
Fine Detailed Texture Learning for 3D Meshes with Generative Models
Published in arXiv, 2022
Recommended citation: Aysegul Dundar, Jun Gao, Andrew Tao, Bryan Catanzaro, Fine Detailed Texture Learning for 3D Meshes with Generative Models, arXiv:2203.09362, 2022. https://arxiv.org/abs/2203.09362
Abstract
This paper presents a method to reconstruct high-quality textured 3D models from both multi-view and single-view images. The reconstruction is posed as an adaptation problem and is done progressively where in the first stage, we focus on learning accurate geometry, whereas in the second stage, we focus on learning the texture with a generative adversarial network. In the generative learning pipeline, we propose two improvements. First, since the learned textures should be spatially aligned, we propose an attention mechanism that relies on the learnable positions of pixels. Secondly, since discriminator receives aligned texture maps, we augment its input with a learnable embedding which improves the feedback to the generator. We achieve significant improvements on multi-view sequences from Tripod dataset as well as on single-view image datasets Pascal3D and CUB. We demonstrate that our method achieves superior 3D textured models compared to the previous works.
Sample Results from Tripod Sequences
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
Method
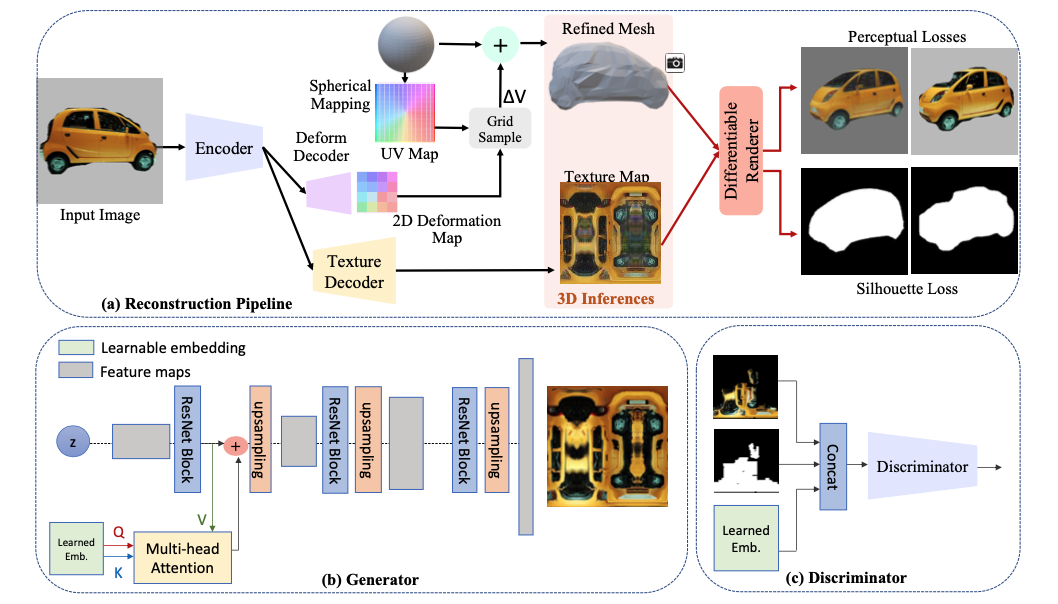
We follow a two step regime when learning high-quality textured 3D models. Below diagram shows these steps. (a) In the first step, reconstruction pipeline estimates convolutional mesh and texture representations. We reconstruct this car from a different view with a differentiable renderer. The perceptual loss is calculated between the reconstructed image and ground truth image and a silhouette loss is calculated between the rendered silhouette and ground-truth mask to train the networks. The camera parameters of the rendered image are optimized jointly which is removed from the Figure for brevity. Next we convert texture learning into 2D image synthesis task. The input images are projected onto the UV map of the predicted mesh template based on the optimized camera parameters of each image. We learn fine detailed textures from these projected texture maps with GAN pipeline. In GAN training pipeline, we propose two improvements. The improvements are tailored to the unique dataset set-up we have where images, texture maps, are spatially aligned for each sample. (b) Since the textures are always spatially aligned, in the Generator, we design an attention mechanism to learn which positions in the texture map should be considered together. (c) In the Discriminator, with the same intuition, we learn a positional embedding so that the patch discriminator specializes for different parts.
Our Results from CUB and P3d Experiments
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
Authors
 |
 |
 |
 |
Citation
@article{Dundar2022Fine,
author = {Aysegul Dundar and Jun Gao and Andrew Tao and Bryan Catanzaro},
title = {Fine Detailed Texture Learning for 3D Meshes with Generative Models},
journal = {arXiv preprint arXiv:2203.09362},
year = {2022},
}
Acknowledgements
Our training pipeline closely follows the training pipeline as described in Pavlo et. al.. We thank the authors of ConvMesh for releasing their source code.