


Abstract
We introduce Edify Image, a family of diffusion models capable of generating photorealistic image content with pixel-perfect accuracy. Edify Image utilizes cascaded pixel-space diffusion models trained using a novel Laplacian diffusion process, in which image signals at different frequency bands are attenuated at varying rates. Edify Image supports a wide range of applications, including text-to-image synthesis, 4K upsampling, ControlNets, 360° HDR panorama generation, and finetuning for image customization.
Dimension Varying EDM
Edify Image models are diffusion-based generators operating in pixel space. To tackle efficiency and controllability challenges for high-resolution content synthesis, we introduce a novel multi-scale diffusion process, termed the Laplacian Diffusion Model. This model simulates a resolution-varying diffusion process in the time domain by simultaneously decaying different image frequency bands at different rates.
The Image Laplacian Decomposition is a multi-scale representation technique that decomposes an image into a series of progressively lower-resolution images, capturing different frequency bands at each level. This hierarchical structure consists of a sequence of band-pass filtered images, where each level represents the difference between two successive versions of the original image.
We introduce our diffusion process, which is built upon image Laplacian decomposition using an intuitive approach. At its core, we explicitly control how image signals at different frequency bands are attenuated and synthesized at varying rates rather than entangling them together and allowing them to be corrupted through an implicit approach.
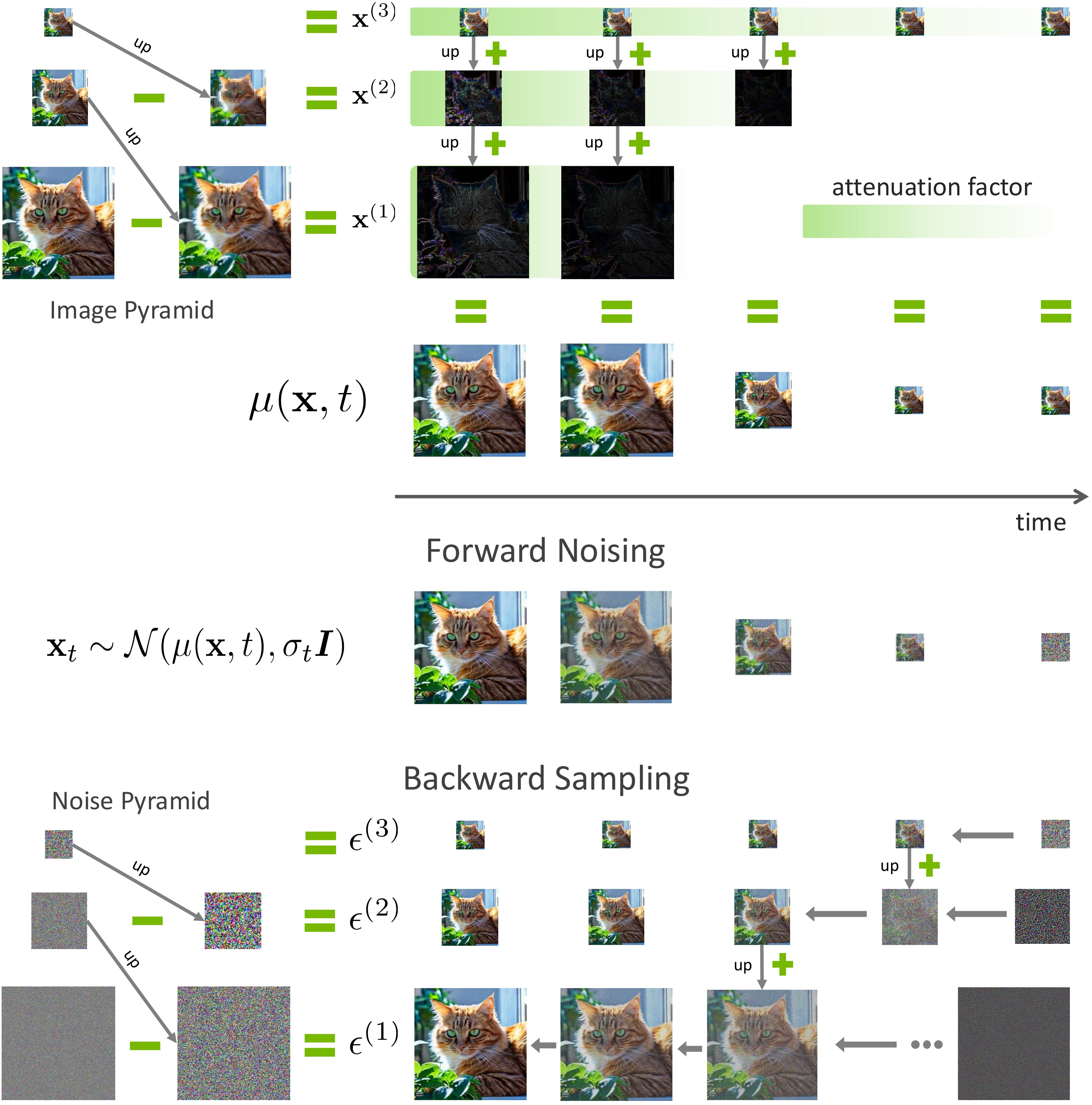
