
From 128K to 4M: Efficient Training of Ultra-Long Context Large Language Models
Published:
Nemotron-UltraLong
[Paper]
Llama-3.1-Nemotron-8B-UltraLong-1M-Instruct: [Checkpoints🤗]
Llama-3.1-Nemotron-8B-UltraLong-2M-Instruct: [Checkpoints🤗]
Llama-3.1-Nemotron-8B-UltraLong-4M-Instruct: [Checkpoints🤗]
Author: Chejian Xu, Wei Ping, Peng Xu, Zihan Liu, Boxin Wang, Mohammad Shoeybi, Bo Li, Bryan Catanzaro
Posted: Wei Ping
Overview
We introduce Nemotron-UltraLong-8B, a series of ultra-long context language models designed to process extensive sequences of text (up to 1M, 2M, and 4M tokens) while maintaining competitive performance on standard benchmarks.
-
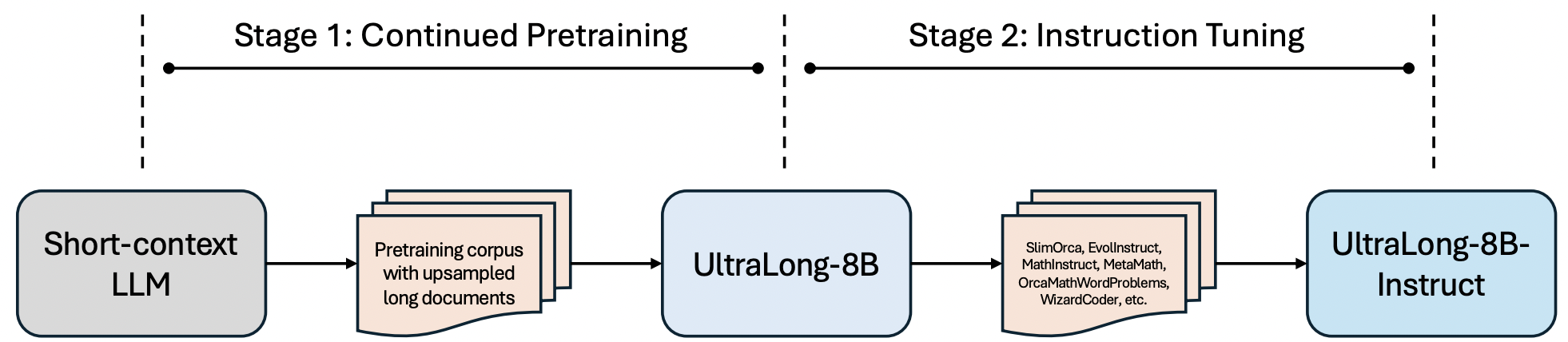
Continued Pretraining: we train Llama-3.1-8B-Instruct on only 1B tokens sourced from a pretraining corpus using per-domain upsampling based on the length of documents. The sequence length of training is 1M, 2M, and 4M, respectively. The idea is to quickly extend the context window during continued pretraining before catastrophic forgetting of the general capabilities.
-
Tricks used during continued pretraining include: i) separating individual documents with special tokens, and ii) disabling the cross-document attention mask, allowing the model to attend freely across the entire input sequence. These strategies facilitate faster adaptation to the YaRN-based RoPE extension.
-
Instruction tuning: The models are only trained on short-context SFT samples. We kept the SFT steps (with short-context data) to a minimum to ensure the newly acquired long-context capabilities would not degrade, while quickly restroring the general capabilities. The 1M, 2M, 4M models are trained with 480 steps, 140 steps, and 150 steps, respectively.
