


Abstract
We propose eDiff-I, a diffusion model for synthesizing images given text. Motivated by the empirical observation that the behavior of diffusion models differ at different stages of sampling, we propose to train an ensemble of expert denoising networks, each specializing for a specific noise interval. Our model is conditioned on the T5 text embeddings, CLIP image embeddings and CLIP text embeddings. Our approach can generate photorealistic images corresponding to any input text prompt.
In addition to text-to-image synthesis, we present two additional capabilities — (1) style transfer, which enables us to control the style of the generated sample using a reference style image, and (2) "Paint with words" — an application where the user can generate images by painting segmentation maps on canvas, which is very handy for crafting the desired image in mind.
Video
Pipeline
Our pipeline consists of a cascade of three diffusion models — a base model which can synthesize samples of 64×64 resolution, and two super-resolution stacks that progressively upsample to 256×256 and 1024×1024 resolution respectively. Our models take an input caption and first compute T5 XXL embedding and text embedding. We optionally use CLIP image encodings which serve as a style vector.
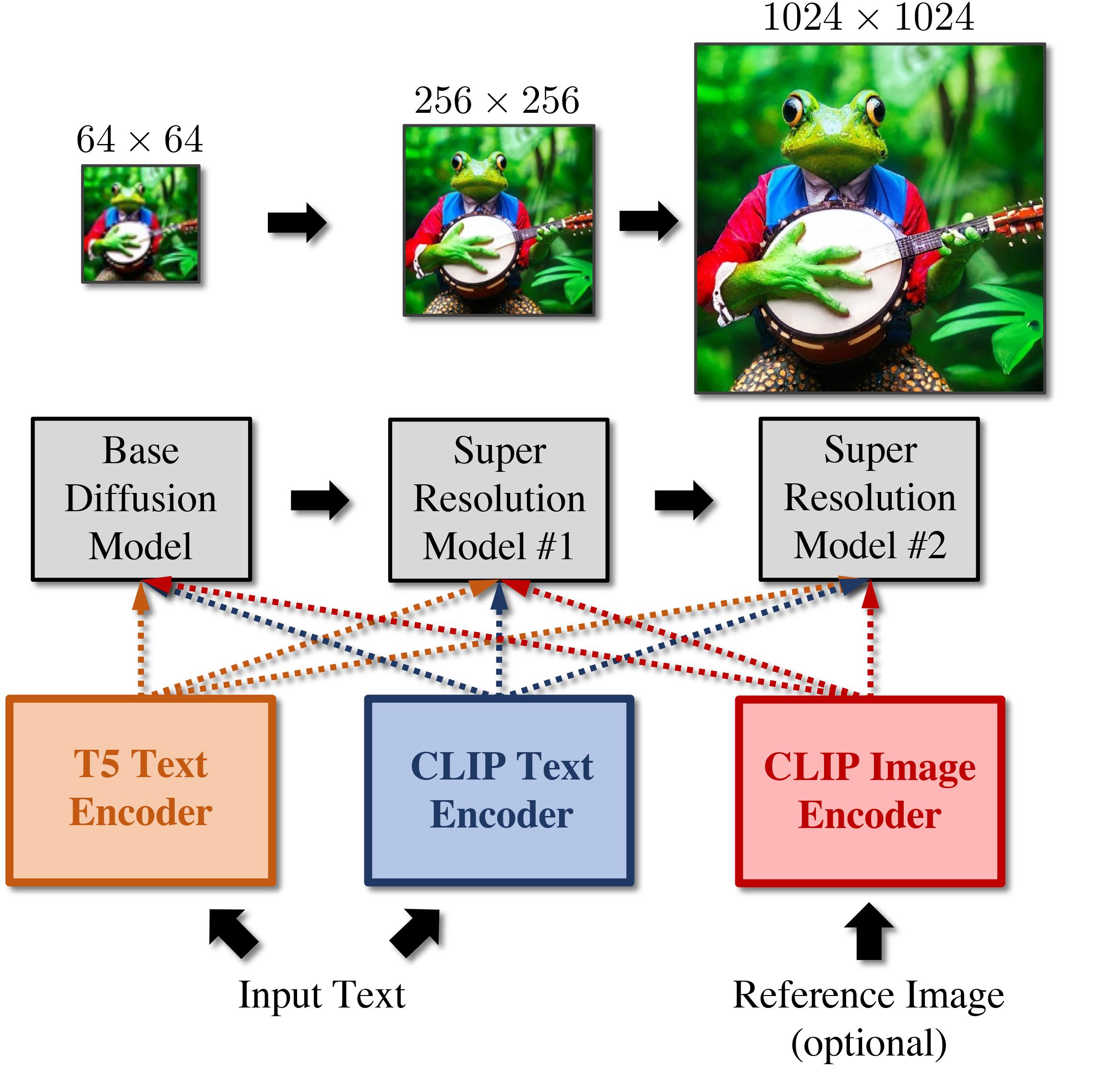
Pipeline
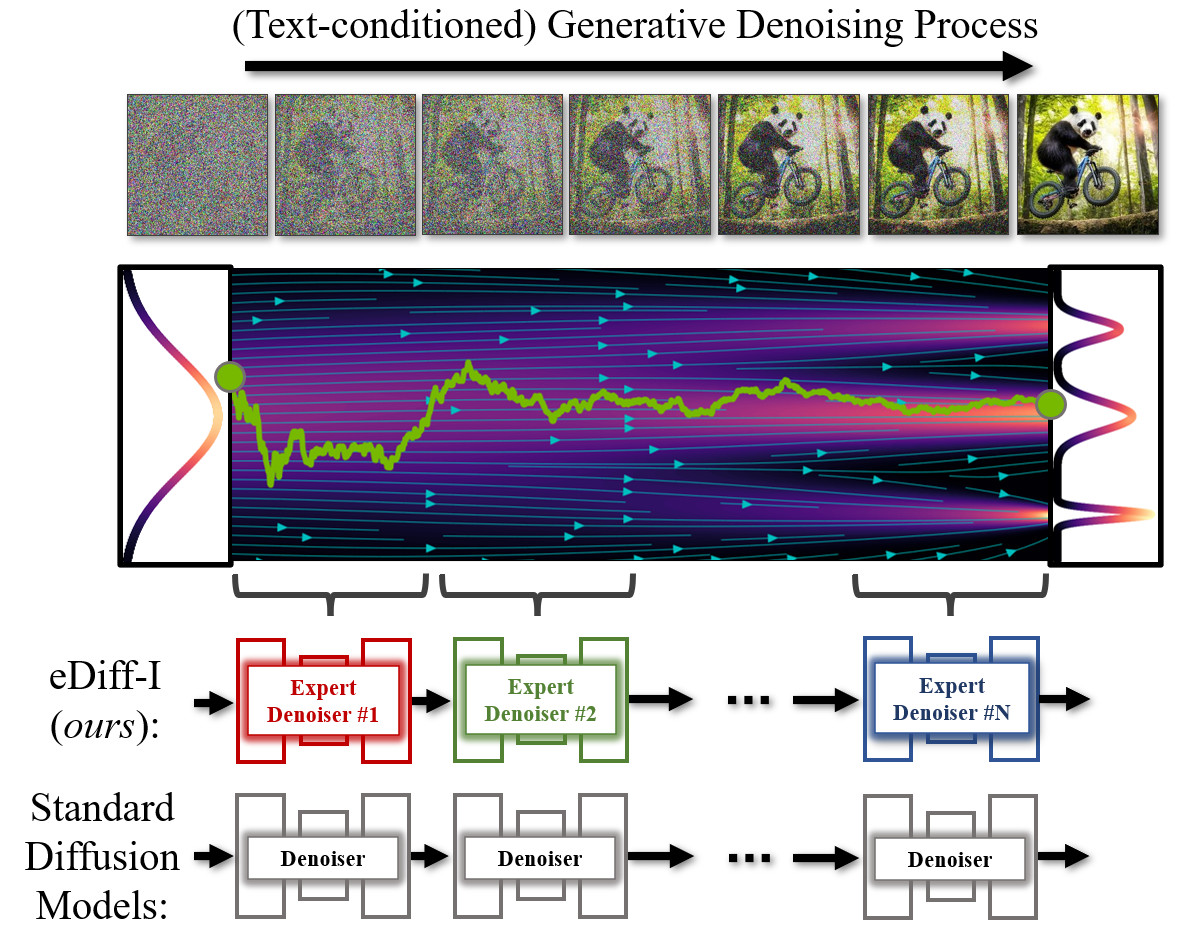
Denoising Experts
In diffusion models, image synthesis happens via an iterative denoising process. In conventional diffusion model training, a single model is trained to denoise the whole noise distribution. In our framework, we instead train an ensemble of expert denoisers that are specialized for denoising in different intervals of the generative process.
Results
Compared to open-source text-to-image methods (Stable Diffusion and DALL-E2), our model consistently leads to improved synthesis quality.
Stable diffusion
DALL-E2
eDiff-I (ours)