Laplacian Diffusion for Multi-Resolution Image Generation (Top) Image Laplacian Decomposition. Each image sample \({\mathbf{x}}\) can be decomposed into a set of components. The example shows three components: \({\mathbf{x}} = {\mathbf{x}}^{(1)} + \text{up}({\mathbf{x}}^{(2)}) + \text{up}(\text{up}({\mathbf{x}}^{(3)}))\). The function \(\mu({\mathbf{x}}, t)\) represents a weighted sum of these components across different frequency spaces. (Middle) Forward Noising Process. Components are attenuated at different rates, with higher frequencies attenuated more rapidly than lower ones. (Bottom) Backward Sampling Process. We decompose the noise into a noise Laplacian pyramid. The Laplacian Diffusion process synthesizes higher-resolution images by first upsampling a lower-resolution noisy sample and then denoising it, with random noise injected into the corresponding components during upsampling.
For diffusion forward process, the components in the high-frequency branch decay more rapidly than those in the lower-frequency branch, as illustrated in the image above. Laplacian Diffusion Models offer a flexible approach to synthesizing samples at various resolutions, thanks to the Laplacian decomposition and the utilization of a mixture of denoiser experts trained across different denoising ranges.
Two-stage Laplacian Diffusion Model
Architecture
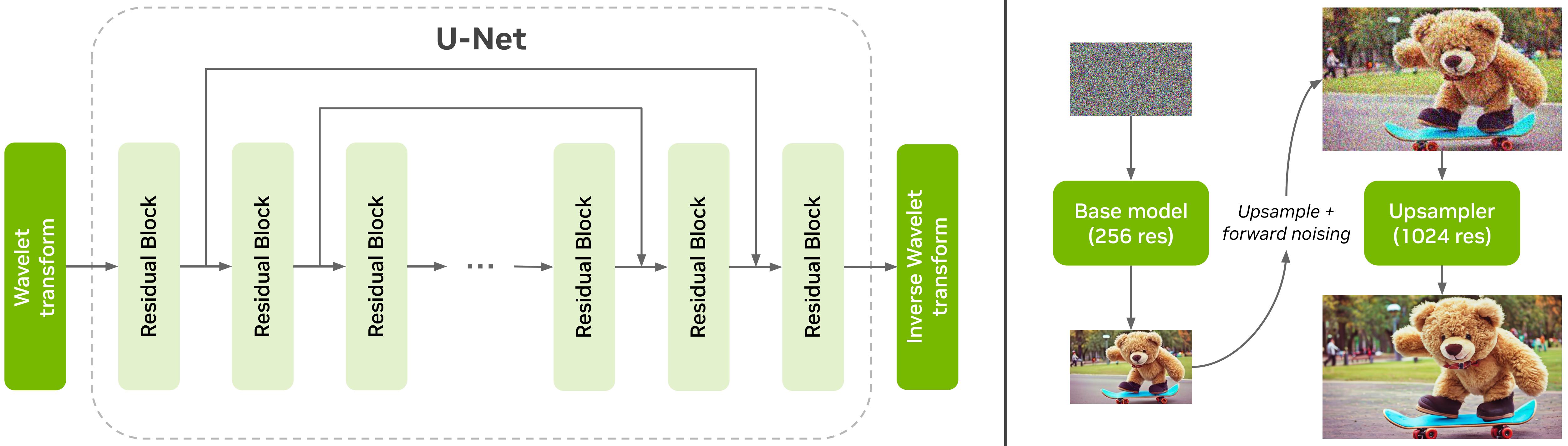
To generate images of \(1024\) resolution, we train a two-stage cascaded pixel-space diffusion model where the first model generates an image of \(256\) resolution while the second model upscales the image to \(1024\) resolution. Both models use a U-net architecture as shown below. We use wavelet and Inverse wavelet transform at the beginning and end of the network to bring down the spatial resolution of the images.
Conditioning Inputs
In addition to the text embeddings obtained from the T5-XXL model, we also condition our diffusion models on camera embeddings and media type. This allows users to generate images with better control. As shown below, generations from Edify Image can closely follow the pitch and depth of field that are provided in the input.
Descending view

