Abstract
Annotating camera poses on dynamic Internet videos at scale is critical for advancing fields like realistic video generation and simulation. However, collecting such a dataset is difficult, as most Internet videos are unsuitable for pose estimation. Furthermore, annotating dynamic Internet videos present significant challenges even for state-of-the-art methods. In this paper, we introduce DynPose-100K, a large-scale dataset of dynamic Internet videos annotated with camera poses. Our collection pipeline addresses filtering using a carefully combined set of task-specific and generalist models. For pose estimation, we combine the latest techniques of point tracking, dynamic masking, and structure-from-motion to achieve improvements over the state-of-the-art approaches. Our analysis and experiments demonstrate that DynPose-100K is both large-scale and diverse across several key attributes, opening up avenues for advancements in various downstream applications.
Video
Examples
We introduce DynPose-100K, a large collection of dynamic Internet videos with camera annotations. The dataset contains diverse content and a variety of trajectories of different lengths and dynamic object sizes. We show several examples of input videos and their respective camera pose estimations.
Collection Pipeline
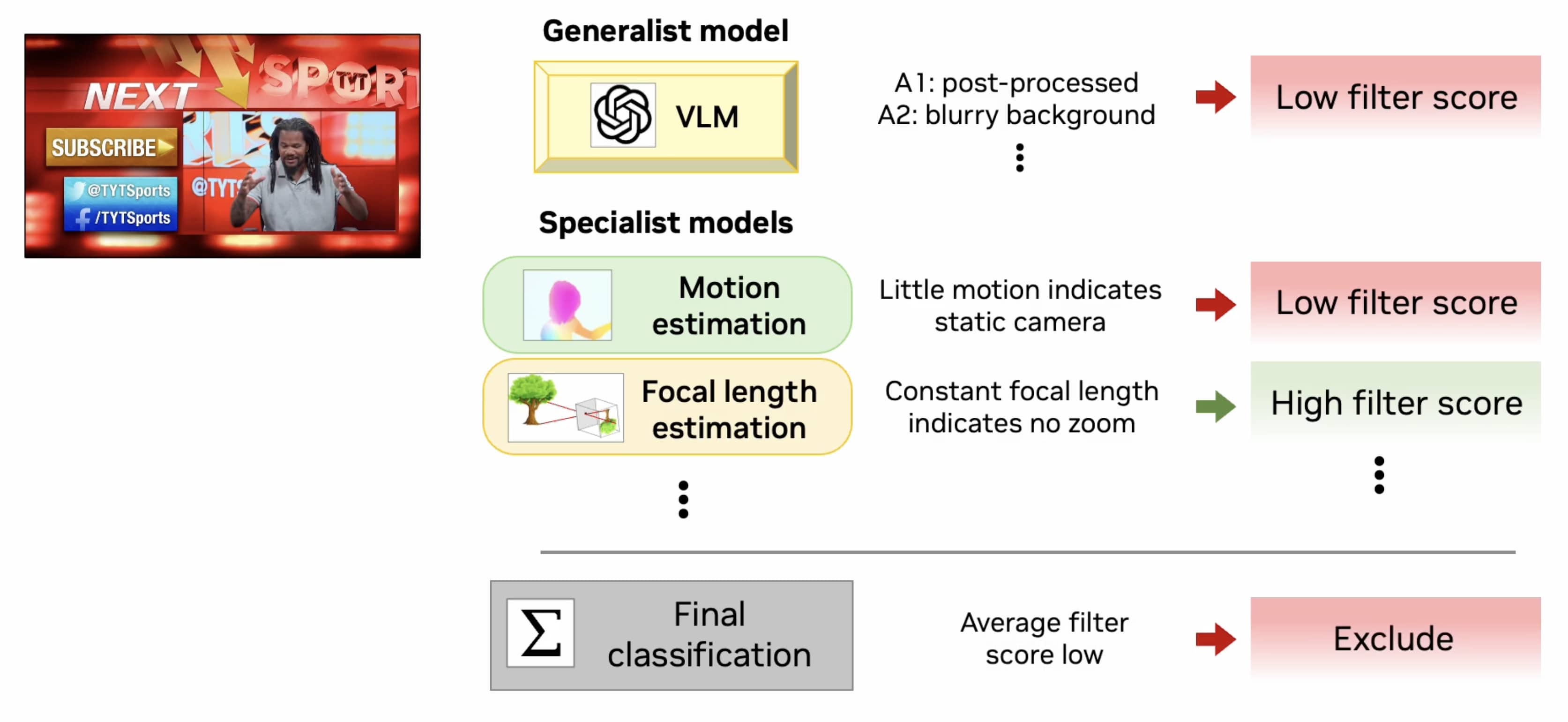
DynPose-100K video curation utilizes a generalist VLM in combination with several specialist models.
