
AceMath: Advancing Frontier Math Reasoning with Post-Training and Reward Modeling
Published:
Paper Model weights and Training data 🤗 Benchmark 🤗
Author: Zihan Liu*, Yang Chen*, Mohammad Shoeybi, Bryan Catanzaro, Wei Ping
* Equal contribution
Posted: Wei Ping
Overview
We introduce AceMath, a family of frontier math reasoning models that set new state-of-the-art accuracy on math reasoning benchmarks. AceMath outperforms both leading open-access models (e.g., Qwen2.5-Math-72B-Instruct) and proprietary models (e.g., GPT-4o (2024-08-06) and Claude 3.5 Sonnet (2024-10-22)).
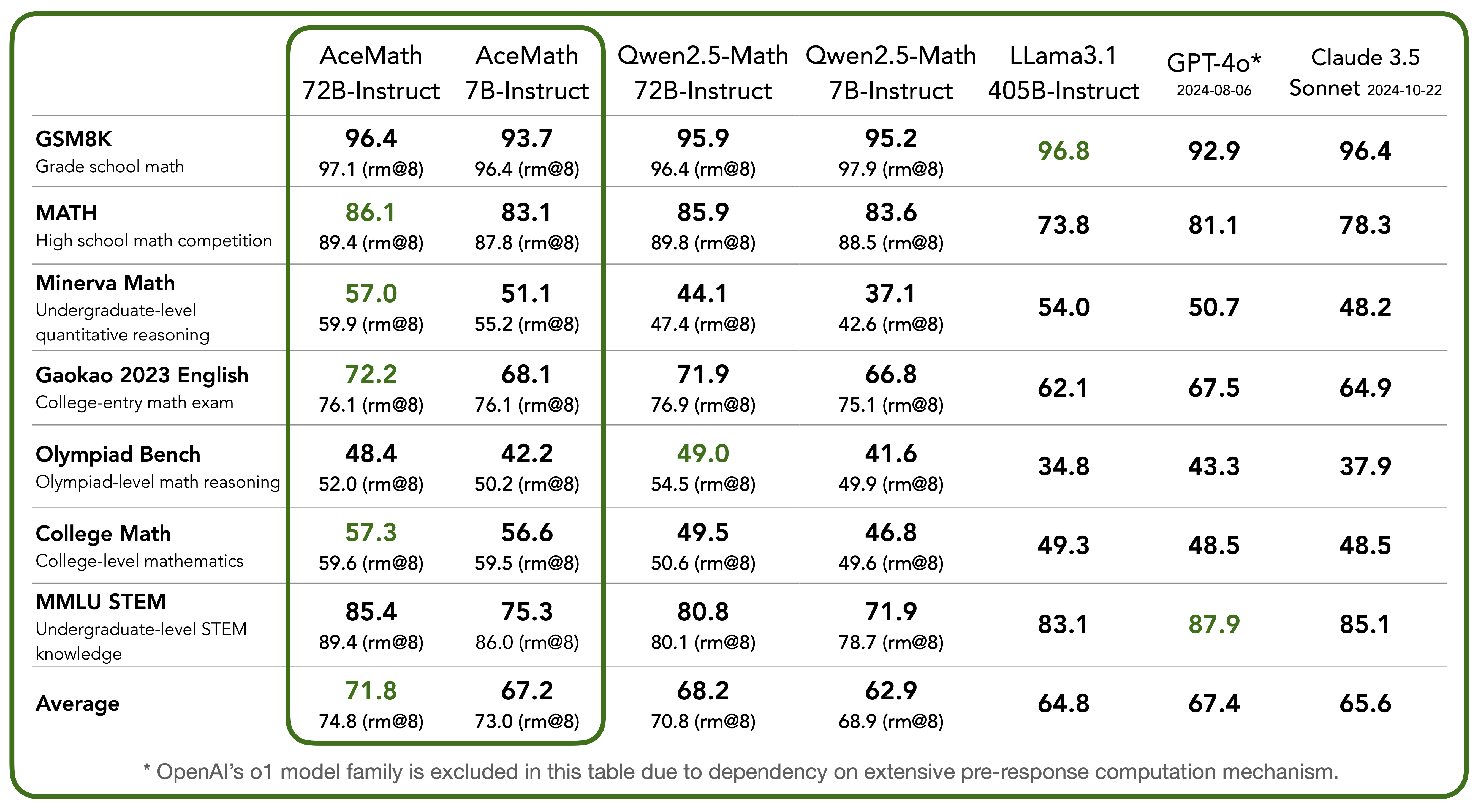
We compare AceMath to leading proprietary and open-access math models in above Table. Our AceMath-7B-Instruct, largely outperforms the previous best-in-class Qwen2.5-Math-7B-Instruct (Average pass@1: 67.2 vs. 62.9) on a variety of math reasoning benchmarks (detailed results in Figure 1), while coming close to the performance of 10× larger Qwen2.5-Math-72B-Instruct (67.2 vs. 68.2). Notably, our AceMath-72B-Instruct outperforms the state-of-the-art Qwen2.5-Math-72B-Instruct (71.8 vs. 68.2), GPT-4o (67.4) and Claude 3.5 Sonnet (65.6) by a margin. We also report the rm@8 accuracy (best of 8) achieved by our reward model, AceMath-72B-RM, which sets a new record on these reasoning benchmarks. This excludes OpenAI’s o1 model, which relies on scaled inference computation.
Technical highlights
Here are the key technical highlights of our work:
- We introduce a SFT process designed to first achieve competitive performance across general domains, including multidisciplinary topics, coding, and math. Building on this, the general SFT model is further fine-tuned in math domain using a meticulously curated set of prompts and synthetically generated responses.
- We conducted a systematic investigation of training techniques for building math-specialized reward models, focusing on key aspects such as the construction of positive-negative pairs, training objectives, and the elimination of stylistic biases from specific LLMs.
- We will open source the model weights for AceMath-Instruct and AceMath-RM, along with the complete training data used across all stages of their development.
- We also release AceMath-RewardBench, a comprehensive benchmark for evaluating math reward models, offering diverse datasets, varying difficulty levels, and robustness to variations in response styles.
Qualitative Study
We provide some qualitative samples in the following.




Citation
@article{acemath2024,
title={AceMath: Advancing Frontier Math Reasoning with Post-Training and Reward Modeling},
author={Liu, Zihan and Chen, Yang and Shoeybi, Mohammad and Catanzaro, Bryan and Ping, Wei},
journal={arXiv preprint},
year={2024}
}