
BigVGAN: A Universal Neural Vocoder with Large-Scale Training
Published:
Author: Sang-gil Lee, Wei Ping, Boris Ginsburg, Bryan Catanzaro, Sungroh Yoon
Posted: Wei Ping
Overview
In our latest work, we present BigVGAN, a universal vocoder that generalizes well for various out-of-distribution scenarios without fine-tuning. Our BigVGAN obtains the state-of-the-art results for various zero-shot (out-of-distribution) conditions, including unseen speakers, languages, recording environments. More interestingly, the model is trained only on clean speech data but shows extraordinary zero-shot generalization ability for non-speech vocalizations (e.g., laughter, applaud), singing voices, music, instrumental audio that are even recorded in varied noisy environment!
The following are the key technical highlights of our work:
- We introduce periodic nonlinearities and anti-aliased representation into the generator, which brings the desired inductive bias for waveform synthesis and significantly improves audio quality.
- We train our GAN vocoder at the largest scale up to 112M parameters, which is unprecedented in the literature. In particular, we identify and address the training instabilities specific to such scale, while maintaining high-fidelity output without over-regularization.
This work is published at ICLR 2023. We release our code and model at: link.
Method
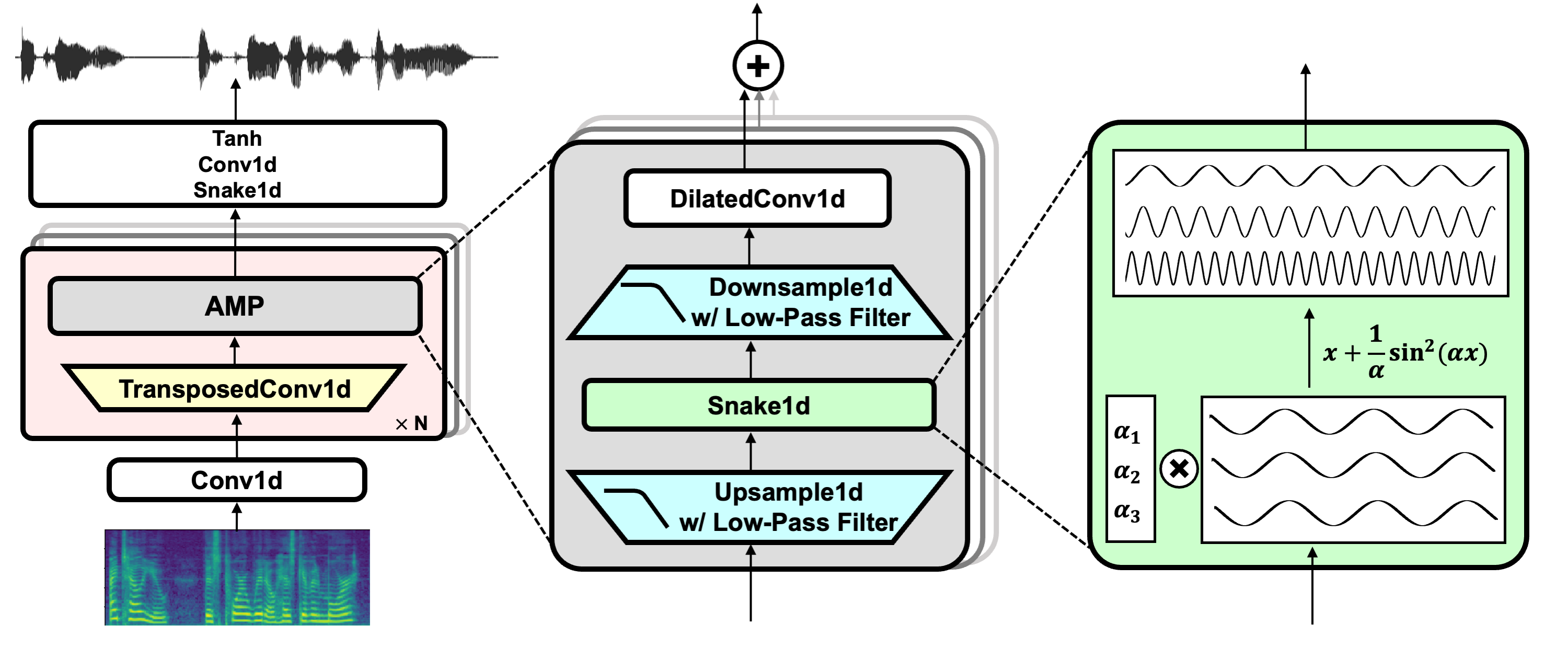
The following diagram illustrates BigVGAN’s generator architecture. It is composed of multiple blocks of transposed 1-D convolution followed by the proposed anti-aliased multi-periodicity composition (AMP) module. The AMP module adds features from multiple residual blocks with different channel-wise periodicities for different dilated 1-D convolutions. It applies Snake function for providing periodic inductive bias, and filtered nonlinearities for anti-aliasing purpose.
