
Nemotron-H: A Family of Accurate, Efficient Hybrid Mamba-Transformer Models
Published:
We introduce the Nemotron-H family of models, including a series of 8B models (Nemotron-H-8B-Base, Nemotron-H-8B-Instruct, Nemotron-H-8B-VLM), and a series of 47-56B models (Nemotron-H-47B-Base, Nemotron-H-56B-Base, Nemotron-H-56B-VLM).
Nemotron-H was designed to improve intelligence at the same inference cost compared to other models. The advent of reasoning and advanced RL training is making models much more useful and widely applicable, changing our goals compared to prior LLM pre-training efforts. Inference efficiency is now a fundamental constraint on overall model intelligence. Therefore, improving inference efficiency is our top goal for the Nemotron-H architecture.
We believe the Nemotron-H models present an exciting development for the community in the following ways:
- Nemotron-H is a series of hybrid Mamba-Transformer models which offer either better or on-par accuracy and improved inference speed (up to 3x) compared to other similarly-sized state-of-the-art open-sourced pure Transformer models (e.g., Qwen-2.5-7B/72B and Llama-3.1-8B/70B).
- We pre-trained Nemotron-H-56B-Base on 20 trillion tokens in FP8 using per-tensor scaling. We believe this is one of the bigger (in terms of both model size and number of training tokens) public demonstrations of FP8 pre-training.
- In order to support inference over a ~1-million-token context (in FP4 precision) on a commodity NVIDIA RTX 5090 GPU, we compressed Nemotron-H-56B-Base to obtain a 47B model. Nemotron-H-47B-Base has similar accuracies to the original model. Model distillation was performed using only 63 billion training tokens in FP8 precision.
- Nemotron-H has been used as the backbone for Cosmos-Reason 1, a very strong VLM for physical AI.
- We trained Nemotron-H-56B-Base efficiently on 6144 H100 NVIDIA GPUs, leveraging NVRx and DGX Cloud Resilience service for at-scale fault tolerance.
We have released Nemotron-H base model checkpoints in Hugging Face and NeMo formats on the Hugging Face and NGC model repositories:
- Nemotron-H-56B-Base. Hugging Face and NGC.
- Nemotron-H-47B-Base. Hugging Face and NGC.
- Nemotron-H-8B-Base. Hugging Face and NGC.
Higher Accuracy and Improved Inference Speed
As inference-time scaling becomes critical for improved reasoning capabilities, it is increasingly important to build models that are efficient to inference. Consequently, we opted for a hybrid Mamba-Transformer architecture for Nemotron-H. Transformers have long been the state-of-the-art LLM architecture, but their self-attention layers suffer from both linearly increasing memory and computation (from attending over the entire sequence stored in the KV cache) when generating tokens. Hybrid models help to alleviate this drawback by replacing the majority of self-attention layers with Mamba layers that exhibit constant memory and computation during the generation phase of inference. For more details and comparisons between hybrid and Transformer models, please see our earlier paper “An Empirical Study of Mamba-based Language Models”.
47B/56B Models
Nemotron-H-56B-Base was pre-trained on 20 trillion tokens and consists of 54 Mamba-2, 54 MLP, and 10 Self-Attention layers. It is the first Nemotron model to be fully pre-trained using FP8 precision. Nemotron-H-47B-Base was distilled from Nemotron-H-56B-Base; we discuss the exact distillation procedure we used later in this blogpost. These models are competitive with state-of-the-art ~70B dense Transformer models (Qwen-2.5-72B-Base, Llama-3.1-70B-Base), and are even comparable to much larger models (DeepSeek-V3-671B-Base, Llama-3.1-405B-Base). Accuracy results are shown in Table 1. We measure accuracy for all models using the same evaluation setup unless specified otherwise.
