Abstract
Aligning generative diffusion models with human preferences via reinforcement learning (RL) is critical yet challenging. Most existing algorithms are often vulnerable to reward hacking, such as quality degradation, over-stylization, or reduced diversity. Our analysis demonstrates that this can be attributed to the inherent limitations of their regularization, which provides unreliable penalties. We introduce Data-regularized Diffusion Reinforcement Learning (DDRL), a novel framework that uses the forward KL divergence to anchor the policy to an off-policy data distribution. Theoretically, DDRL enables robust, unbiased integration of RL with standard diffusion training. Empirically, this translates into a simple yet effective algorithm that combines reward maximization with diffusion loss minimization. Extensive experiments and double-blind human votes demonstrate that DDRL significantly improves rewards while alleviating the reward hacking seen in baselines, achieving the highest human preference and establishing a robust and scalable paradigm for diffusion post-training.
TL;DR
DDRL is a novel data-regularized reinforcement learning framework for diffusion models at scale.
- We identify that existing diffusion RL algorithms are vulnerable to reward hacking due to on-policy regularization, where the reference model fails to effectively constrain samples in out-of-distribution regions.
- We propose Data-regularized Diffusion Reinforcement Learning (DDRL), a theoretically principled framework that leverages forward KL divergence to seamlessly integrate reward maximization with standard diffusion loss minimization using real or synthetic data.
- Extensive empirical studies, utilizing over one million GPU hours and thousands of human evaluations, demonstrate that DDRL significantly outperforms baselines in human preference and reward scores on high-resolution video and image generation tasks.
Our findings show that DDRL achieves Pareto improvement across human preference alignment and quality metrics, effectively alleviating the reward hacking issues prevalent in current methods.
Methodology
Motivation
Background: Standard reinforcement learning algorithms for diffusion models view the denoising process as a Markovian Decision Process (MDP), where states are intermediate variable xt and actions are next-step samples from the diffusion model, with a reward function r(x0, c) defined on the eventual output x0 under the condition c. Classical RL maximizes the following objective:
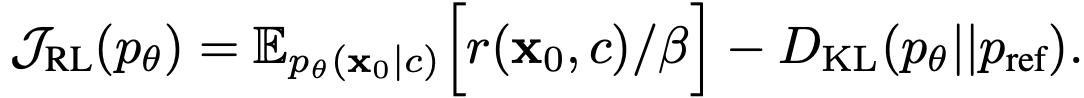
Recent works such as FlowGRPO and DanceGRPO introduce additional GRPO-style advantages terms to replace the absolute rewards. For regularization, they either rely on reverse KL divergence (as defined above) or on heuristics.
Most vision reward models are learned from human preferences data and are non-verifiable: they accurately reflect human preferences only in a neighborhood of the training data manifold. As the policy is optimized for reward maximization, its multi-step, Markovian sampling procedure can easily exploit out-of-distribution (OOD) regions away from the data manifold, where the reference model is barely trained and fails to provide accurate regularization. This issue lies in the adoption of on-policy samples for regularization, and makes existing algorithms vulnerable to reward hacking, a phenomenon where models generate human-unpreferred samples that nevertheless receive high rewards, resulting in issues like diversity decline, quality degradation, and over-stylization.
