
Abstract
Cosmos Embed1 is a joint video-text embedder tailored for physical AI. Multi-modal embeddings, particularly joint video-text embedders, are critical for physical AI development pipelines. They enable essential data curation tasks including text-to-video search, inverse video search, semantic deduplication, and targeted filtering. Additionally, these embeddings can also serve as representations to condition on for downstream physical AI models. While existing video-text embedders perform well in general domains, they underperform substantially on physical AI tasks. To bridge this gap, we introduce Cosmos Embed1, a joint video-text embedder specifically tailored for physical AI applications.
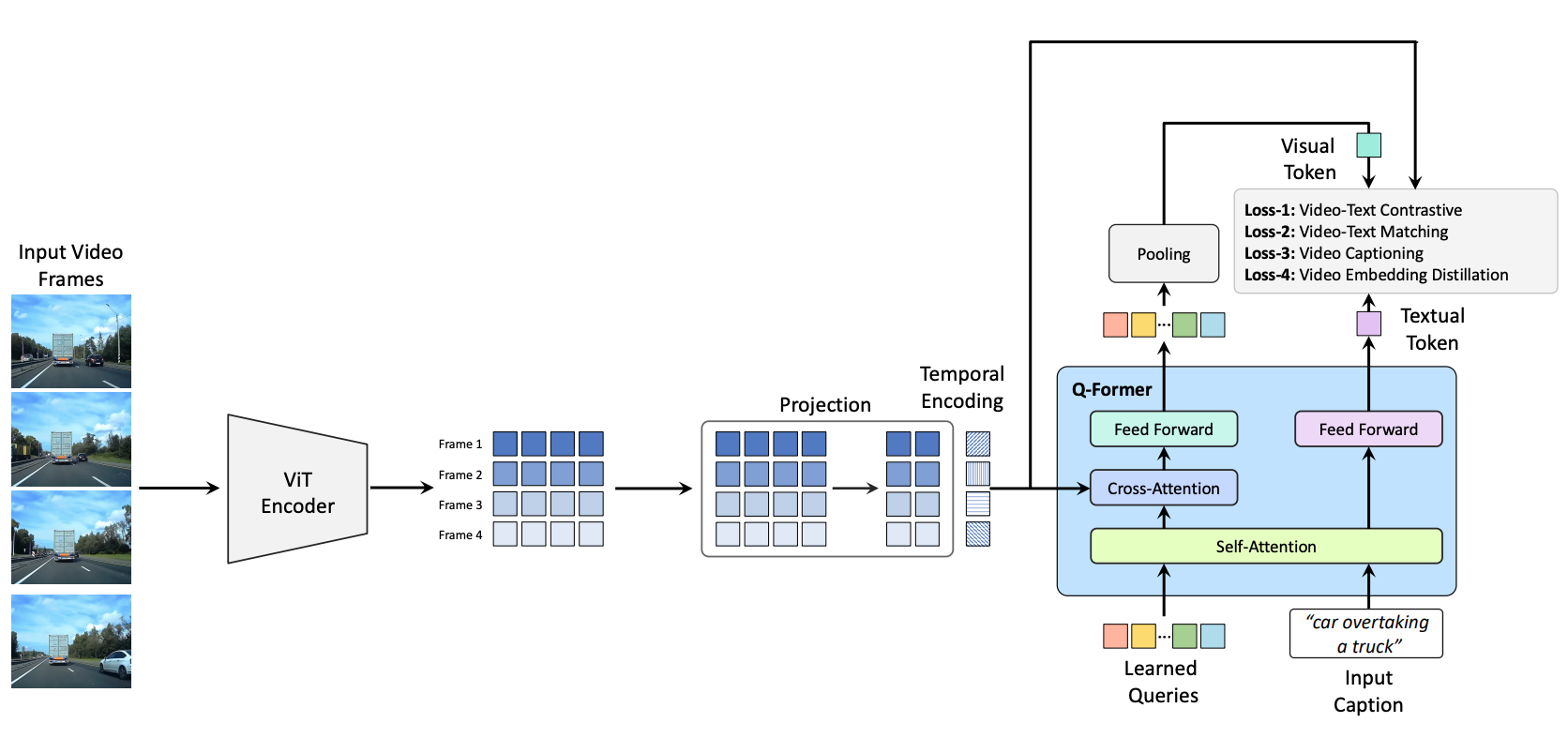
Cosmos Embed1 architecture is based on QFormer, with modifications for processing video inputs. The video embedder processes frames individually using a ViT backbone. Per-frame ViT features are concatenated along the temporal dimension and augmented with temporal embeddings. The resulting sequence is passed to a QFormer module, which uses cross-attention to extract a compact set of visual query tokens from the input frames. The visual query tokens are pooled to produce a single video embedding. The text embedder processes tokenized text through the self-attention branch of the QFormer to generate a text embedding. Text and video embeddings are L2-normalized and aligned using contrastive video-text loss, supplemented by video-text matching and video captioning losses. We release three versions of Cosmos-Embed1 — optimized to process 8 frames per video at 224p, 336p, and 448p resolutions respectively.