| Task | Nemotron-H-56B-Base | Nemotron-H-47B-Base | Qwen-2.5-72B-Base | Llama-3.1-70B-Base | DeepSeek-V3-671B-Base | Llama-3.1-405B-Base |
|---|---|---|---|---|---|---|
| General | ||||||
| MMLU-Pro (5-shot COT) | 60.5 | 61.8 | 58.8 | 51.3 | 64.4 | 52.8 |
| MMLU (5-shot) | 84.2 | 83.6 | 86.1 | 78.8 | 87.1 | 84.4 |
| Math | ||||||
| GSM8k (8-shot COT) | 93.7 | 93.3 | 90.9 | 83.9 | 89.3 | 83.5 |
| MATH (4-shot COT) | 59.4 | 57.4 | 64.6 | 42.9 | 61.6 | 49.0 |
| Math Level 5 (4-shot COT) | 35.2 | 34.1 | 41.2 | 21.1 | ||
| MMLU STEM (5-shot) | 80.6 | 79.8 | 84.9 | 70.5 | ||
| Code | ||||||
| HumanEval (0-shot greedy pass@1) | 60.4 | 61.0 | 56.7 | 57.3 | 65.2 | 54.9 |
| HumanEval+ (0-shot greedy pass@1) | 54.3 | 56.1 | 50.0 | 52.4 | ||
| MBPP sanitized (3-shot greedy pass@1) | 77.8 | 75.9 | 78.2 | 70.0 | 75.4 | 68.4 |
| MBPP+ (0-shot greedy pass@1) | 67.2 | 65.6 | 71.7 | 66.9 | ||
| Commonsense Understanding | ||||||
| Arc-Challenge (25-shot) | 95.0 | 94.6 | 95.8 | 93.0 | 95.3 | 95.3 |
| Hellaswag (10-shot) | 89.0 | 87.9 | 87.6 | 88.1 | 88.9 | 89.2 |
| Winogrande (5-shot) | 84.5 | 83.9 | 84.4 | 85.6 | 84.9 | 85.2 |
| PIQA (0-shot) | 85.0 | 83.9 | 83.6 | 84.1 | 84.7 | 85.9 |
| OpenbookQA (0-shot) | 48.6 | 48.8 | 46.2 | 47.6 | ||
| Long-Thought Reasoning | ||||||
| MATH (R1-style 4-shot COT) | 87.8 | 73.9 | 38.7 | |||
| MATH Level 5 (R1-style 4-shot COT) | 74.8 | 53.2 | 16.7 | |||
Table 1. Accuracy of Nemotron-H-56B/47B-Base versus existing SoTA models. Numbers in italics are from the DeepSeek-V3 report, all other numbers are run by us. We bold the highest accuracy in each row, excluding publicly-reported numbers.
Due to the reduction in self-attention layers, Nemotron-H-56B/47B provide inference-time speedups compared to the other models in Table 1 above. On longer contexts (65536 input sequence length, 1024 output tokens) with NVIDIA H100 GPUs, we measure a 2.9x speedup for the 47B compared to Qwen-2.5-72B and Llama-3.1-70B, and 23.5x speedup (normalized by the number of GPUs used) compared to Llama-3.1-405B (Figure 1). We use an initial Megatron-LM implementation for Nemotron-H inference and vLLM v0.7.3 for baselines; we expect further optimizing Nemotron-H inference to lead to additional speedups. In these experiments, we try to maximize per-GPU inference throughput by using as large a batch size as possible.
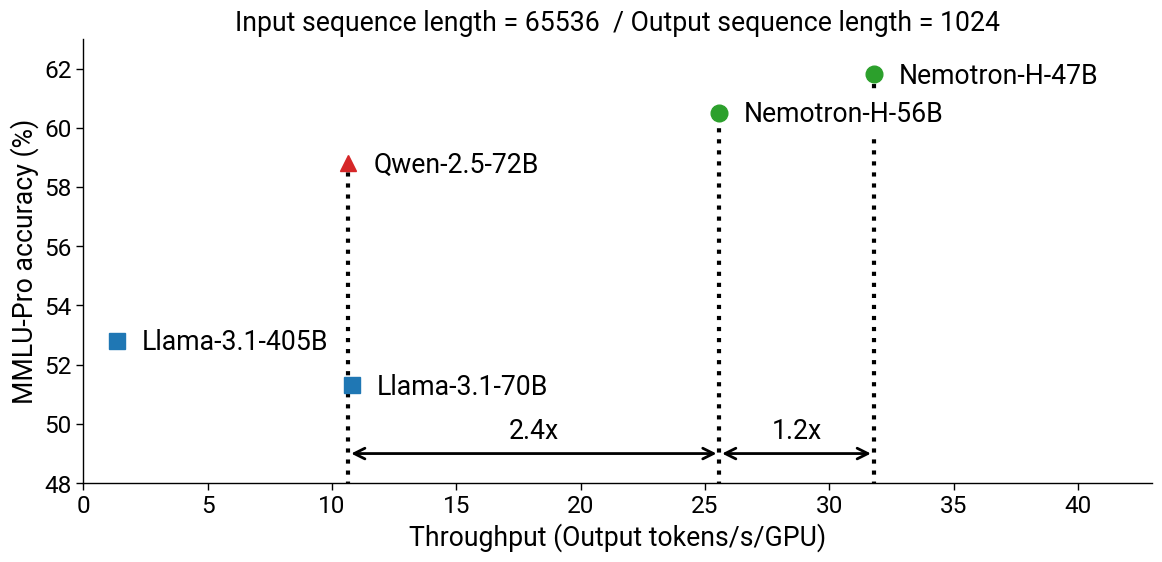 Figure 1. MMLU-Pro accuracy versus inference throughput for Nemotron-H-56B/47B-Base compared to existing similarly-sized Transformer models (Llama-3.1-70B/405B, Qwen-2.5-72B).