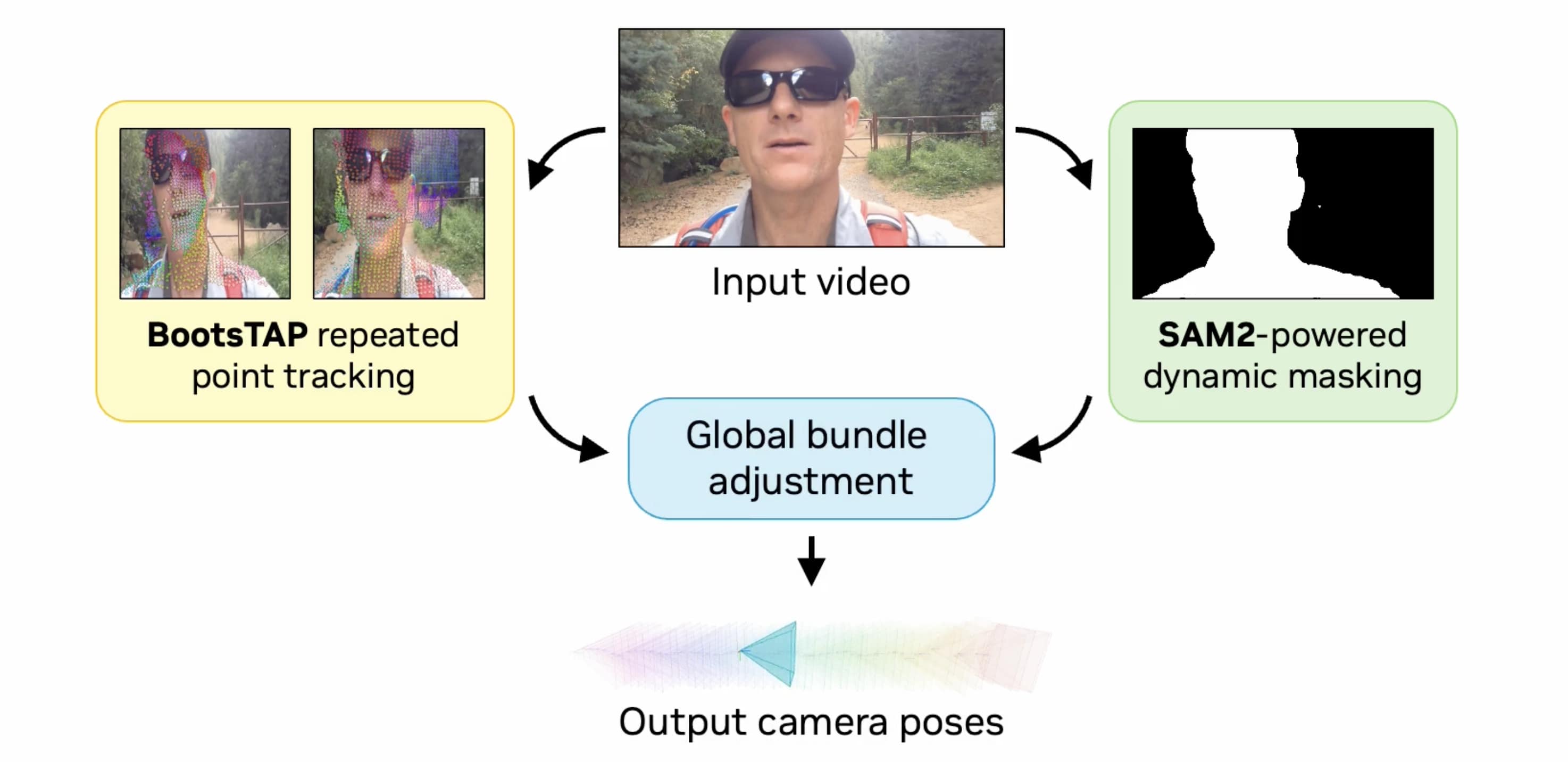
We design a state-of-the-art camera pose estimation pipeline incorporating the latest point tracking and dynamic masking methods.
