
Nemotron-CORTEXA: Enhancing LLM Agents for Software Engineering Tasks via Improved Localization and Solution Diversity
Published:
Author: Atefeh Sohrabizadeh *, Jialin Song *, Mingjie Liu, Rajarshi Roy, Chankyu Lee, Jonathan Raiman, Bryan Catanzaro
[Paper] [Code]
Figure 1: Nemotron-CORTEXA achieves a new state-of-the-art resolution rate on SWE-Bench Verified.
LLM-powered software engineering agents hold great promise in increasing developer efficiency by automating everyday tasks. SWE-bench is the most popular benchmark for evaluating software engineering agents’ effectiveness at resolving real-world Github issues in Python. Existing approaches have made rapid progress on this benchmark. On the SWE-bench Verified set, the best system in March 2024 obtained a resolution rate of only 22.40% and the state-of-the-art system reaches over 65% in April 2025. However, core challenges remain. We’ve developed Nemotron-CORTEXA (Code Optimization for Repository Tasks with EXecution Agents), a software engineering agent to tackle two such challenges: accurately locating the source of the issues and generating more accurate repairs. Nemotron-CORTEXA resolves 68.2% of the issues from the SWE-bench Verified set, while only consuming $3.28 in LLM inference calls per problem, achieving a new state-of-the-art in resolution rate, surpassing OpenAI’s o3-based agent (66%)1. The cost efficiency of Nemotron-CORTEXA places it among the best in leading systems on SWE-bench. For instance, CodeMonkeys costs about $4.6 per problem2 and CodeStory’s approach costs about $20 per problem3.
Nemotron-CORTEXA Overview
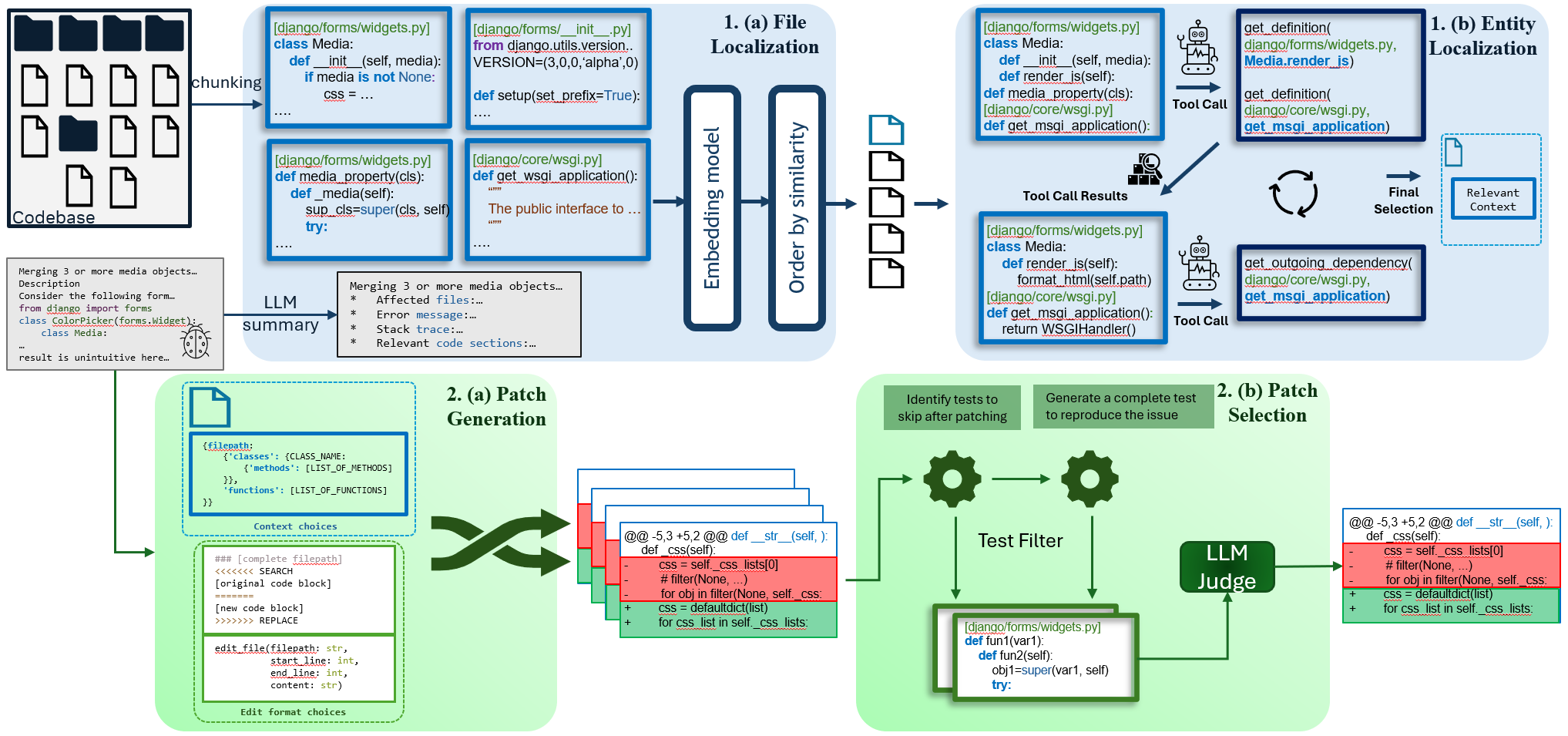
Figure 2: Overview of Nemotron-CORTEXA’s Architecture detailing the two-stages: (1a, 1b) localization of the issue, and (2a, 2b) generating repairs.
Nemotron-CORTEXA takes an issue description and the code from a software repository as an input and proceeds to resolve issues in two stages: (1) localization and (2) repair, as shown in Figure 2. The first stage, localization, can be broken down into two steps: first, identifying the most relevant files and then refining the granularity of the retrieval to focus on specific functions, classes, or methods. During the second stage, repair, we combine different source code contexts and prompt formats to produce a diverse set of LLM generated patches. The patches are then filtered using existing tests and new LLM-generated tests to narrow the list of candidate patches. Finally, an LLM selects a single patch for validation.