Figure 1. MMLU-Pro accuracy versus inference throughput for Nemotron-H-56B/47B-Base compared to existing similarly-sized Transformer models (Llama-3.1-70B/405B, Qwen-2.5-72B).
We also develop a 56B vision-language model based on the 56B text-only backbone. Our approach follows the architecture design and training methodology of the NVLM-D model. The model consists of a vision encoder, followed by a two-layer MLP, which then connects to the Nemotron-H backbone. Training is conducted in two stages, employing a training recipe similar to that of the NVLM model. We conduct a direct, like-for-like comparison with the best-in-class Qwen2.5-72B-instruct backbone. We also compare it with the previous state-of-the-art NVLM-1.0 model. The results demonstrate that the Nemotron-H-56B-based VLM delivers state-of-the-art accuracies on various vision-language benchmarks, rivaling top-tier models. Nemotron-H-56B has also been further trained to yield a very strong VLM for physical AI in the Cosmos-Reason 1 project.
| LLM Backbone | MMMU-Val | ChartQA | AI2D | OCRBench | TextQA | RealWorldQA | MathVista | DocVQA |
|---|---|---|---|---|---|---|---|---|
| NVLM-1.0-72B | 59.7 | 86.0 | 94.2 | 853 | 82.1 | 69.7 | 65.2 | 92.6 |
| Qwen-2.5-72B-Instruct | 65.1 | 88.9 | 94.9 | 869 | 83.5 | 71.4 | 70.5 | 92.0 |
| Nemotron-H-56B | 63.6 | 89.4 | 94.7 | 862 | 81.1 | 68.4 | 70.7 | 93.2 |
Table 2. VLM accuracies using Nemotron-H-56B and Qwen-2.5-72B as the LLM backbone, compared to NVLM-1.0.
8B Models
Nemotron-H-8B-Base was pre-trained on 15 trillion tokens and consists of 24 Mamba-2, 24 MLP, and 4 self-attention layers. Accuracy results with comparisons to similarly-sized SoTA models are shown in Table 3.
We also compare Nemotron-H-8B-Base with Nemotron-T-8B-Base, a standard Transformer model trained on exactly the same data. This comparison provides the largest (in terms of token horizon) apples-to-apples comparison of a hybrid and Transformer model to date (15T tokens), confirming results from prior work that show hybrid models can reach equal or higher accuracy compared to Transformer models at larger scales.
| Task | Nemotron-H-8B-Base | Nemotron-T-8B-Base | Qwen-2.5-7B-Base | Llama-3.1-8B-Base | Gemma-3-12B-Base |
|---|---|---|---|---|---|
| General | |||||
| MMLU-Pro (5-shot COT) | 44.0 | 41.4 | 48.3 | 35.9 | 45.3 |
| MMLU (5-shot) | 72.8 | 73.2 | 74.2 | 65.3 | 74.5 |
| Math | |||||
| GSM8k (8-shot COT) | 87.1 | 89.0 | 83.3 | 55.5 | 74.1 |
| MATH (4-shot COT) | 46.5 | 46.7 | 49.8 | 19.5 | 42.1 |
| Math Level 5 (4-shot COT) | 22.9 | 25.8 | 24.6 | 5.6 | 17.5 |
| MMLU STEM (5-shot) | 65.4 | 65.6 | 71.2 | 56.3 | |
| Code | |||||
| HumanEval (0-shot greedy pass@1) | 58.5 | 59.8 | 56.7 | 37.8 | 46.3 |
| HumanEval+ (0-shot greedy pass@1) | 55.5 | 53.0 | 48.8 | 31.7 | 34.1 |
| MBPP sanitized (3-shot greedy pass@1) | 65.4 | 63.4 | 69.3 | 57.2 | 64.6 |
| MBPP+ (0-shot greedy pass@1) | 59.5 | 61.4 | 65.3 | 51.6 | 59.0 |
| Commonsense Understanding | |||||
| Arc-Challenge (25-shot) | 88.7 | 88.3 | 89.2 | 80.4 | |
| Hellaswag (10-shot) | 83.2 | 82.5 | 80.3 | 82.3 | 84.2 |
| Winogrande (5-shot) | 80.5 | 78.8 | 76.1 | 78.1 | 74.3 |
| PIQA (0-shot) | 82.2 | 82.0 | 80.1 | 81.0 | 81.8 |
| OpenbookQA (0-shot) | 47.2 | 44.8 | 47.0 | 45.4 | |
Table 3. Accuracy of Nemotron-H-8B-Base versus existing models and a Transformer model (Nemotron-T-8B-Base) trained on the same data. Numbers in italics are from publicly reported results, all other numbers are run by us. We bold the highest accuracy in each row, excluding publicly-reported numbers.