Statistics
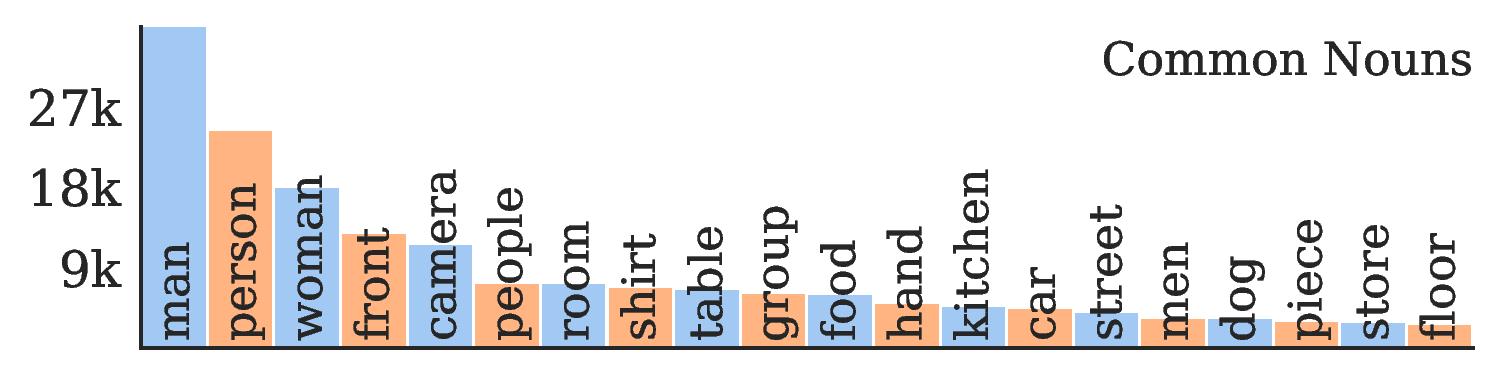
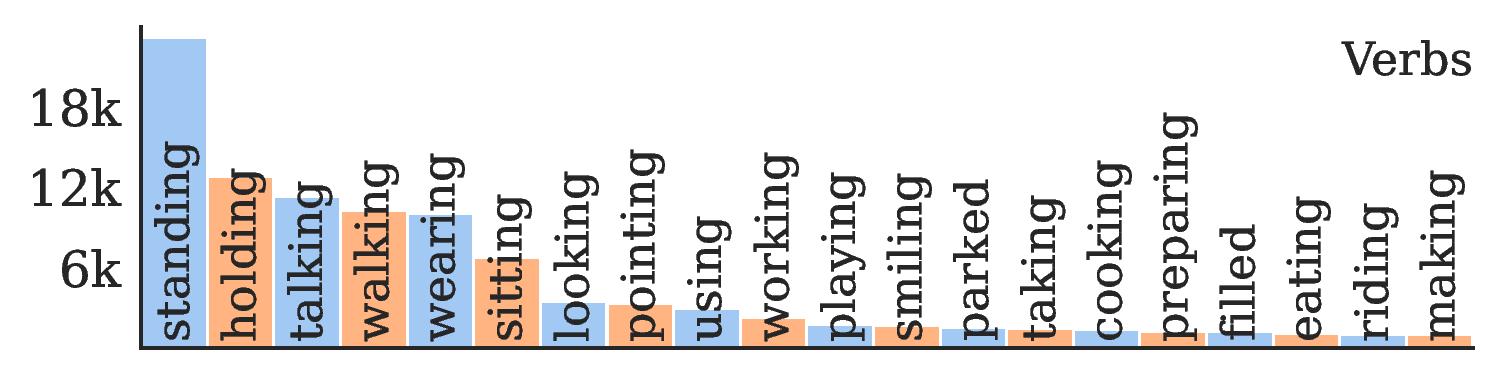
Diverse content. Frequent nouns include a variety of subjects: people, car, dog; and settings: kitchen, store, street. Frequent verbs include a variety of actions: playing, riding, making.
