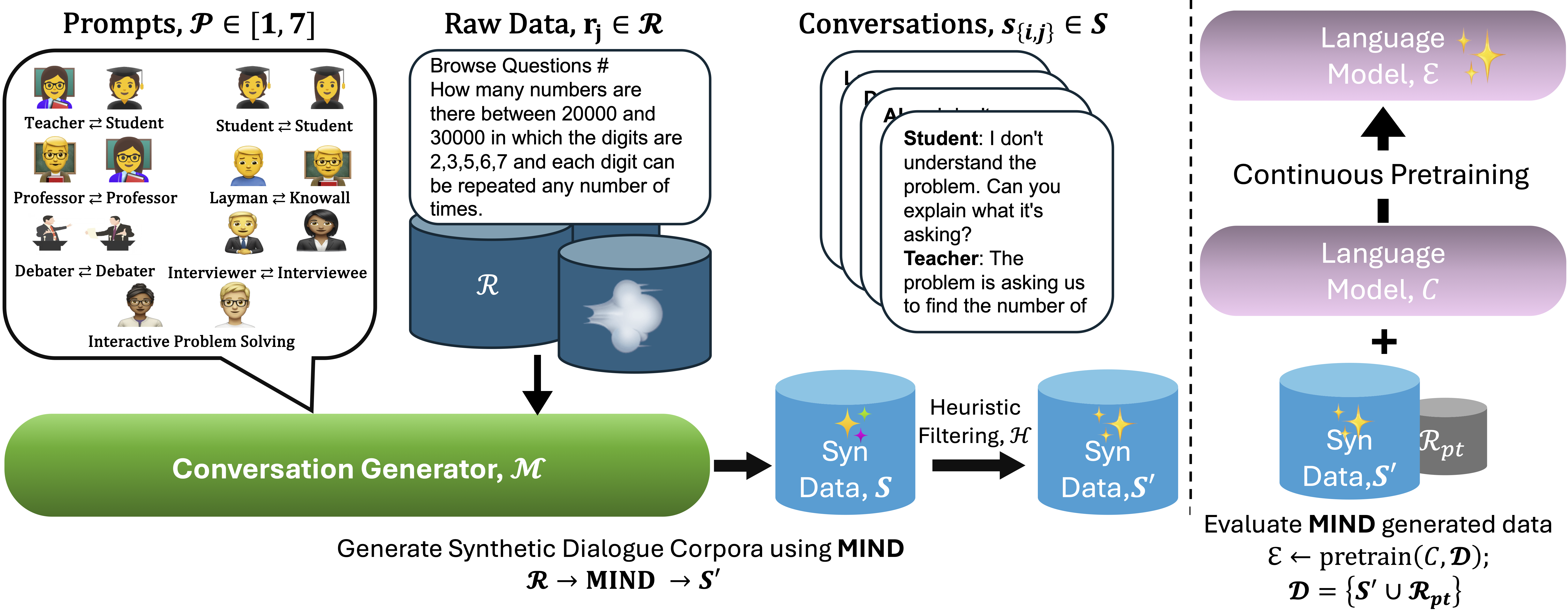
Figure 2: Math Informed syNthetic Dialogue. We (a) manually design prompts of seven conversational styles, (b) provide the prompt along with raw context as input to an LLM to obtain diverse synthetic conversations, (c) apply heuristic filtering to refine the generated data and (d) observe the downstream task accuracy after continuously pretraining a 7B LLM.
- Compose Diverse Prompts: We design seven prompt templates to guide a pretrained LLM in converting a single math text into a structured conversation. They represent different social conversational settings like: (1) Debate, (2) Problem-Solving, (3) Layman-Knowall, (4) Teacher-Student, (5) Two-Professors, (6) Two-Students, and (7) Interview-Interviewee.
- Raw Data: We use OpenWebMath (OWM) as our base corpus—14.7B tokens of rich, raw math content.
- Generate Conversations at Scale: For each document $r_j$ , we apply a prompt $p_i$ to create conversation:
\(s_{i,j} = \mathcal{M}(p_i \parallel r_j) \quad \text{where } R = \{r_1, \dots, r_j\},\; P = \{p_1, \dots, p_i\}\)
We use the LLama3 70B Instruct model to generate the conversations. - Filter Noisy Outputs: LLM-based scoring proved too lenient. Instead, we apply heuristic rules to remove low-quality generations and retain only coherent, detailed discussions.
- Continue Pretraining with Conversational Data: We continuously pretrain a 7B model on a mix of filtered conversations and raw pretraining data.
Potential of Nemotron-MIND
To understand the real value of Nemotron-MIND, we compared models trained on:
- Raw math data
- Rephrased data (from prior work)
- Synthetic conversations generated via seven distinct prompt styles
- A blended “Longest Conversation” variant combining the longest conversations for each raw text
- Finally, combination of all conversation styles called “All Conversations”
Figure 3: Results of 7B LLM pretrained on Diverse Conversational Styles. Continuous training with different conversation styles improves all reasoning tasks.
