Abstract
Generative video-to-audio (V2A) models produce highly plausible soundtracks, but it remains unclear whether they capture the underlying physical processes. Existing evaluations emphasize perceptual realism and overlook physical correctness under controlled interventions. In this paper, we introduce FlatSounds, a benchmark that audits the physical reasoning of V2A models through: 1) controlled counterfactual pairs in which a single physical factor is varied, and 2) single-video pattern tests that probe internal consistency and directional trends. These settings test whether generated audio correctly reflects specific physical properties and timings. Our evaluation of state-of-the-art models reveals a consistent trade-off: models rely more on text captions than the visual stream to infer physics and semantics. Captions improve physical and semantic accuracy, but paradoxically degrade temporal alignment. Our results highlight the need to move beyond audio quality toward learning physical processes directly from pixels. Finally, we find that our physics-based metrics correlate strongly with human preference tests on our own data.
The Physics of Sound
To understand the gap between "plausible" audio and "physically correct" audio, we present four case studies using real-world samples from FlatSounds. The first three are counterfactual pairs: time-aligned videos where only one physical factor changes, allowing us to isolate its acoustic effect. The fourth is a single-video pattern test that probes the directional trend.
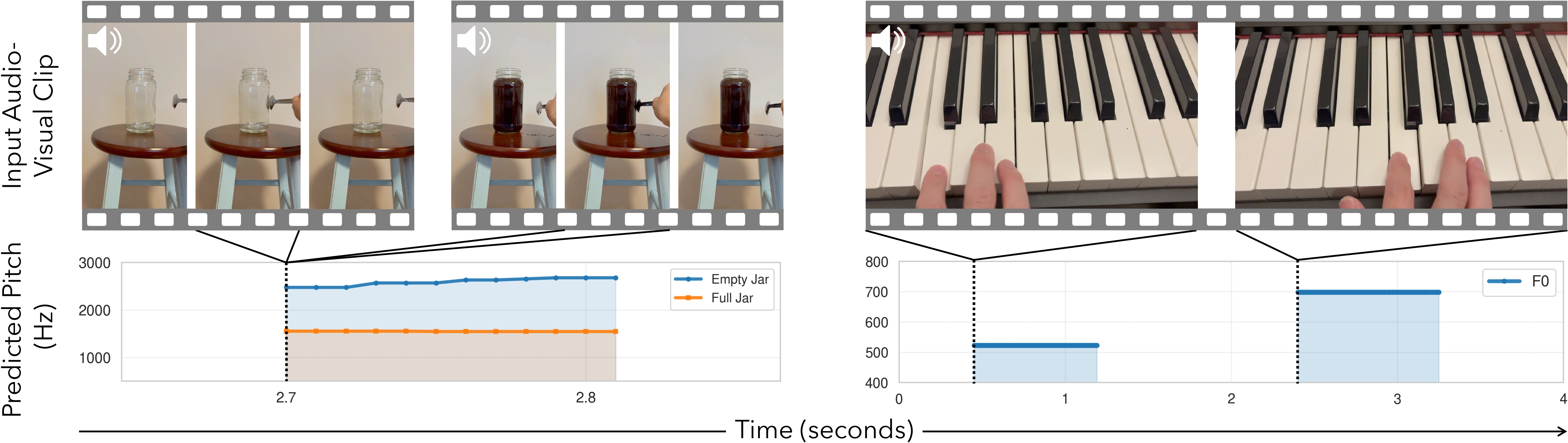
Case 1: Fullness
Variable: Jar fullness (empty → full)
The Physics: Increasing mass lowers the resonant frequency. A full jar should produce a noticeably lower pitch (F0 ↓) compared to an empty jar.
Listen for: A clear pitch drop when the full jar is tapped (right video).
Empty Jar
Higher pitch (F0)
Full Jar
Lower pitch (F0)
Case 2: Damping
Variable: Metal stick configuration (free-hanging → surface-constrained)
The Physics: A free-hanging stick rings longer (low decay rate). When constrained to a surface, damping increases, causing faster decay and a duller timbre (Spectral Centroid ↓, Decay Rate ↑).
Listen for: A bright, sustained ring (left) vs. a short, muted thud (right).
Free-Hanging
Long decay, bright tone
Surface-Constrained
Fast decay, dull tone
Case 3: Environment
Variable: Acoustic environment (hallway → cushioned room)
The Physics: A hallway has hard surfaces that reflect sound, creating long reverberation (high RT60). A cushioned room absorbs sound, reducing echo (RT60 ↓, DRR ↑).
Listen for: Spacious echo (left) vs. dry, intimate clap (right).
Hallway
Long reverb (RT60)
Cushioned Room
Short reverb (RT60)
Case 4: Directional Trends
Variable: Piano key position (ascending)
The Physics: As the hand moves rightward across the keyboard, the pitch (F0) must strictly increase.
Listen for: A coherent rising scale, not random piano notes.
Ascending Piano Scale
F0 must increase monotonically
Counterfactual Pairs Showcase
We present time-aligned video pairs where a single physical variable is manipulated. By warping the videos to align impact timings, we can directly attribute acoustic differences to the controlled factor.
Scraping Surface
Variable: Scraped surface (cardboard → metal)
Expected: Metal produces brighter and harsher sounds (Spectral Centroid ↑, Spectral Flux ↑, Spectral Rolloff ↑).
Note: Same visual, two audio recordings. Click to switch.
Cardboard (left) vs. Metal (right)
Surface Texture
Variable: Surface texture (wooden floor → carpet)
Expected: Carpet produces softer, duller sounds with faster decay (Spectral Centroid ↓, Decay Rate ↑, Spectral Rolloff ↓).
Note: Same striker, time-aligned impacts.
Wooden Floor (left) vs. Carpet (right)
Striker Material
Variable: Striker material (metal spoon → wooden stick)
Expected: Wood produces softer attack and duller tone (Attack Time ↑, Spectral Centroid ↓, Spectral Rolloff ↓).
Note: Same wooden surface, time-aligned impacts.
Metal Spoon (left) vs. Wooden Stick (right)
Video Examples
We show generated audio samples from state-of-the-art V2A models across clips from FlatSounds. Use the filters to compare how different models perform with and without text captions.
Select a sample
Quantitative Results
Trade-off Analysis: Semantics & Physics vs. Temporal
We visualize the trade-off between Temporal Alignment (x-axis) and Physical-Semantic Fidelity (y-axis). Lines connect the performance of models without captions (open markers) to those with captions (filled markers).
Observation: The trajectory from no-caption to caption typically moves up (improved fidelity) but left (degraded alignment).
Holistic Physical Evaluation
We present a multi-dimensional evaluation of physical audio attributes across nine distinct metrics. Spikes reaching further outward indicate better performance.
Citation
@inproceedings{li2026flatsounds,
title={Benchmarking Single-Factor Physical Video-to-Audio Generation},
author={Li, Tingle and Gururani, Siddharth and Shih, Kevin and Bhatt, Gantavya and Lee, Sang-gil and Kong, Zhifeng and Goel, Arushi and Anumanchipalli, Gopala and Liu, Ming-Yu},
booktitle={IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2026}
}