Similar to the larger models, Nemotron-H-8B-Base is also faster to infer than corresponding Transformer models. As shown in Figure 2, on longer contexts (65536 input sequence length, 1024 output tokens), we measure a 1.8x and 3x speedup compared to Qwen-2.5-7B and Llama-3.1-8B, respectively. We use the same experimental setup as with Figure 1; Nemotron-H numbers are produced using our initial Megatron-LM implementation and baseline numbers are produced using vLLM v0.7.3.
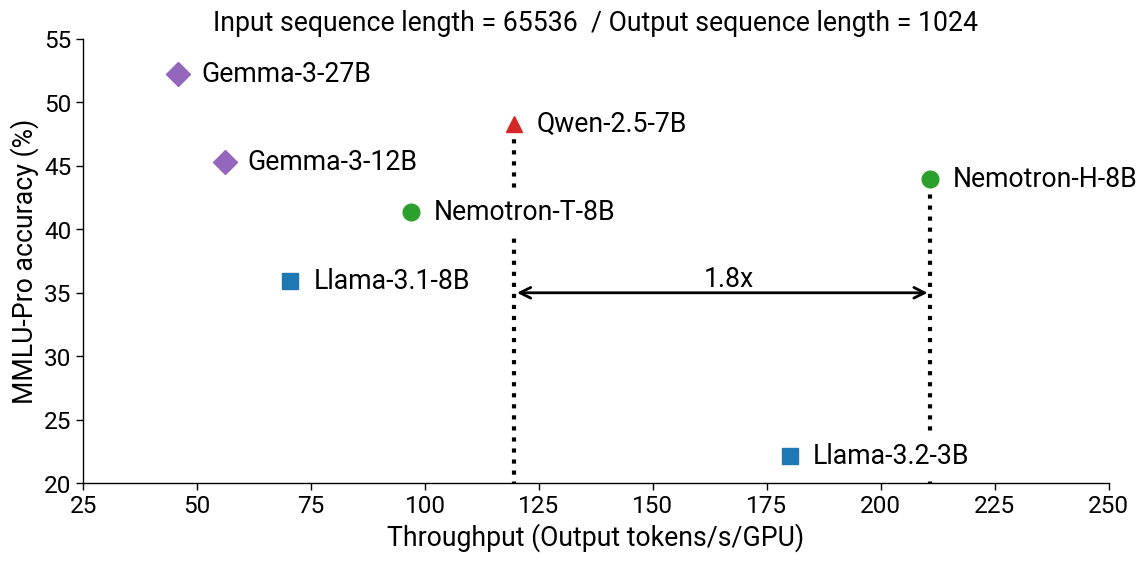 Figure 2. MMLU-Pro accuracy versus inference throughput for Nemotron-H-8B-Base compared to existing similarly-sized Transformer models.
Figure 2. MMLU-Pro accuracy versus inference throughput for Nemotron-H-8B-Base compared to existing similarly-sized Transformer models.
Nemotron-H-8B-Instruct is post-trained on top of Nemotron-H-8B-Base using two rounds of SFT (Supervised Fine-Tuning) and three rounds of offline RPO (Reward-aware Preference Optimization). SFT round 1 focuses on math / coding and SFT round 2 uses a more general chat dataset. Our RPO blend is similar to what was used for Nemotron-4-340B, with more on-policy and safety-related data added in later RPO rounds. We also find it effective to increase the weights and rewards of examples that teach the model to strictly follow instructions in later training stages; this has little to no negative impact on the model’s general capabilities. Evaluation results can be found in Table 4.
| LLM | MT-Bench | MMLU (gen) | MBPP | MBPP+ | HumanEval | HumanEval+ | GSM8k | Math500 | IfEval (prompt) | IfEval (instr.) | BFCL | AVG (excl. MT-Bench) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Qwen-2.5-7B-Instruct | 8.0 | 70.9 | 79.9 | 67.5 | 82.3 | 75.6 | 89.8 | 76.4 | 72.6 | 80.2 | 61.1 | 75.6 |
| Llama-3.1-8B-Instruct | 7.5 | 63.1 | 75.1 | 61.9 | 69.5 | 64.0 | 81.6 | 47.8 | 73.2 | 81.2 | 38.9 | 65.6 |
| Nemotron-H-8B-Instruct | 7.9 | 68.7 | 81.0 | 67.7 | 79.3 | 74.4 | 90.4 | 77.6 | 74.7 | 82.5 | 62.6 | 75.9 |
Table 4. Accuracy comparison of Nemotron-H-8B-Instruct with Qwen2.5-8B-Instruct and Llama-3.1-8B-Insruct.