Cosmos-Embed1 was trained on a curated dataset of nearly 8M paired video-text samples spanning diverse domains: general-purpose videos, human actions, robotic tasks, and ego-centric vehicle scenarios. The model supports text-to-video retrieval, inverse video search, semantic deduplication, kNN classification, and serves as a base for video curation tasks. Cosmos-Embed1 achieves SOTA performance on AV and robotics datasets while maintaining competitive performance in general domains.
Intermediate Feature Visualizations
Analysis of intermediate video features (via robust PCA) suggests that Cosmos-Embed1 (1B) captures dense semantic information more effectively than other video-text counterparts like InternVideo2-s2 (6B) and Perception Encoder Core-G (2B). This potential enhancement in semantic understanding appears evident in the model's ability to maintain reasonably consistent feature representations across frames, likely resulting from the training-time embedding distillation objectives.
Quantitative Results
General & Actions Domain
Cosmos-Embed1 is competitive with contemporary state-of-the-art embedding models in general video retrieval, and outperforms the state-of-the-art in action recognition.
| Embedding Model | General Retrieval — MSR-VTT | Kinetics-400 (val) | Kinetics-600 (val) | Kinetics-700 (val) | ||||
|---|---|---|---|---|---|---|---|---|
| T2V R@1 | V2T R@1 | Accuracy | F1-Score | Accuracy | F1-Score | Accuracy | F1-Score | |
| InternVideo2-s2 (6B) | 48.00 | 46.40 | 62.64 | 60.58 | 59.75 | 57.14 | 52.38 | 49.81 |
| Perception Encoder Core-448p-G (2B) | 51.00 | 49.90 | 76.71 | 76.00 | 76.02 | 75.14 | 68.84 | 68.28 |
| Cosmos-Embed1-336p (1B) | 47.60 | 47.60 | 87.77 | 87.66 | 88.19 | 88.06 | 74.74 | 74.57 |
Retrieval metrics with DSL re-ranking, linearly spaced frames with square resizing for all methods, at bfloat16 precision. For action-recognition in Kinetics, we use the standard templates from PE and take the max similarity of all templates per class.
Robotics Domain
Cosmos-Embed1 outperforms contemporary state-of-the-art embedding models in robotics scenario retrieval across different robot embodiments and viewpoints.
| Embedding Model | Scenario Retrieval | |||||||
|---|---|---|---|---|---|---|---|---|
| 1x Robotics | AgiBot | Bridge | RT-1 | |||||
| T2V R@1 | V2T R@1 | T2V R@1 | V2T R@1 | T2V R@1 | V2T R@1 | T2V R@1 | V2T R@1 | |
| InternVideo2-s2 (6B) | 36.50 | 30.00 | 1.20 | 7.82 | 8.17 | 6.16 | 3.78 | 2.45 |
| Perception Encoder Core-448p-G (2B) | 36.50 | 24.50 | 1.16 | 0.83 | 7.19 | 5.24 | 2.63 | 2.58 |
| Cosmos-Embed1-336p (1B) | 61.50 | 65.50 | 7.04 | 6.33 | 24.51 | 22.90 | 19.94 | 20.21 |
Retrieval metrics with DSL re-ranking, linearly spaced frames with square resizing for all methods, at bfloat16 precision.
AV Domain
Cosmos-Embed1 outperforms contemporary state-of-the-art embedding models in AV action recognition (Internal AV Actions dataset with 22 action classes) and scenario retrieval (OpenDV).
| Embedding Model | Action Recognition — AV Actions (Internal, 22 Classes) | Scenario Retrieval — OpenDV | ||
|---|---|---|---|---|
| Accuracy | F1-Score | T2V R@1 | V2T R@1 | |
| InternVideo2-s2 (6B) | 12.71 | 10.54 | 7.33 | 6.60 |
| Perception Encoder Core-448p-G (2B) | 23.01 | 21.89 | 9.58 | 9.30 |
| Cosmos-Embed1-336p (1B) | 72.23 | 72.28 | 34.42 | 34.67 |
Retrieval metrics with DSL re-ranking, linearly spaced frames with square resizing for all methods, at bfloat16 precision. For action-recognition in AV Actions (Internal), we use prompt templates specific to ego-vehicle actions.
Cosmos-Embed1 Search Demo
Cosmos-Embed1 in action with Text-to-Video and Video-to-Video search on real-world examples.
Citation
Please cite as NVIDIA et al. using the following BibTex:
@misc{nvidia2025cosmosembed1,
title={Cosmos-Embed1: A Joint Video-Text Embedder for Physical AI},
author={NVIDIA and Ferroni, Francesco and Chattopadhyay, Prithvijit and Heinrich, Greg and Ranzinger, Mike and Amoroso, Roberto and Luo, Alice and Wang, Andrew and Liu, Ming-Yu},
url={https://research.nvidia.com/labs/dir/cosmos-embed1/},
year={2025}
}