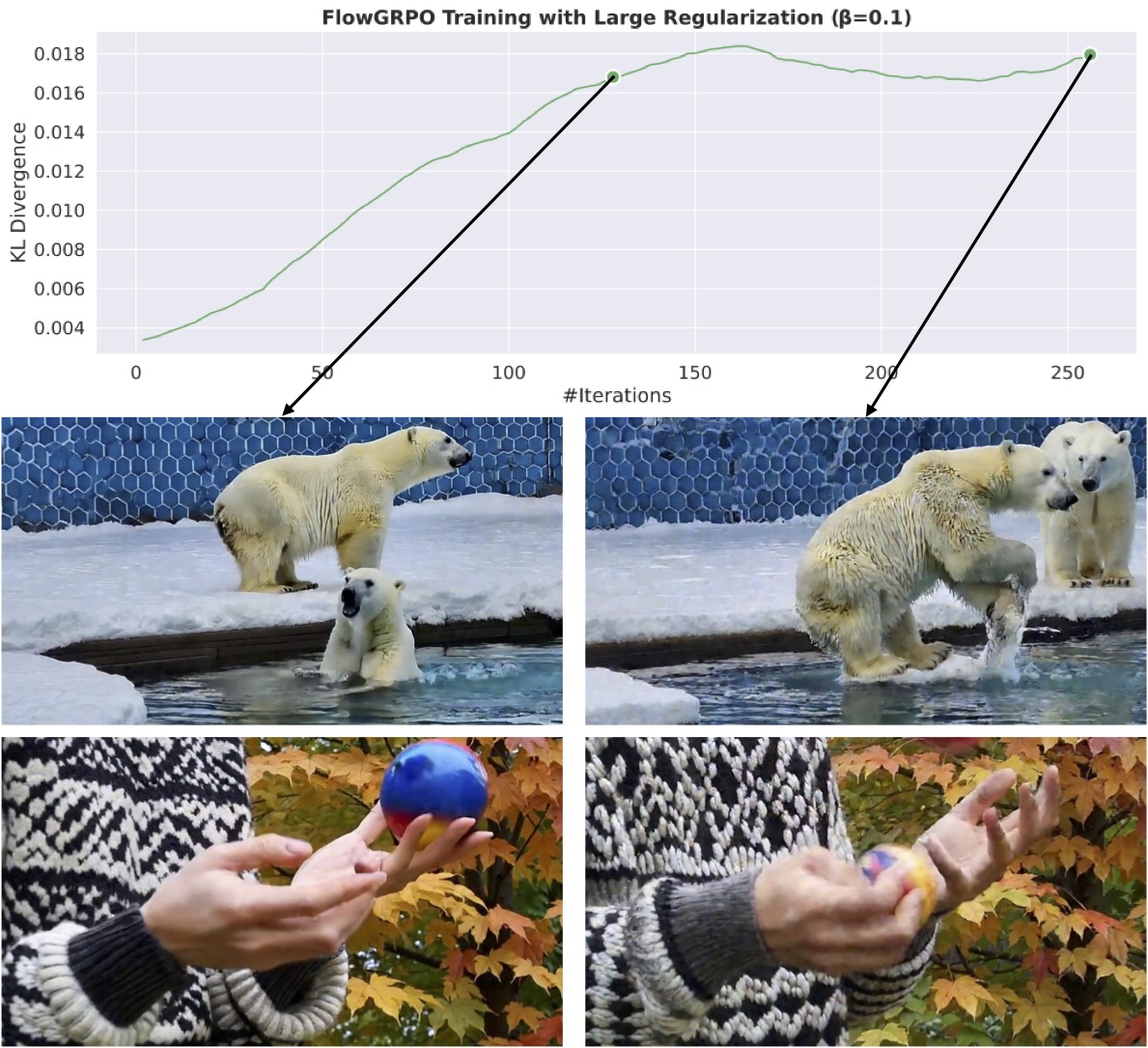
Even with significantly larger KL coefficient and the divergence remains stable throughout the training, unrealistic noise textures still appear in videos generated by the latter checkpoint. This implies that controlling the reverse KL divergence is insufficient to regularize the policy.