Eye level view

Ascending view

Camera controls — Pitch
Shallow depth of field

Deep depth of field

Camera controls — Depth of field
Training Captions
To enable complex text understanding, we recaption the whole dataset using an LLM-based captioner for obtaining long descriptive captions. Our model is then trained using a combination of these descriptive AI captions and the original ground truth captions. Our model can generate images from long detailed captions as shown below.












\(4K\) Upsampling
Our Edify suite of image generation models also includes \(4K\) upsampling, which helps users generate highly detailed images. While the \(1K\) generator generates high-quality images with strong adherence to the input text prompts, the \(4K\) upsampler adds additional fine-grained details to the \(1K\) resolution image and outputs \(4K\) resolution images.
By scaling the noise levels appropriately, we can generate a high-quality \(4K\) image directly from a pre-trained \(1K\) generator. In the case of upsampling, similar to SDEdit, we can start with a low-resolution image, resize it to the desired resolution, add noise to it based on the forward diffusion process, and finally denoise it iteratively using our base \(1K\) model to obtain the upsampled image. We design the upsampler as a ControlNet which conditions the base model on the clean low-resolution input image. Finally, we fine-tune the base model with the low-resolution ControlNet on the \(4K\) images available to us.
Additionally, we utilize reconstruction guidance during sampling to further control the degree of change to the original low-resolution image. We share a few upsampled images compared with the low-resolution input image below.




Note: Please zoom in for more details.
Generation with Additional Control
We add additional control to the Edify Image model by training ControlNet encoders. After the base model is pre-trained, we freeze the model parameters and introduce an additional encoder whose parameters are partially initialized from the first half of the base model UNet.
The figure below shows example results with various control inputs. The model can generate high-quality images while following the image structure indicated by the control input.

Results with additional control inputs for inpainting, depth, and edge. For each input condition, we generate 3 variants using different text prompts.
360° HDR Panorama Generation
We developed a high-dynamic range (HDR) 360-degree panorama generator. Given a text prompt and (optionally) a corresponding example image from a single viewpoint, the system generates omnidirectional equirectangular projection panoramas at 4K, 8K, or 16K resolution.
The algorithm adopts a sequential inpainting approach in which a number of conventional perspective images are synthesized with the foundation model and stitched together, with overlap from preceding images, to ensure continuity. The inpainting is trained as a controlnet, with an image containing the overlap area providing the control signal. After we generate the panorama, we feed it to an LDR2HDR network to convert the low dynamic range (LDR) image to a high dynamic range (HDR) image.
The figure below shows the results for our panorama synthesis at 16k resolution. The input prompts are described under each image. We also show zoomed-in crops at the right to better show the details in the images.

(a) sunset at a lookout point in a gravel parking lot with blue sky and a few autumn maple trees and beautiful smokey mountains in the background, scenic nature, inspiring, landscape panoramic, mountains.