File Localization with Code Embedding Model
Accurately localizing the issue to the relevant files is essential for the success of the pipeline. Attaching the right source documents or snippets from a larger collection to a user query to improve a language model’s answer is the focus of a well studied task named Retrieval Augmented Generation (RAG). Unfortunately, present approaches to RAG and their associated pretrained embedding models are not exposed to cases where an issue description is given and the appropriate location in the source code that is responsible must be retrieved. To address this, we train a code embedding model on this setting using examples of source code files that must be repaired along with the text from the associated issue description. We fine-tune an existing text-based embedding model NV-EmbedQA-Mistral-7B-v2. Our training data is built using issues in the SWE-bench training set, and we augment it with retrieval tasks from publicly available code understanding datasets (APPS, CoSQA, Text2SQL, CodeTransOcean, and StackoverflowQA). We compare the retrieval accuracy of our embedding model with the string matching based retrieval and the direct prompting approach used by Agentless, and find that our finetuned model, NV-EmbedCode-v1, achieves 31.28% higher recall than BM25 and 6.4% higher recall than Agentless at identifying the relevant files (Table 1). It also increases the recall by 9.14% compared to using the base model, demonstrating the effectiveness of finetuning. We make our new code embedding model available as a NIM here: NV-EmbedCode-7B-v1.
| Method | Model/Approach | File Recall Accuracy |
|---|---|---|
| Lexical | BM25 | 40.67% |
| Prompt (Agentless) | GPT-4o | 65.55% |
| Embedding | NV-EmbedQA-v2 | 62.81% |
| NV-EmbedCode-v1 | 71.95% |
Table 1: Comparison of retrieval methods on retrieving the correct issue source file. Using our task-aware new code embedding model, NV-EmbedCode-v1, we see increased recall relative to BM25, LLM prompting GPT-4o (Agentless), and NV-EmbedQA-v2.