Output Visualization
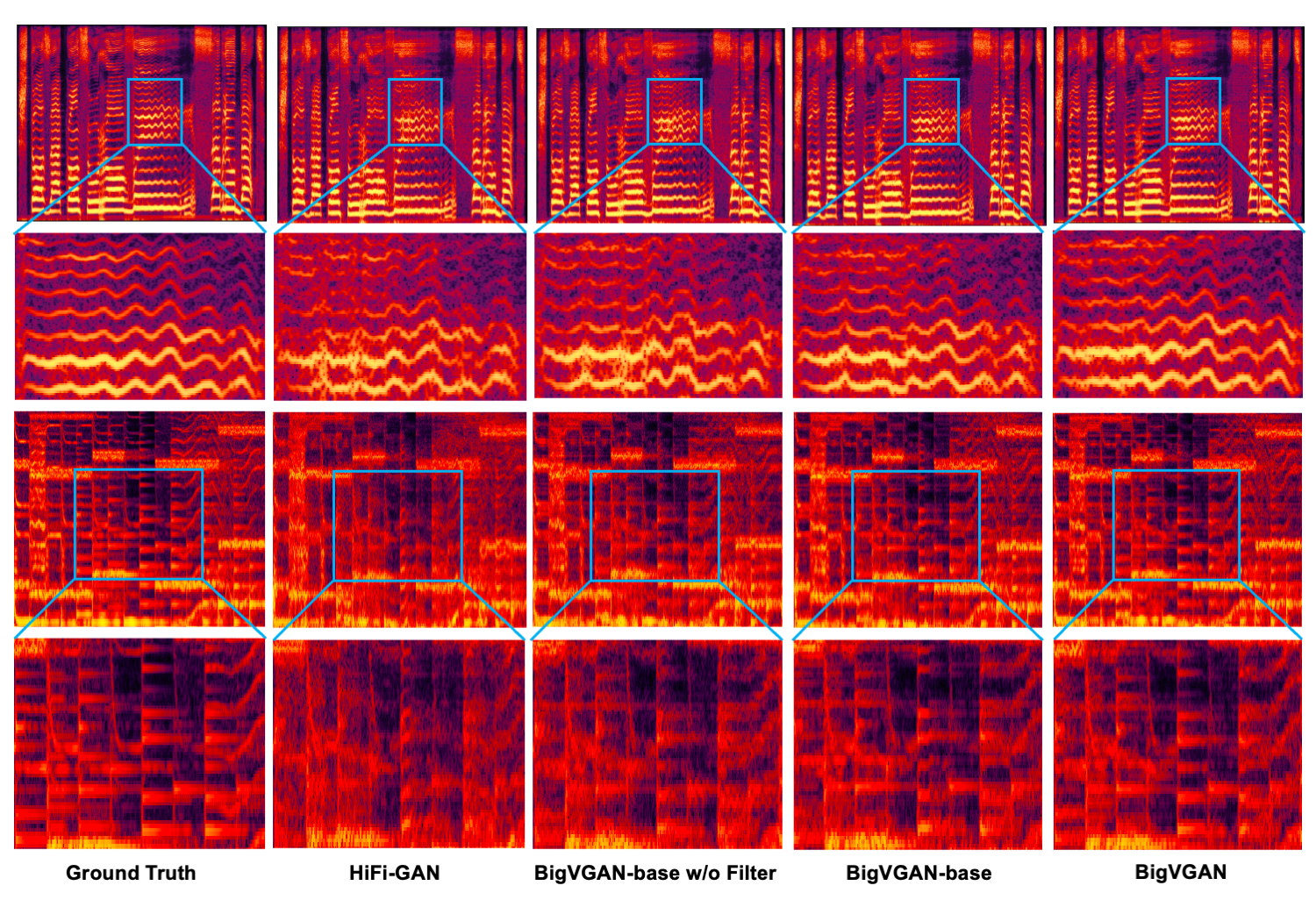
The image below demonstrates spectrogram visualization of BigVGAN output for out-of-distribution audio, with a zoomed-in view of high-frequency harmonic components. Top: a singing voice. Bottom: an instrumental audio.
Audio Samples
Out-of-distribution robustness: YouTube clips in-the-wild:
BigVGAN, trained only on LibriTTS, exhibits strong zero-shot performance and robustness to out-of-distribution scenarios. BigVGAN is capable of synthesizing non-speech vocalizations or audios, such as laughter, singing, and any types of in-the-wild audio from YouTube clips.
| Ground-Truth | HiFi-GAN (V1) | UnivNet-c32 (train-clean-360) |
|---|---|---|
| BigVGAN | BigVGAN-base |
|---|---|
Extreme out-of-distribution examples:
A robustness “stress test” of BigVGAN. BigVGAN is robust to extreme out-of-distribution samples, such as audio effects and electronic music with loud drums and complex synthesizers, which has not been possible in the literature.
| Ground-Truth | HiFi-GAN (V1) | UnivNet-c32 (train-clean-360) |
|---|---|---|
| BigVGAN | BigVGAN-base |
|---|---|
Out-of-distribution robustness: MUSDB18-HQ:
BigVGAN, trained only on LibriTTS, exhibits strong zero-shot performance and robustness to out-of-distribution scenarios. BigVGAN is capable of synthesizing a wide range of singing voice, music, and instrumental audio which are unseen during training.
| Types | Ground-Truth | HiFi-GAN (V1) | UnivNet-c32 (train-clean-360) |
|---|---|---|---|
| Others (Guitars) | |||
| Vocal | |||
| Drums | |||
| Bass | |||
| Mixture | |||
| Mixture |
| Types | BigVGAN | BigVGAN-base |
|---|---|---|
| Others (Guitars) | ||
| Vocal | ||
| Drums | ||
| Bass | ||
| Mixture | ||
| Mixture |
LibriTTS test-other samples from unseen speakers
| Ground-Truth | HiFi-GAN (V1) | UnivNet-c32 (train-clean-360) |
|---|---|---|
| BigVGAN | BigVGAN-base |
|---|---|
Unseen languages and recording environments
| Ground-Truth | HiFi-GAN (V1) | UnivNet-c32 (train-clean-360) |
|---|---|---|
| BigVGAN | BigVGAN-base |
|---|---|