To ensure good long-context capabilities up to 128k tokens, we extend our SFT and RPO blends by concatenating samples up to 512k tokens, adding synthetic inter-sample dependencies, and re-running SFT / RPO. We use the RULER benchmark to evaluate the long-context capabilities of the resulting checkpoints. The RULER results exceed those of LLama3.1-8B-Instruct, and are close to Qwen2.5-7B-Instruct, both of which are Transformer-based (Table 5).
| LLM | RULER 16k | RULER 32k | RULER 64k | RULER 128k |
|---|---|---|---|---|
| Qwen-2.5-7B-Instruct | 93.0 | 91.1 | 90.4 | 84.4 |
| Llama-3.1-8B-Instruct | 91.6 | 87.4 | 84.7 | 77.0 |
| Nemotron-H-8B-Instruct | 91.5 | 89.8 | 87.5 | 81.7 |
Table 5. RULER accuracies for Nemotron-H-8B-Instruct compared with Qwen2.5-8B-Instruct and Llama-3.1-8B-Instruct at different context lengths (16k-128k).
We also use Nemotron-H-8B as an LLM backbone to train vision-language models (VLMs), utilizing the same training recipe as with the 56B model. The results indicate that the Nemotron-H-8B-based VLM achieves accuracies on par with other best-in-class models like Llama-3.1-8B and Qwen-2.5-7B on various vision-language benchmarks, demonstrating its effectiveness as a strong LLM backbone for building vision-language models.
| LLM Backbone | MMMU-Val | ChartQA | AI2D | OCRBench | TextQA | RealWorldQA | MathVista | DocVQA |
|---|---|---|---|---|---|---|---|---|
| Qwen-2.5-7B-Instruct | 51.1 | 84.9 | 91.0 | 836 | 76.1 | 60.6 | 63.8 | 91.2 |
| Llama-3.1-8B-Instruct | 44.8 | 85.4 | 90.9 | 847 | 76.4 | 60.9 | 61.7 | 91.3 |
| Nemotron-H-8B | 51.3 | 84.8 | 89.6 | 840 | 76.2 | 62.2 | 62.5 | 90.6 |