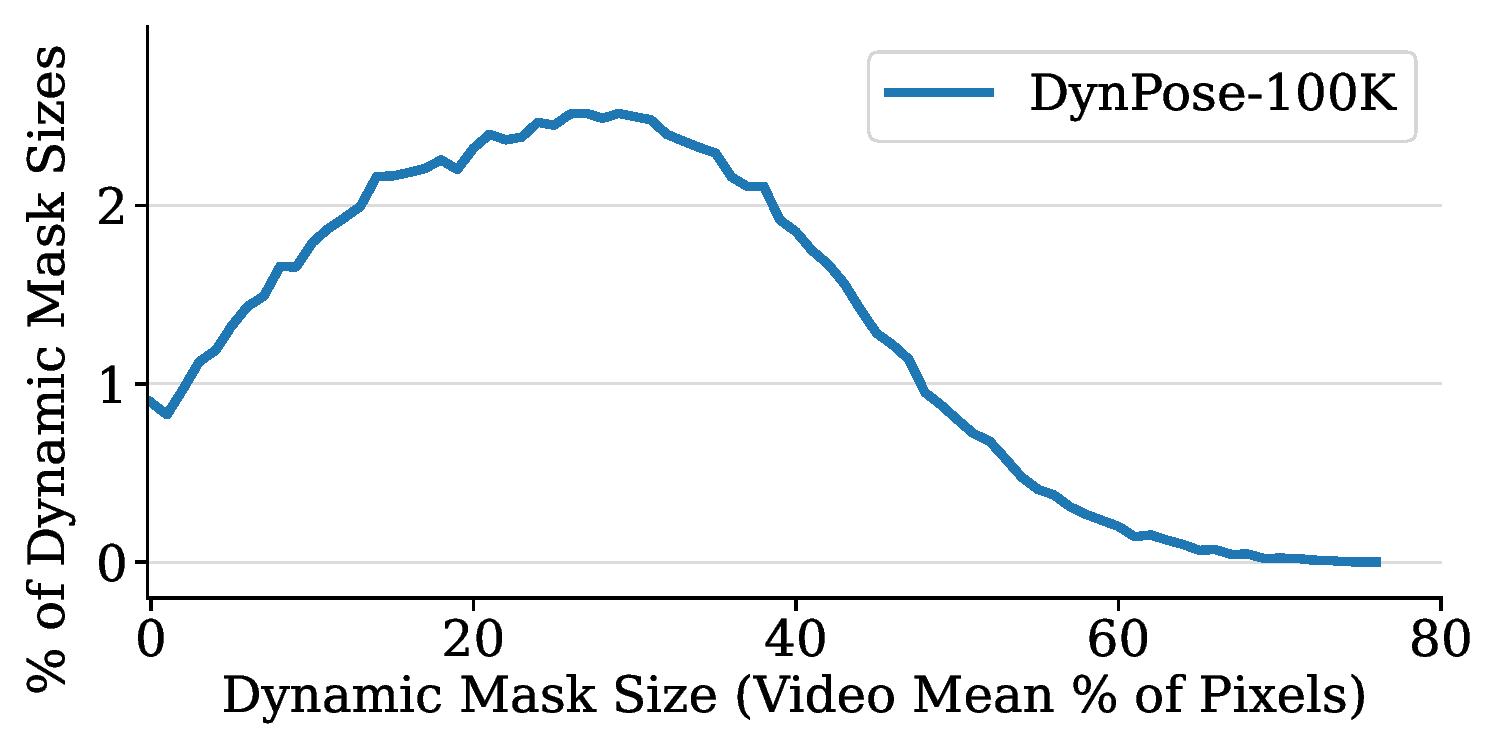
Diverse dynamic apparent size. Large dynamic objects mean fewer correspondences, in turn making pose estimation challenging.
Acknowledgments
We thank Gabriele Leone and the NVIDIA Lightspeed Content Tech team for sharing the original 3D assets and scene data for creating the Lightspeed benchmark dataset. We thank Yunhao Ge, Zekun Hao, Yin Cui, Xiaohui Zeng, Zhaoshuo Li, Hanzi Mao, Jiahui Huang, Justin Johnson, JJ Park and Andrew Owens for invaluable inspirations, discussions and feedback on this project.
Citation
@inproceedings{rockwell2025dynpose,
title={Dynamic Camera Poses and Where to Find Them},
author={Rockwell, Chris and Tung, Joseph and Lin, Tsung-Yi and Liu, Ming-Yu and Fouhey, David F. and Lin, Chen-Hsuan},
booktitle={IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2025}
}