(b) flat sand beach by a lake in the swiss alps mountains at noon with beautiful swiss alps mountains in the background, god rays, scenic nature, inspiring, landscape panoramic.
(c) moss and grass plains in scottish highlands, scotland, remote, photography, wilderness, moody cloudy sky, rain, bluffs in background.
Finetuning
We propose an algorithm for finetuning the base text-to-image models on a small subset of reference images. Our model is especially capable of generating hyper-realistic humans with identities consistent to the reference set.




Single subject finetuning




Multi-subject finetuning


Contributors
Core contributors
Text-to-image model: Yogesh Balaji, Qinsheng Zhang, Jiaming Song, Ming-Yu Liu
Super-resolution: Ting-Chun Wang, Siddharth Gururani, Seungjun Nah, Ming-Yu Liu
ControlNets: Ting-Chun Wang, Yu Zeng, Grace Lam, Ming-Yu Liu
360° Panorama Generation: Ting-Chun Wang, J. P. Lewis, Seungjun Nah, Ming-Yu Liu
Finetuning: Jiaojiao Fan, Xiaohui Zeng, Yin Cui, Ming-Yu Liu
Data Processing: Jacob Huffman, Yunhao Ge, Siddharth Gururani, Fitsum Reda, Seungjun
Nah, Yin Cui, Arun Mallya, Ming-Yu Liu
Contributors
Yuval Atzmon, Maciej Bala, Tiffany Cai, Ronald Isaac, Pooya Jannaty, Tero Karras, Aaron Licata, Yen-Chen Lin, Qianli Ma, Ashlee Martino-Tarr, Doug Mendez, Chris Pruett, Fangyin Wei
Acknowledgements
We thank Andrea Gagliano, Bill Bon, Si Moran and Grant Farhall of Getty Images for providing useful feedback on our image generators. We also thank Dade Orgeron, Steve Chappell, Lucas Brown and Alex Ambroziak for providing feedback on our panorama generations. Special thanks to Timo Aila, Samuli Laine, Gal Chechik, Zekun Hao, Sanja Fidler and Jan Kautz for useful research discussions. We also thank Alessandro La Tona, Amol Fasale, Arslan Ali, Aryaman Gupta, Brett Hamilton, Sophia Huang, Devika Ghaisas, Gerardo Delgado Cabrera, Joel Pennington, Jason Paul, Jashojit Mukherjee, Jibin Varghese, Lyne Tchapmi, Mitesh Patel, Mohammad Harrim, Nathan Hayes-Roth, Raju Wagwani, Sydney Altobell, Thomas Volk and Vaibhav Ranglani for engineering and testing support. We are grateful to Fangyin Wei, Seungjun Nah, and Siddharth Gururani for providing their photos as the personalization finetuning data and to Yin Cui for taking the photos. We also thank the NVIDIA Creative team and Peter Pang for providing stylization finetuning data. Finally, we would like to thank Amanda Moran, John Dickinson, and Sivakumar Arayandi Thottakara for the computing infrastructure support.
Citation
Please cite as NVIDIA et al. using the following BibTex:
@article{nvidia2024edify2d,
title={Edify 2D: High-Quality Image Generation with Pixel Space Laplacian Diffusion Models},
author={NVIDIA and Atzmon, Yuval and Bala, Maciej and Balaji, Yogesh and Cai, Tiffany and Cui, Yin and Fan, Jiaojiao and Ge, Yunhao and Gururani, Siddharth and Huffman, Jacob and Isaac, Ronald and Jannaty, Pooya and Karras, Tero and Lam, Grace and Lewis, J. P. and Licata, Aaron and Lin, Yen-Chen and Liu, Ming-Yu and Ma, Qianli and Mallya, Arun and Martino-Tarr, Ashlee and Mendez, Doug and Nah, Seungjun and Pruett, Chris and Reda, Fitsum and Song, Jiaming and Wang, Ting-Chun and Wei, Fangyin and Zeng, Xiaohui and Zeng, Yu and Zhang, Qinsheng},
journal={arXiv preprint arXiv:2411.07126},
year={2024}
}