DDRL Framework
Data-regularized Diffusion Reinforcement Learning (DDRL) novelly anchors the policy directly to the data distribution. Instead of relying on the model's own generations for regularization, it leverages the forward KL divergence between the data diffusion distribution and the policy distribution to regularize the policy:
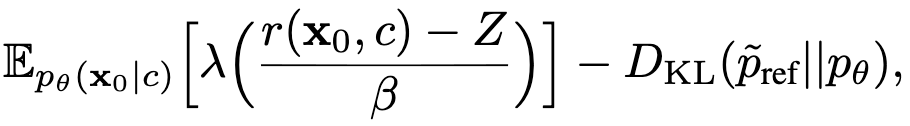
where λ is a monotonic transformation, and Z is the "average reward". Importantly, the data diffusion distribution is defined as:
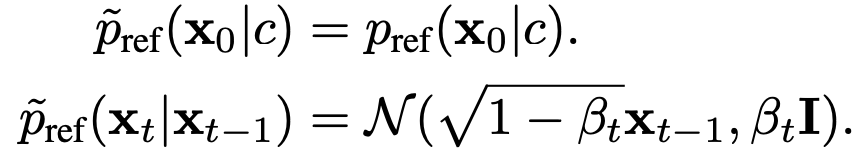
This objective has the following advantages:
- Off-policy regularization: the forward KL divergence is defined over the data distribution, which is independent of the potential reward hacking regions.
- The original reference model is only used as a sampler, which can be seamlessly replaced by the high-quality data used to train the model (or by synthetic data it generates upfront). As a result, there is no need to maintain a reference model copy.
- This divergence is exactly where we derive standard diffusion loss from. Consequently, we can further convert
the DDRL objective as follows:
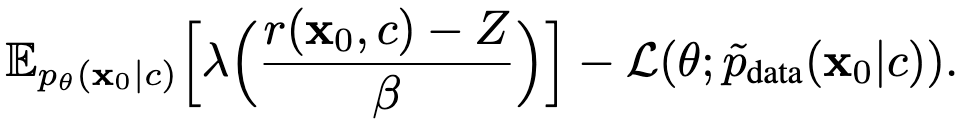
Here, the second term is the standard diffusion loss computed over pdata.
Theoretical Guarantee: Maximizing the above two objectives is equivalent, and the optimal policy is proportional to the data distribution reweighted by the preference reward:
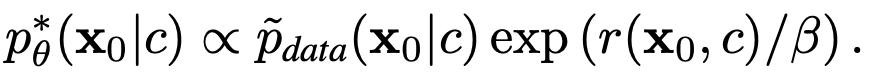
This result also demonstrates that DDRL effectively integrates supervised fine-tuning (via diffusion loss minimization) and reinforcement learning (via reward maximization). It theoretically justifies for the first time the merit of combining two post-training stages.
Practical Implementation
We present the pseudo-code of DDRL below. For diffusion loss minimization, similar to standard diffusion training, we omit the coefficient for the sake of stability. For reward maximization, we omit the monotonic transformation λ such that the training reward scales are consistent and comparable. We compute Z using the average reward within the rollout group, and additionally divide the standard deviation.

Results
Video Generation Results
We evaluate DDRL on large-scale text-to-video and image-to-video generation tasks using Cosmos2.5 (2B and 14B). We conduct double-blind human between videos generated by DDRL and baselines, and report the different in the win percentage (Denote as Δ-Vote, where negative values indicate DDRL is more preferred).