Table 6. VLM accuracies using Nemotron-H-8B, Llama-3.1-8B, and Qwen-2.5-7B as the LLM backbone.
End-to-End FP8 Pre-training
Nemotron-H-56B-Base was pre-trained with operations performed in FP8. Specifically, all forward pass GEMMs are run in E4M3 and backward pass ones in E5M2 (see “FP8 Formats for Deep Learning”). Our recipe, called per-tensor current scaling, is coarse grained and involves quantizing entire tensors using a single scaling factor. This factor is chosen to preserve the largest value in the given tensor; any value too small to fit in the desired FP8 format is flushed to zero. In addition, we find it important for training stability and convergence to leave the first and last 4 GEMMs of the network in BF16.
Downstream evaluations are either unchanged or improved as a result of our recipe. We used both FP8 and BF16 for smaller models, and observed the relative difference between loss curves is less than 0.1% when using the same token horizon and dataset (Figure 3).
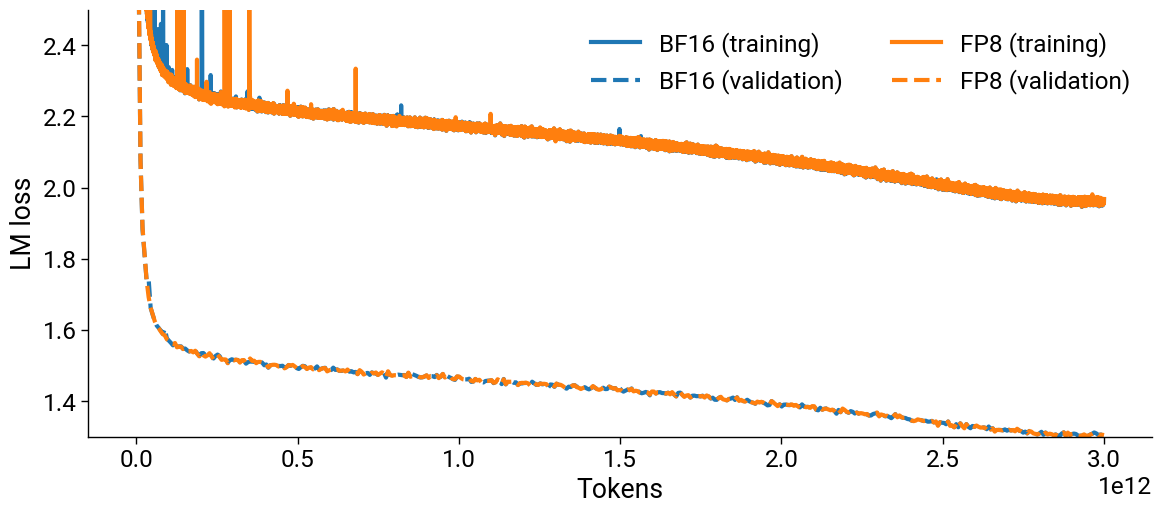
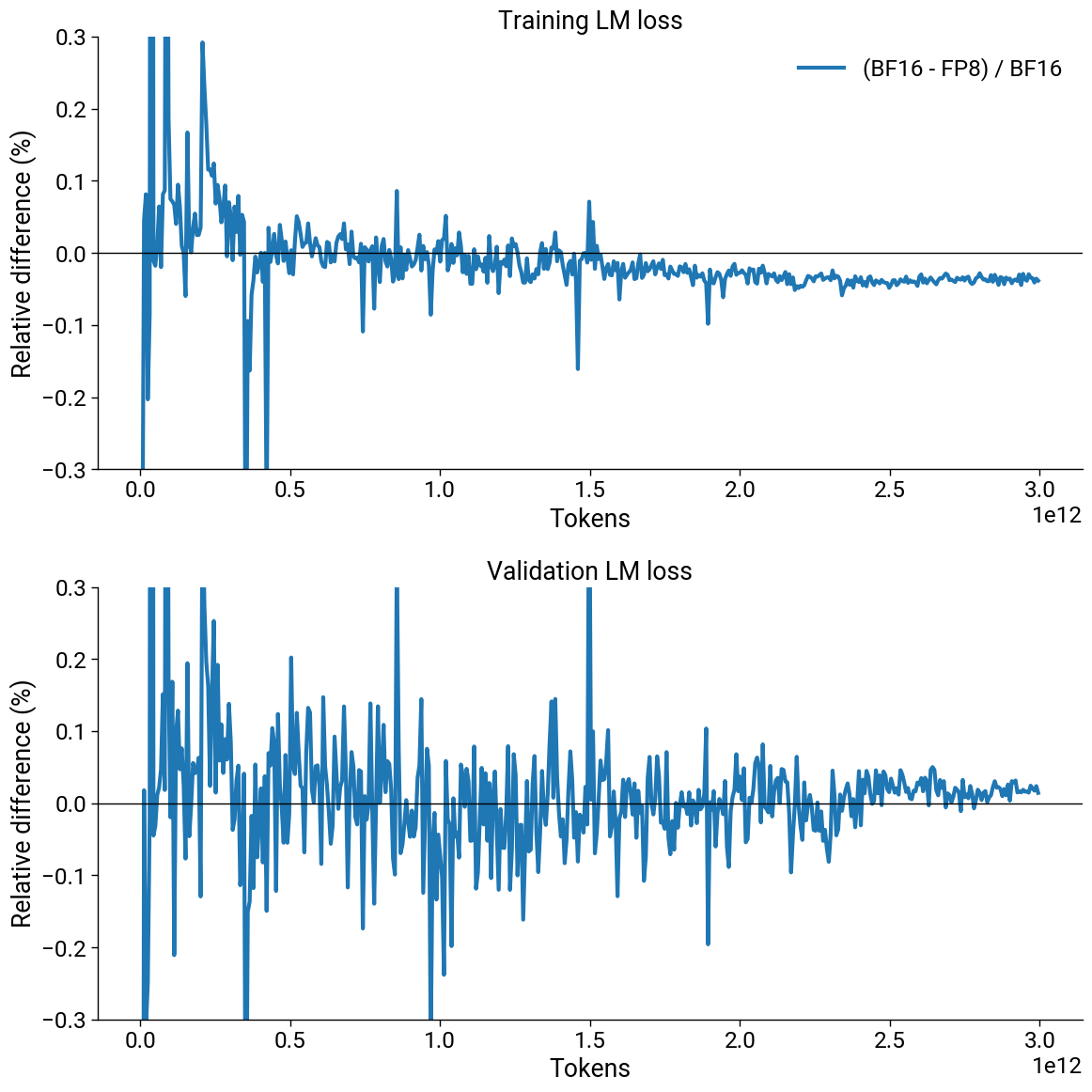 Figure 3. Plots showing the LM loss curves for 8B models trained on 3T tokens with BF16 and mixed-precision FP8. The top plot shows the loss curves, and the bottom one shows the relative difference between them. Both FP8 and BF16 runs were performed with the same token horizons and datasets.
Figure 3. Plots showing the LM loss curves for 8B models trained on 3T tokens with BF16 and mixed-precision FP8. The top plot shows the loss curves, and the bottom one shows the relative difference between them. Both FP8 and BF16 runs were performed with the same token horizons and datasets.