Needle In A Haystack
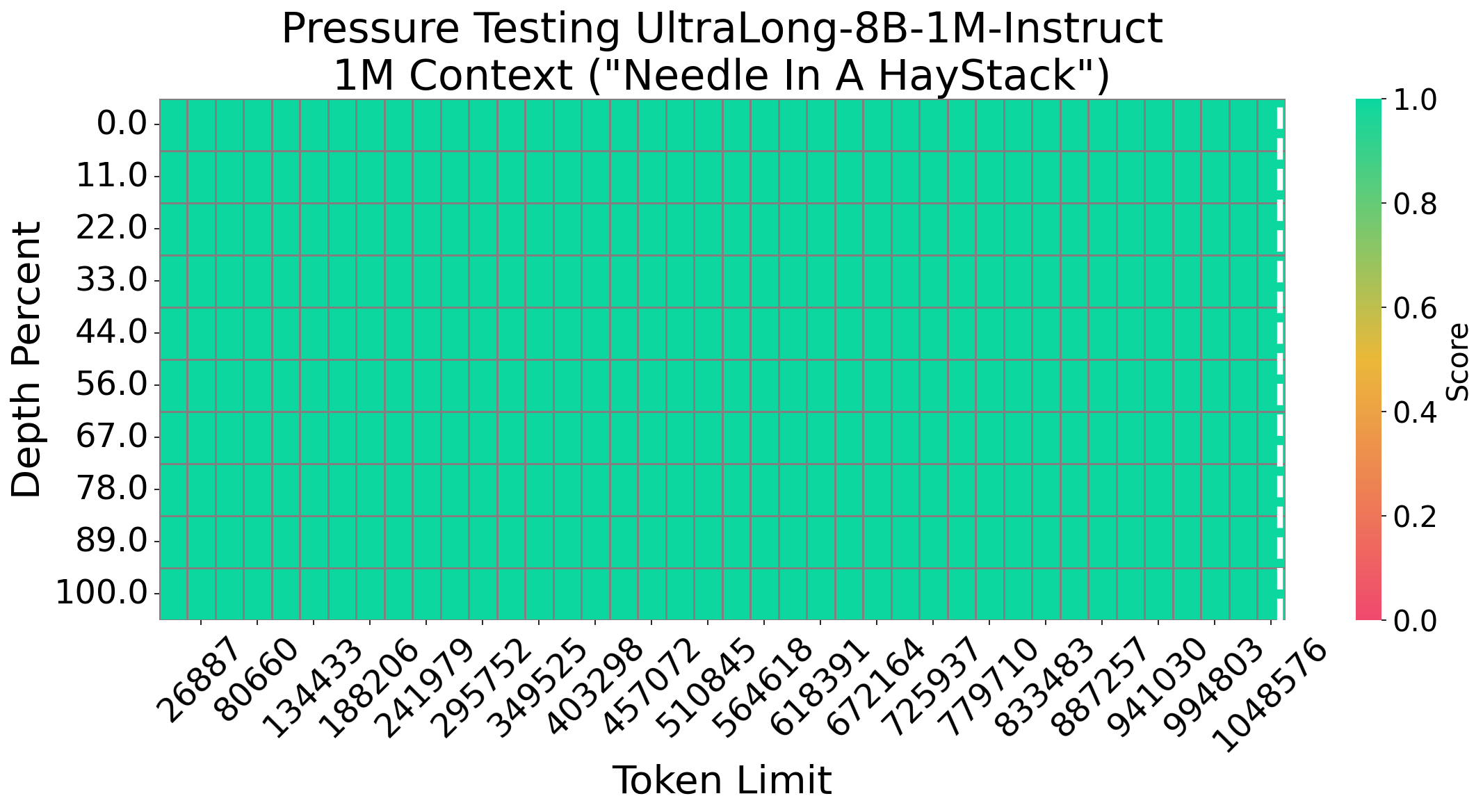
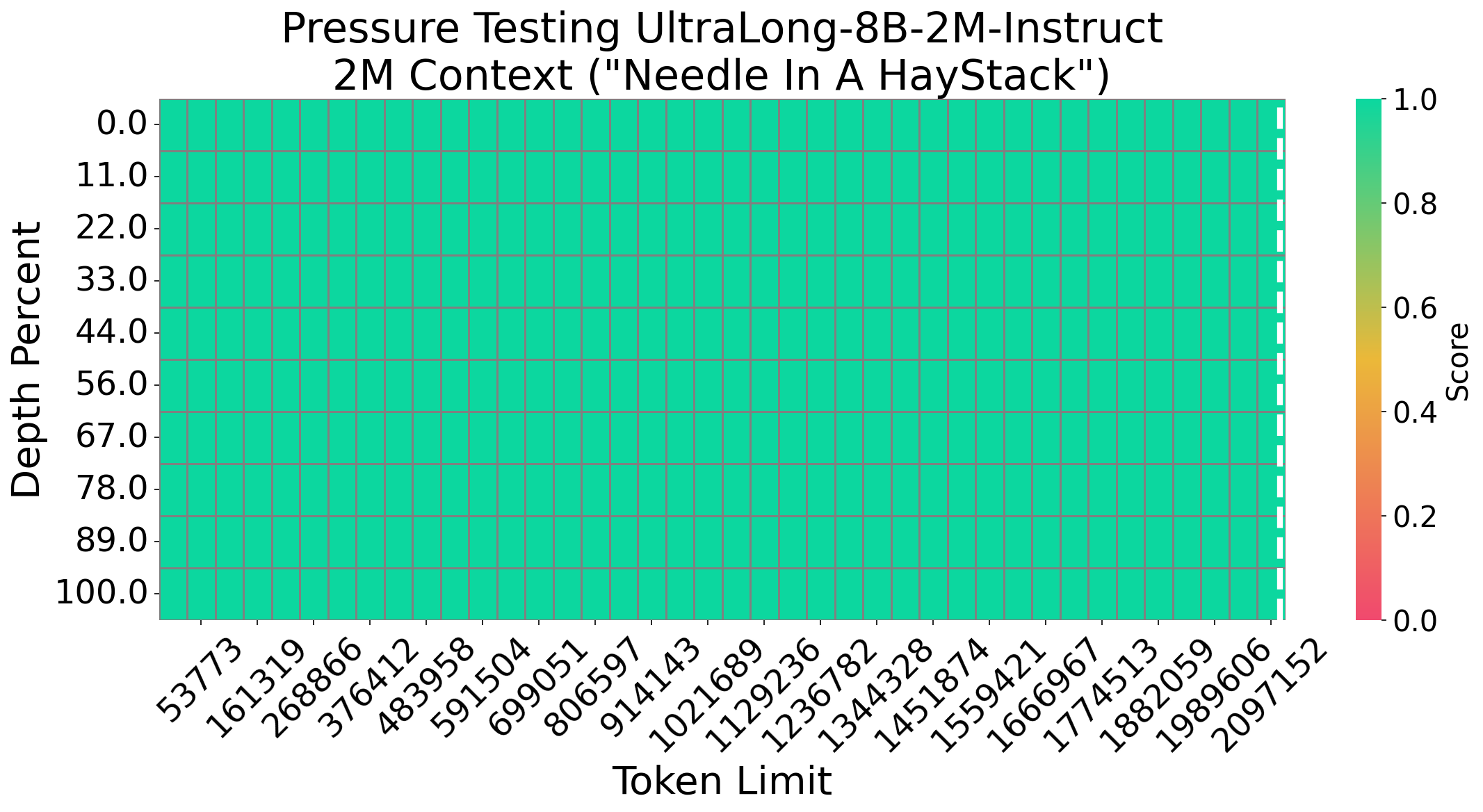
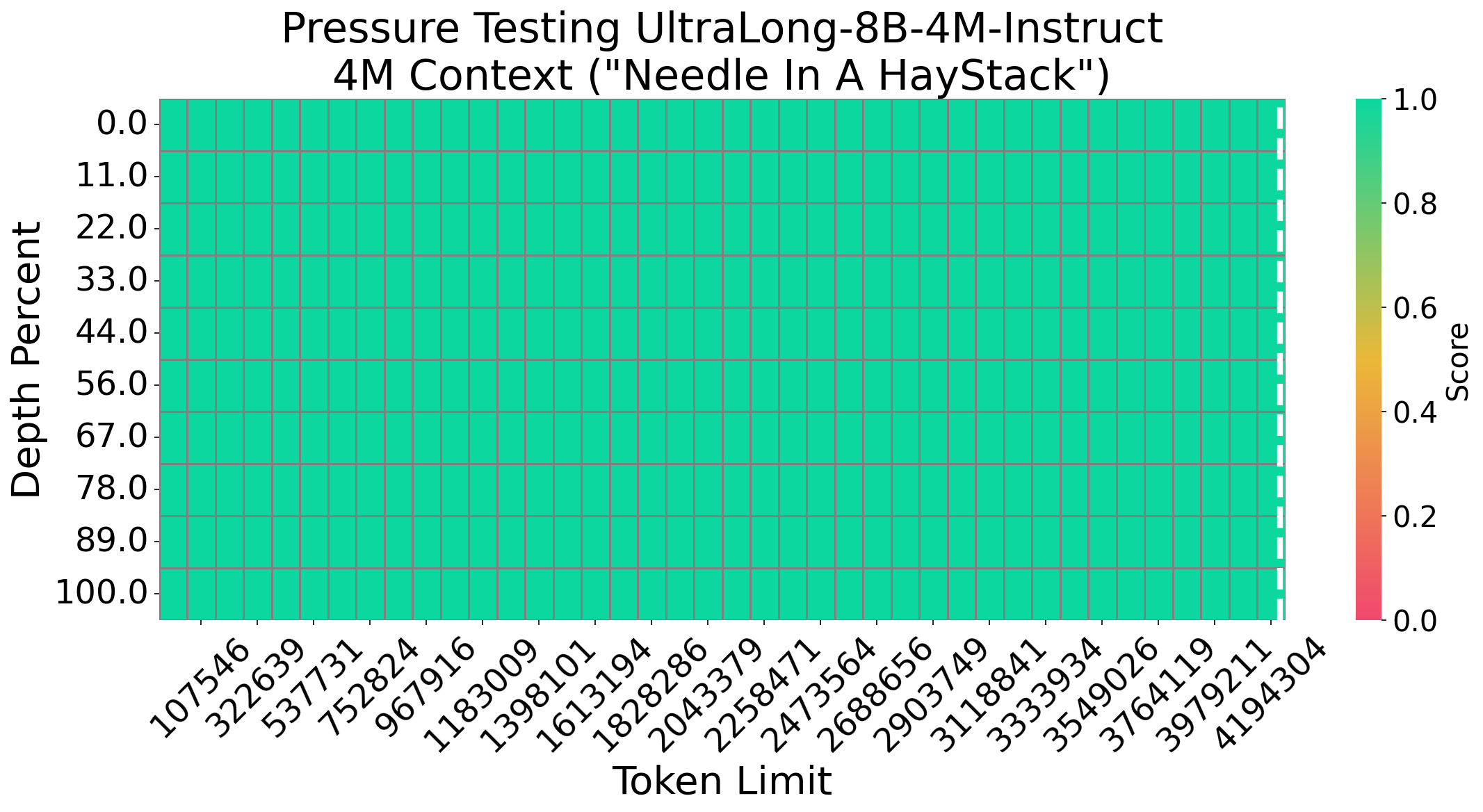
We evaluate Nemotron-UltraLong-8B using the Needle In A Haystack (NIAH) test—a popular benchmark for assessing long-context retrieval. Our model consistently achieves 100% accuracy across various sequence lengths and document depths, demonstrating its robust long-context retrieval capability.