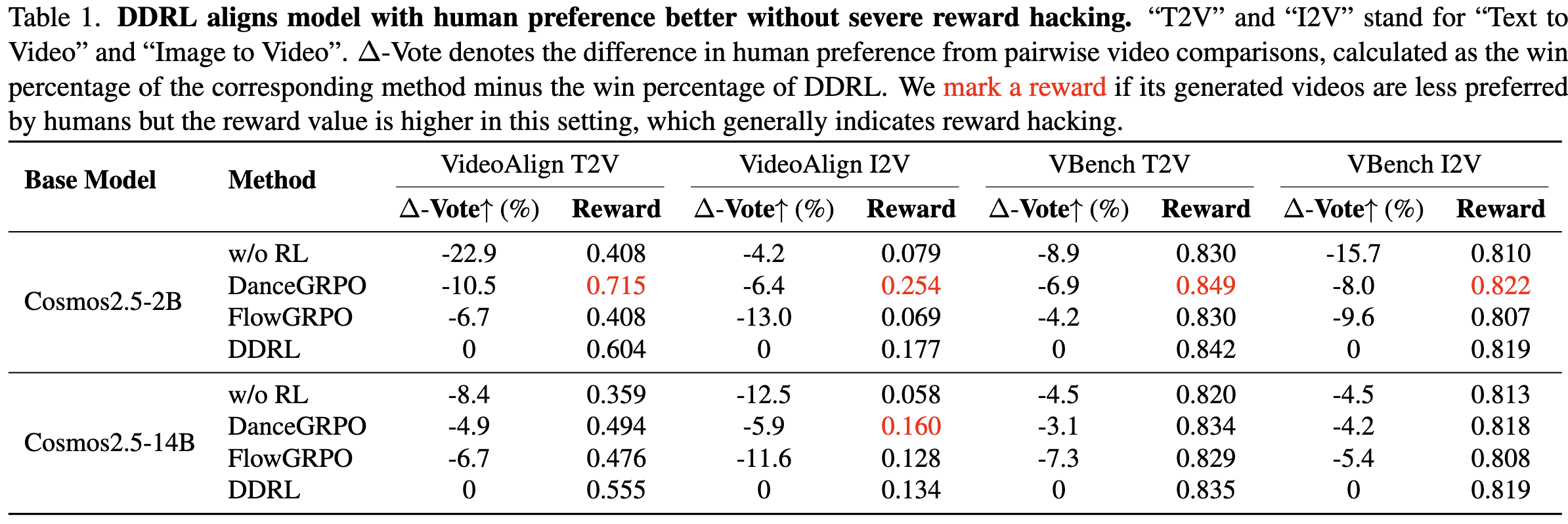
Image Generation Results
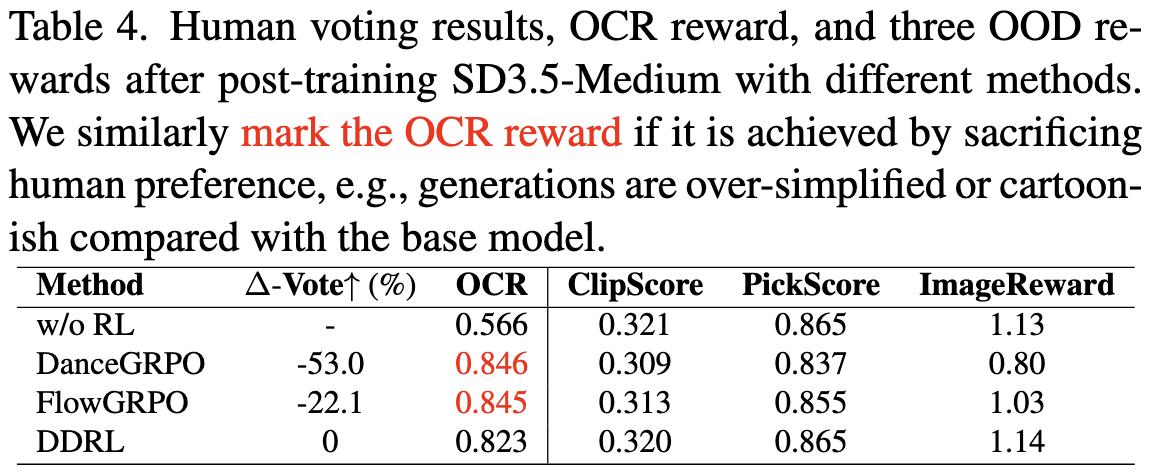
We evaluate DDRL using the text-rendering reward (OCR score) from the base model SD3.5-medium. We similarly report human preference differences and the reward scores.

Integrating SFT and RL
We compare the performance of DDRL with and without the initial supervised fine-tuning stage. Running DDRL from the pre-trained model achieves comparably high rewards and low diffusion loss (0.119 v.s. 0.121) to the SFT-then-DDRL model. It demonstrates DDRL's potential to increase data efficiency and simplify the diffusion post-training paradigm.