🔥 Key Takeaways:
- Every Nemotron-MIND conversation style beat both raw and rephrased baselines on reasoning tasks.
- Gains on GSM8K ranged from +4.78% to +12.82%—showcasing huge improvements in math problem solving. MATH (+0.54–1.28%) and MMLU-STEM (+0.79–4.28%) also saw consistent gains. Even general reasoning benchmarks improved by up to +2% on average across 10 tasks.
- The best results among 4B tokens came from the Longest Conversation variant—suggesting that richer, more elaborate dialogue drives stronger reasoning ability.
Why does Nemotron-MIND work so well? Unlike rephrasing, which just shuffles surface syntax, Nemotron-MIND injects structure, depth, and explanation—mirroring how humans actually reason through problems. This not only adds semantic diversity, but also fosters chain-of-thought style thinking that LLMs can learn from.
➣ Does the Prompt Style matter?
| Dataset | Style | GSM8K | MATH | MMLU-STEM | MMLU | GENERAL REASONING (Avg) | Avg-All |
|---|---|---|---|---|---|---|---|
| OWM-4B | Raw | 12.96 | 4.92 | 39.39 | 45.91 | 52.90 | 29.17 |
| MIND-OWM-4B | TWO PROFESSORS | 13.50 | 4.52 | 37.93 | 45.25 | 53.21 | 29.12 |
Figure 4: Two Professors prompt style vs Raw data. Continuous pretraining with Two Professors conversations does not provide gain over raw data compared to other conversational styles.
Not all conversation styles contribute equally—our findings show that explicit knowledge gaps (e.g., Learner-Knowledgeable, Teacher-Student) lead to richer, more explanatory dialogues that boost general reasoning ability for tasks like MMLU. Conversely, the Two Professors style, where both participants are equally knowledgeable, underperforms due to shallow discussion and minimal explanation. Interestingly, implicit knowledge gaps—where both participants are non-experts (e.g., Problem Solvering, Debate)—drive strong gains in math tasks, as the participants collaboratively reason through problems to bridge their shared uncertainty. These results highlight that dynamic, gap-driven dialogue—whether explicit or implicit—is key to improving LLM reasoning.
➣ Scaling Nemotron-MIND: Data Size and Quality
Figure 5: (a) MIND achieves consistent gain with more data (b) Model trained with MIND generated conversation surpasses the model trained with raw data even when the raw data comes from high-quality sources.
Our experiments reveal that Nemotron-MIND continues to scale effectively—even when applied to the full 14B-token OWM corpus, conversational data outperforms both raw and large-scale math-pretraining baselines across reasoning tasks. To minimize cost, we used a single prompt style (Two Students), yet still saw strong gains in math, specialized knowledge, and general reasoning. Crucially, Nemotron-MIND also proves effective on high-quality corpora like MathPile, which includes structured sources such as ArXiv and textbooks. Despite MathPile’s strong baseline, Nemotron-MIND conversations yield up to +3.95% absolute improvement on GSM8K, showing that structured dialogue not only scales with data size but also amplifies quality—even outperforming raw pretraining on expert-authored sources.
➣ Does the improvement persist with smaller 𝓜?
Figure 6: Results of 7B LLM trained on MIND-OWM-4B using 𝓜 of different sizes. Regardless of the sizes of 𝓜, model trained on MIND-OWM-4B outperforms the one trained with raw data.
Even when using a smaller generation model (𝓜 = LLaMA3-8B-Instruct), Nemotron-MIND still delivers strong gains in both mathematical and general reasoning—outperforming raw and rephrased data. This shows that the improvements aren’t just due to distillation from a larger LLM, but stem from the structured, step-by-step nature of the conversations themselves. Nemotron-MIND offers a more effective and scalable distillation strategy than existing methods, enabling reasoning improvements regardless of generation model size.
Conclusion
We introduce Nemotron-MIND, a scalable method to generate structured conversational data that significantly improves the mathematical and general reasoning abilities of open-source LLMs. Models pretrained on Nemotron-MIND-generated data outperform those trained on raw or rephrased corpora, achieving up to +6.29% gains while using 3.6× less data. These gains persist across model sizes, data scales, and domains—proving that structured dialogue, not just data volume, drives reasoning improvements. Nemotron-MIND offers a lightweight, model-agnostic strategy for enhancing LLMs in low-resource or domain-specific settings, setting a new direction for data-centric pretraining.
Citation
@inproceedings{
akter2025mind,
title={{MIND}}: Math Informed syNthetic Dialogues for Pretraining {LLM}s},
author={Syeda Nahida Akter and Shrimai Prabhumoye and John Kamalu and Sanjeev Satheesh and Eric Nyberg and Mostofa Patwary and Mohammad Shoeybi and Bryan Catanzaro},
booktitle={The Thirteenth International Conference on Learning Representations},
year={2025},
url={https://openreview.net/forum?id=TuOTSAiHDn}
}
-
We release the conversations generated from Nemotron4-340B-Instruct model. ↩