Efficient Pruning and Distillation
Efficient deployment of LLMs often requires tailoring the model architecture to specific constraints. For example, deploying Nemotron-H-56B in FP4 precision on a NVIDIA RTX 5090 GPU with 32 GB of memory is impractical since just the model weights would require roughly 31.6 GB, leaving only 0.4 GB for the KV cache and activation buffers (corresponding to a max context length of less than 1K tokens). In order to infer over a longer context on a RTX 5090 GPU, we require a smaller model. Training such a model from scratch, however, is expensive.
To tailor models for different deployment scenarios, we use the compression via pruning and distillation paradigm proposed in the Minitron and Puzzle frameworks. Both methods allow us to create targeted models without pre-training from scratch. We designed a new method called miniPuzzle that combines the simplicity of Minitron and the versatility of Puzzle. MiniPuzzle can be used to create smaller models satisfying specific memory, parameter count, or latency constraints from a larger model.
Using miniPuzzle, we distilled the Nemotron-H-56B-Base model to Nemotron-H-47B-Base to optimize memory usage and inference speed. Nemotron-H-47B-Base has half the self-attention layers compared to Nemotron-H-56B-Base (5 instead of 10) and enables 1.2x faster inference on long contexts (Figure 1), with minimal accuracy drop across tasks (Table 1). We can fit a context of about a million tokens in FP4 precision with Nemotron-H-47B-Base on a RTX 5090 GPU.
Resilience at Scale
When training models at scale over long periods of time, job failures and slowdowns are inevitable, leading to lost training productivity. Failures can occur due to GPU-related errors (e.g., uncorrectable ECC errors or GPUs falling off the bus), errors in shared infrastructure like the network fabric or Lustre, or application-induced failures (e.g., numerical instability in certain operations or “bad” data). We can also experience job slowdowns due to a variety of reasons (e.g., single-GPU throttling or slower communication collectives).
In light of this, our goal is to minimize downtime by a) accurately attributing failures to the correct infrastructure and application components to prevent repeated disruptions, b) reducing the recovery overhead of each failure.
We leverage the DGX Cloud Resilience service to ensure failures are correctly attributed and the appropriate hardware component (e.g., particular HGX node with failing GPU) is not included in the next instance of the training job, preventing repeated failures. With DGX Cloud Resilience enabled, we obtained a 3.3x improvement in mean time between failures (MTBF) in our cluster.
We proactively save checkpoints frequently in order to minimize the amount of work lost when a failure occurs (weight updates from the last checkpoint save to the failure are lost). We use NVRx to facilitate checkpointing with low overhead by asynchronously saving checkpoints without blocking training. We also optimized job restart times (that is, the set of operations needed by Megatron-LM before training iterations can start like initialization of distributed process groups and checkpoint loading).
All of these components allowed us to train Nemotron-H-56B-Base with high efficiency on 6144 NVIDIA H100 GPUs.
Model Release and Technical Report
We have released the base models described in this blogpost with support in Hugging Face and NeMo. The latter includes support for continued training and inference in FP8.
- Nemotron-H-56B-Base. Hugging Face and NGC.
- Nemotron-H-47B-Base. Hugging Face and NGC.
- Nemotron-H-8B-Base. Hugging Face and NGC.
Instruct and reasoning models are coming soon. More details are also available in our technical report.
Contributors
We thank the following people for their invaluable contributions to Nemotron-H.
- Data. Abhinav Khattar, Aleksander Ficek, Amala Sanjay Deshmukh, Andrew Tao, Ayush Dattagupta, Brandon Norick*, Chengyu Dong*, Dan Su*, Daria Gitman, Evelina Bakhturina, Igor Gitman, Ilia Karmanov, Ivan Moshkov, Jane Polak Scowcroft, Jarno Seppanen, Jiaxuan You, Jocelyn Huang, John Kamalu*, Joseph Jennings*, Jupinder Parmar*, Karan Sapra, Kateryna Chumachenko, Kezhi Kong*, Lukas Voegtle, Lindsey Pavao, Markus Kliegl*, Matvei Novikov, Mehrzad Samadi, Miguel Martinez, Mostofa Patwary*, Osvald Nitski, Philipp Fischer, Pritam Gundecha, Rabeeh Karimi, Sean Narenthiran, Sanjeev Satheesh*, Seungju Han, Shrimai Prabhumoye*, Shubham Pachori, Shubham Toshniwal, Siddhartha Jain, Somshubra Majumdar, Syeda Nahida Akter*, Timo Roman, Ushnish De, Vahid Noroozi, Vitaly Kurin, Wasi Uddin Ahmad, Wei Du, Yao Xu, Yejin Choi, Ying Lin*.