There are two Chinese teapots on a table. One pot has a painting of a dragon, while the other pot has a painting of a panda.



A photo of two cute teddy bears sitting on top of a grizzly bear in a beautiful forest. Highly detailed fantasy art, 4k, artstation



A photo of a golden retriever puppy wearing a green shirt. The shirt has text that says "NVIDIA rocks". Background office. 4k dslr



A photo of two monkeys sitting on a tree. They are holding a wooden board that says "Best friends", 4K dslr.



A photo of a plate at a restaurant table with spaghetti and red sauce. There is sushi on top of the spaghetti. The dish is garnished with mint leaves. On the side, there is a glass with a purple drink, photorealistic, dslr.



A close-up 4k dslr photo of a cat riding a scooter. It is wearing a plain shirt and has a bandana around its neck. It is wearing a scooter helmet. There are palm trees in the background.
Applications
Style Transfer
Our method enables style transfer when the CLIP image embeddings are used. From a reference style image, we first extract the CLIP image embeddings which can be used as a style reference vector. When style conditioning is used, our model generates outputs faithful to both the input style and the input caption.
Reference style
Style conditioning enabled
Style conditioning disabled



A photo of two pandas walking on a road.



A detailed oil painting of a beautiful rabbit queen wearing a royal gown in a palace. She is looking outside the window, artistic.



A dslr photo of a dog playing trumpet from the top of a mountain.



A photo of a teddy bear wearing a casual plain white shirt surfing in the ocean.
Paint with Words
Our method allows users to control the location of objects mentioned in the text prompt by selecting phrases and scribbling them on the image. The model then makes use of the prompt along with the maps to generate images consistent with both the caption and the input map.
Benefit of Denoising Experts
We illustrate the benefit of using denoising experts by comparing samples from our approach and a baseline without denoising experts. Using expert models greatly improves faithfulness to the input text.
Baseline
eDiff-I




A 4k dslr photo of two teddy bears wearing a sports jersey with the text "eDiffi" written on it. They are on a soccer field.
Citation
@article{balaji2022eDiff-I,
title={eDiff-I: Text-to-Image Diffusion Models with Ensemble of Expert Denoisers},
author={Balaji, Yogesh and Nah, Seungjun and Huang, Xun and Vahdat, Arash and Song, Jiaming and Zhang, Qinsheng and Kreis, Karsten and Aittala, Miika and Aila, Timo and Laine, Samuli and Catanzaro, Bryan and Karras, Tero and Liu, Ming-Yu},
journal={arXiv preprint arXiv:2211.01324},
year={2022}
}