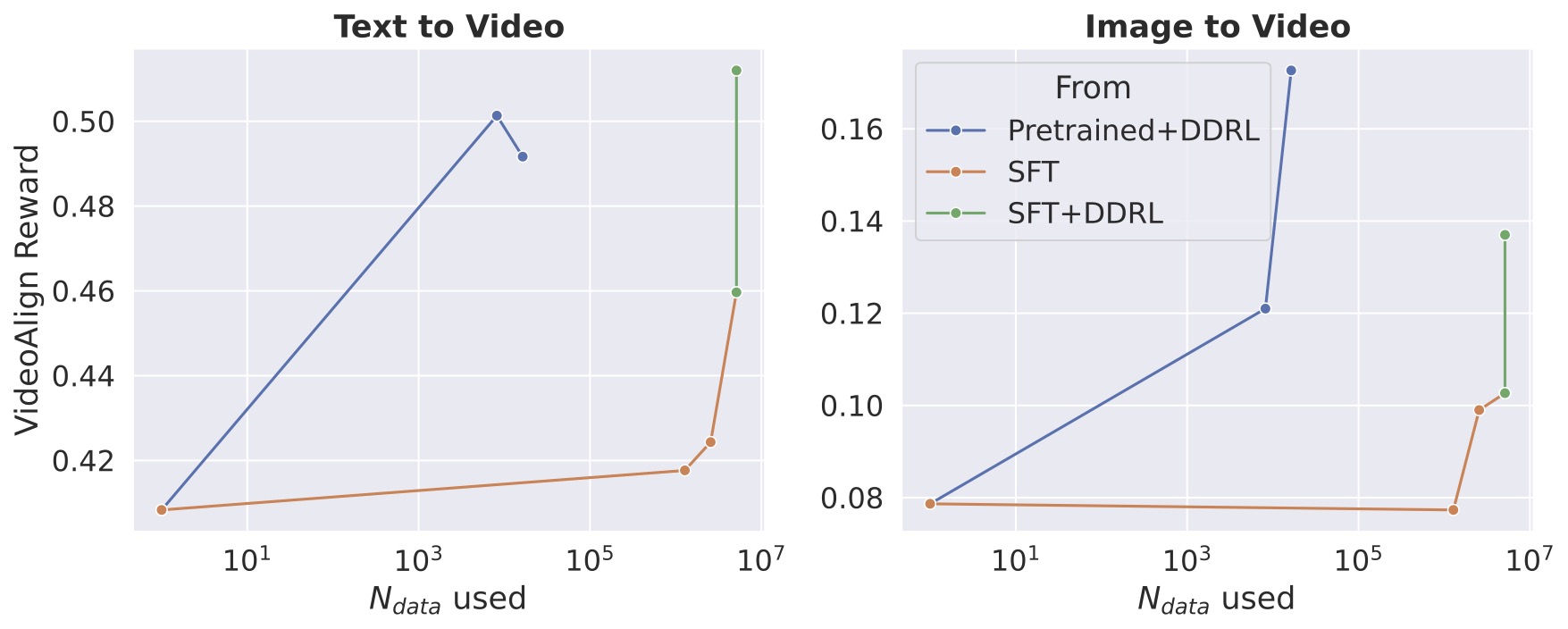
VideoAlign reward after post-training with DDRL from (1) pretrained model and (2) SFT model. The former achieves comparably high rewards with significantly higher data efficiency.
Citation
@article{ye2025ddrl,
title={Data-regularized Reinforcement Learning for Diffusion Models at Scale},
author={Ye, Haotian and Zheng, Kaiwen and Xu, Jiashu and Li, Puheng and Chen, Huayu and Han, Jiaqi and Liu, Sheng and Zhang, Qinsheng and Mao, Hanzi and Hao, Zekun and Chattopadhyay, Prithvijit and Yang, Dinghao and Feng, Liang and Liao, Maosheng and Bai, Junjie and Liu, Ming-Yu and Zou, James and Ermon, Stefano},
journal={arXiv preprint arXiv:2512.04332},
year={2025}
}