Long Context Benchmarks
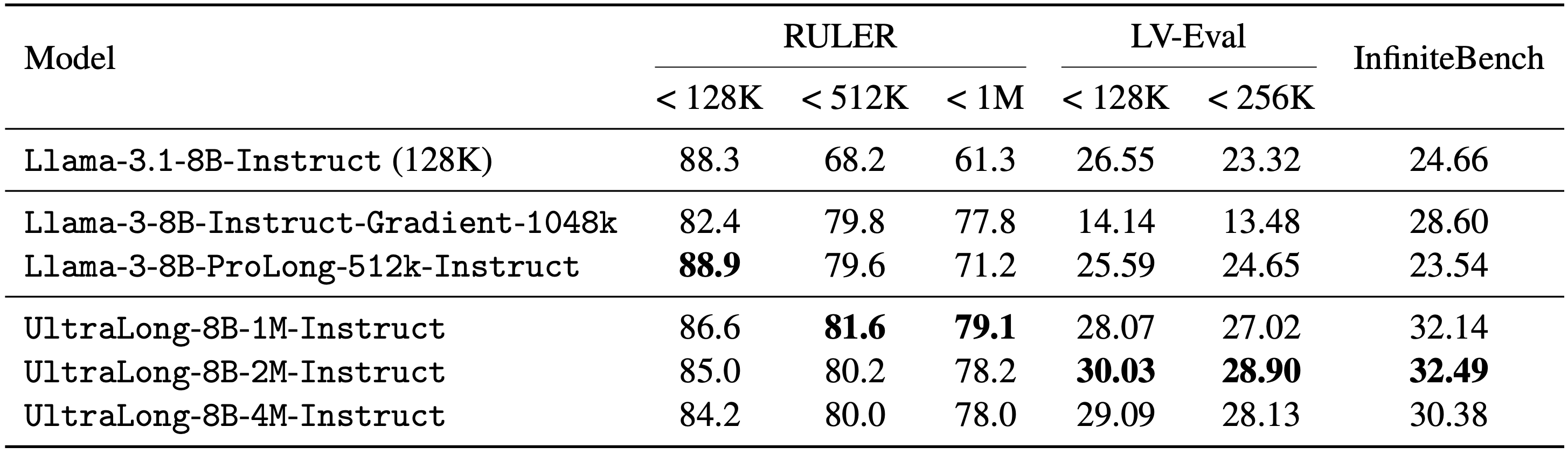
Nemotron-UltraLong-8B achieves superior results on real-world ultra-long tasks, outperforming existing models on benchmarks that require processing inputs beyond 128K tokens.
Standard Benchmarks
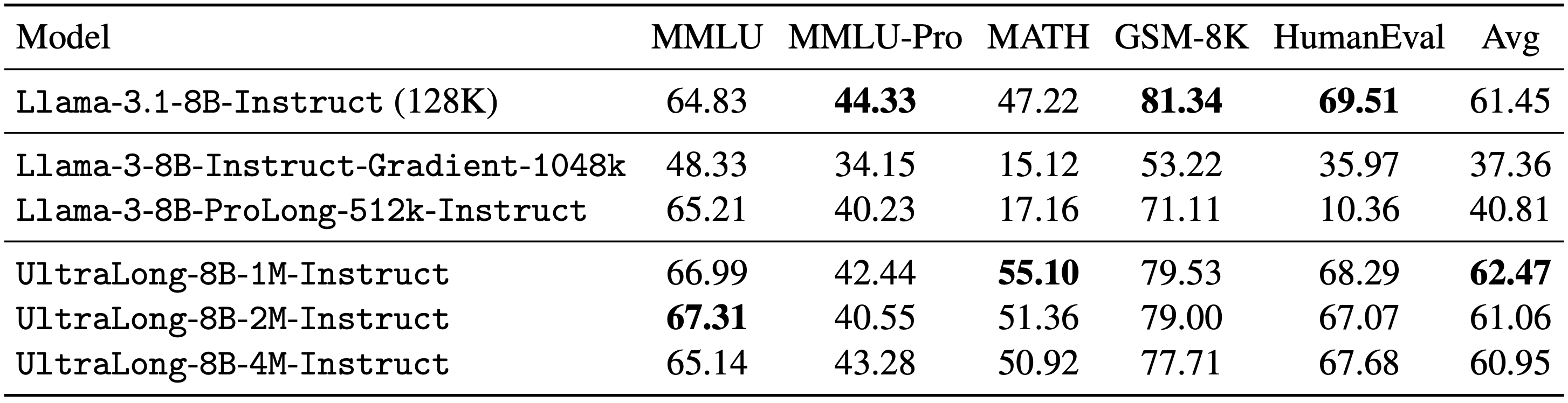
In addition to its long-context capabilities, Nemotron-UltraLong-8B maintains competitive performance on standard benchmarks, demonstrating balanced improvements for both long and short input tasks.
Citation
@article{xu2025128k,
title={From 128K to 4M: Efficient Training of Ultra-Long Context Large Language Models},
author={Xu, Chejian and Ping, Wei and Xu, Peng and Liu, Zihan and Wang, Boxin and Shoeybi, Mohammad and Li, Bo and Catanzaro, Bryan},
journal={arXiv preprint arXiv:2504.06214},
year={2025}
}