- FP8 Recipe. Carlo del Mundo, Dusan Stosic, Eric Chung, Jinze Xue, John Kamalu, Kirthi Sivamani, Mike Chrzanowski*, Mohammad Shoeybi, Mostofa Patwary, Oleg Rybakov*, Paulius Micikevicius, Peter Dykas*, Przemek Tredak, Zhongbo Zhu.
- Model Architecture. Brandon Norick*, Duncan Riach*, Roger Waleffe*, Wonmin Byeon*.
- Pre-training. Deepak Narayanan*, Hongbin Liu, Kunlun Li, Maciej Bala, Michael Andersch, Mikolaj Blaz, Oleg Rybakov, Peter Dykas, Roger Waleffe*, Sangkug Lym, Selvaraj Anandaraj, Seonmyeong Bak, Slawek Kierat, Szymon Migacz, Xiaowei Ren.
- Infrastructure. Aaron Blakeman, Aarti Basant, Ashwin Poojary, Brian Butterfield, Christine Harvey, Ding Ma, Dong Ahn, Gargi Prasad, Hui Li, Jason Sewall, Jing Zhang, Jining Huang, Kumar Anik, Maer Rodrigues de Melo, Mohamed Fawzy, Ning Xu, Pasha Shamis, Pierre-Yves Aquilanti, Rahul Kandu, Ruoxi Zhang, Sabrina Kavanaugh, Sergey Kashirsky, Shelby Thomas, Sirshak Das, Sriharsha Niverty, Stefania Alborghetti, Tal Shiri.
- Distillation. Akhiad Bercovich*, Ali Taghibakhshi*, Daniel Korzekwa, Elad Segal*, Izik Golan*, Marcin Chochowski*, Mostofa Patwary, Pavlo Molchanov*, Ran El-Yaniv, Raviraj Joshi, Roger Waleffe, Saurav Muralidharan*, Sharath Turuvekere Sreenivas*, Tomer Ronen*.
- VLM. Andrew Tao, Boxin Wang*, Danny Yin, Fuxiao Liu, Guilin Liu, Guo Chen, Jason Lu, Jon Barker, Lukas Voegtle, Matthieu Le, Mike Ranzinger, Nayeon Lee*, Philipp Fischer, Song Han, Tuomas Rintamaki, Tyler Poon, Wei Ping*, Wenliang Dai*, Zhiding Yu, Zhiqi Li, Zhuolin Yang*.
- Alignment and Long Context. Adithya Renduchintala*, Ali Taghibakhshi*, Ameya Sunil Mahabaleshwarkar, Dima Rekesh*, Ellie Evans, Fei Jia, Gerald Shen*, Haifeng Qian*, Jiaqi Zeng*, Makesh Narsimhan Sreedhar, Michael Evans, Olivier Delalleau*, Prasoon Varshney, Samuel Kriman*, Shantanu Acharya*, Soumye Singhal*, Tugrul Konuk*, Yian Zhang*, Yoshi Suhara*, Zijia Chen.
- Inference. Helen Ngo*, Keshav Santhanam*, Vijay Korthikanti*.
- Software Support. Adithya Renduchintala, Ali Taghibakhshi, Anna Shors, Ashwath Aithal, Balaram Buddharaju, Bobby Chen, Deepak Narayanan, Dmytro Pykhtar, Duncan Riach, Gerald Shen, Helen Ngo, Jared Casper, Jimmy Zhang, Keshav Santhanam, Lawrence McAfee, Luis Vega, Nima Tajbakhsh, Parth Chadha, Roger Waleffe, Sahil Jain, Terry Kong, Tyler Poon, Vijay Korthikanti, Yoshi Suhara, Zhiyu Li.
- Evaluations and Safety. Ameya Sunil Mahabaleshwarkar*, Christopher Parisien, David Mosallanezhad, Denys Fridman, Eileen Long, Erick Galinkin, Ewa Dobrowolska, Katherine Luna, Leon Derczynski, Marta Stepniewska-Dziubinska, Michael Evans, Roger Waleffe*, Sanjeev Satheesh*, Shaona Ghosh, Shrimai Prabhumoye, Suseella Panguluri, Syeda Nahida Akter, Varun Singh.
- Program Management. Joey Conway, Krzysztof Pawelec, Shyamala Prayaga, Swetha Bhendigeri, Trisha Saar.
- Leadership. Alexis Bjorlin, Andrew Tao*, Boris Ginsburg*, Bryan Catanzaro*, Eric Chung, Jan Kautz, Jonathan Cohen*, Kari Briski, Misha Smelyanskiy, Mohammad Shoeybi*, Mostofa Patwary*, Oleksii Kuchaiev*, Sharon Clay, Song Han, Timo Roman, Wei Ping*.
* Core contributor.