Entity Localization with Localization Agent
Despite narrowing the number of files that are relevant to an issue using the code embedding model, we still find that further reduction is necessary to ensure the retrieved code fits within a language model’s context window. We note that source code provides a natural way to be broken down into sub-units for filtering by considering each file’s high-level entities, such as class and function definitions. We take advantage of this affordance to filter within the top-ranked files the candidate entities to include in the context. We perform this candidate entity filtering using a language model-based localization agent. We provide a graph representation of a software repository to enable code navigation. Nodes in this graph represent code files and entities – functions, classes, and class methods – extracted using the Abstract Syntax Tree (AST). We store in each node the text from the corresponding entity’s code and position metadata. We define two types of directed edges in the graph: contain and use. Contain edges indicate hierarchical relationships between files and their functions and classes, and between classes and their methods. Use edges capture functional dependencies for each entity by adding edges when a function or class is invoked by another function. The agent iteratively traverses the graph using navigation steps such as definition look ups and tracing call stacks. Our graph representation provides the localization agent with a compact structural view of the repository, while not requiring us to provide the full repository into the context window. We compare the accuracy of Nemotron-CORTEXA’s structure-augmented localization agent to Agentless’s hierarchical prompting based localization approach in Table 2 and find that our approach increases both precision and recall.
| Method | Entity Retrieval Accuracy | |
|---|---|---|
| Precision | Recall | |
| Agentless | 17.54% | 58.37% |
| Nemotron-CORTEXA | 34.51% | 67.62% |
Table 2: Comparison of Agentless and Nemotron-CORTEXA’s entity retrieval accuracy on SWE-Bench Verified. Nemotron-CORTEXA increases both precision and recall relative to Agentless. We cannot compare with other agents due to their lack of a separate entity localization step.
Diverse Patch Generation
After selecting entities that are relevant to the issue, the next step for Nemotron-CORTEXA is to generate code patches to resolve the issue. In this step, the LLM is prompted to generate a patch based on the provided code context. We prompt LLMs to produce just edits to the entities rather than regenerating the entire code. We observe that the choice of context, edit format, and exact prompt have a significant and issue-specific impact on the correctness of the generated patches. Indeed, we observe that LLMs are highly sensitive to the format of the requested edits, yielding different solutions when changing only the patch format, while keeping all other factors constant. As a result, each prompting methodology leads to a varied set of resolved instances. Concretely in our work we generate 7 patches per problem instance with the o3 model from OpenAI. It is prompted using two edit formats: search/replace and edit_file (Figure 3). The context for each prompt is varied by varying the included entities from the file and entity retrieval step.

Figure 3: Nemotron-CORTEXA prompts LLMs to generate code edits using two formats: search/replace (left) and edit_file (right).
Patch Selection
The final step in Nemotron-CORTEXA’s repair procedure is to select a single patch among those produced by the patch generation step. We identify the most promising patch for our final solution by applying a series of filters. As an initial filter we remove candidates that have invalid edit instructions or result in syntax errors. Candidates that pass the first criteria are normalized by removing comments, doc-strings, and empty lines, and standardizing variable, function, and class names. Using these normalized versions, we record the frequency of the repeated solutions. We then run regression tests and LLM-generated reproduction tests on each candidate to remove those that fail these tests. Finally, we use majority voting on the remaining solutions based on their repetition frequency to select the final patch. Our approach closely follows the methodology outlined in Agentless and leverages directly their released artifacts for regression tests. We generated our own reproduction tests that covered more problem instances and were of higher quality. As there are often ties in frequency when we reach the majority voting step, we use LLM-as-a-judge for the final selection. We used o3 and o3-mini as judges and obtained a final resolution rate of 68.2%.
Conclusion
Nemotron-CORTEXA demonstrates that improved localization and diverse solutions are effective avenues to enhance LLM software agents for real-world tasks. In our experiments we observe that the 7 candidate patches contain correct repairs in 75% of problems, while scaling the number of generated patches could further increase this number. Selecting among those patches remains a challenge, especially as the candidate set grows. Thus enhancing the patch selection step to miss fewer numbers of correct patches is a promising approach to further increasing the resolution rate. We will release a technical paper with additional details along with the code at a later date.
-
OpenAI’s reported performance of 69.1% is based on 477 instances of the Verified set, which corresponds to overall accuracy of 66% across the full set of 500 instances. ↩