Abstract
Many sparse attention mechanisms such as Neighborhood Attention have typically failed to consistently deliver speedup over the self attention baseline. This is largely due to the level of complexity in attention infrastructure, and the rapid evolution of AI hardware architecture. At the same time, many state-of-the-art foundational models, particularly in computer vision, are heavily bound by attention, and need reliable sparsity to escape the O(n²) complexity. In this paper, we study a class of promising sparse attention mechanisms that focus on locality, and aim to develop a better analytical model of their performance improvements. We first introduce Generalized Neighborhood Attention (GNA), which can describe sliding window, strided sliding window, and blocked attention. We then consider possible design choices in implementing these approaches, and create a simulator that can provide much more realistic speedup upper bounds for any given setting. Finally, we implement GNA on top of a state-of-the-art fused multi-headed attention (FMHA) kernel designed for the NVIDIA Blackwell architecture in CUTLASS. Our implementation can fully realize the maximum speedup theoretically possible in many perfectly block-sparse cases, and achieves an effective utilization of 1.3 petaFLOPs/second in FP16. In addition, we plug various GNA configurations into off-the-shelf generative models, such as Cosmos-7B, HunyuanVideo, and FLUX, and show that it can deliver 28% to 46% end-to-end speedup on B200 without any fine-tuning. We will open source our simulator and Blackwell kernels directly through the NATTEN project.
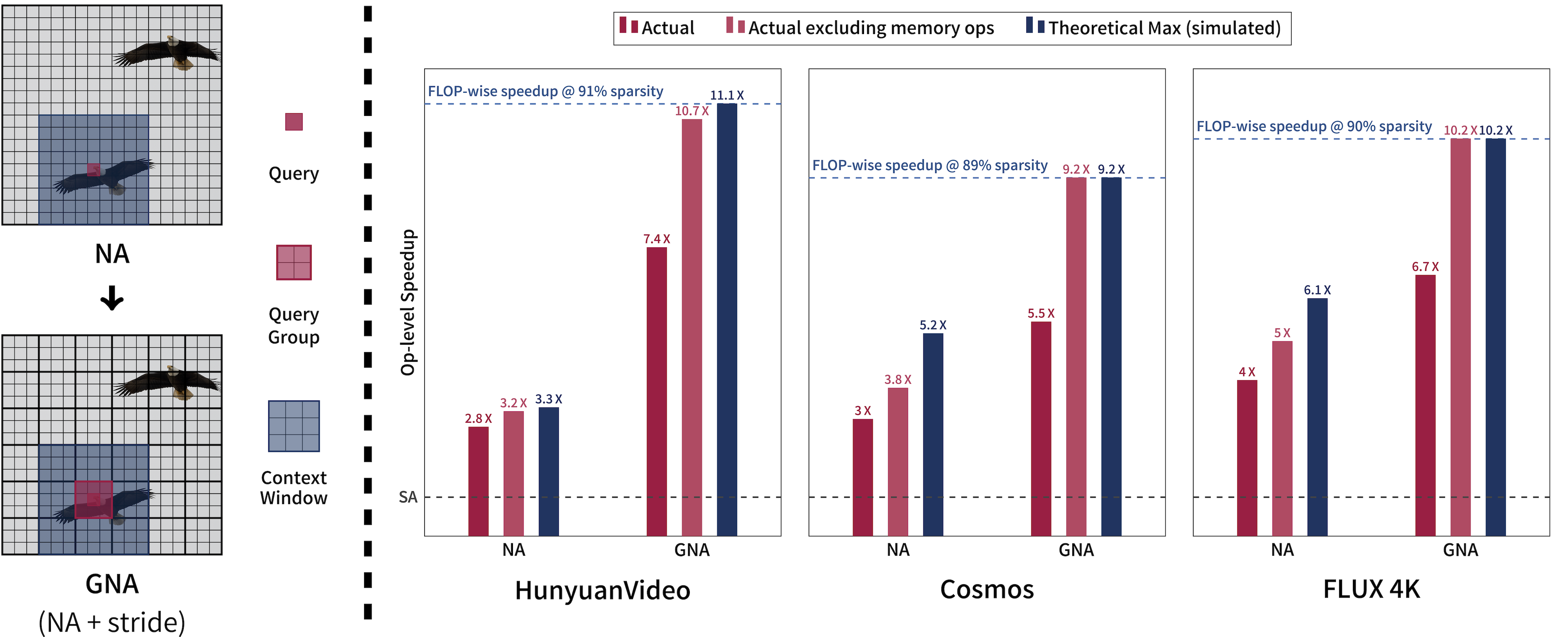
Generalized Neighborhood Attention adds a new "stride" parameter to neighborhood attention, which introduces a delay in the sliding window by grouping queries together and forcing them to share their context window. This increases density in matrix multiplications, while maintaining overall sparsity, leading to speedups more proportional to savings in FLOPs. Our Blackwell kernel can as a result realize the maximum speedup theoretically possible in some cases, with respect to both FLOPs and simulation.
GNA: multiple attention patterns unified as one
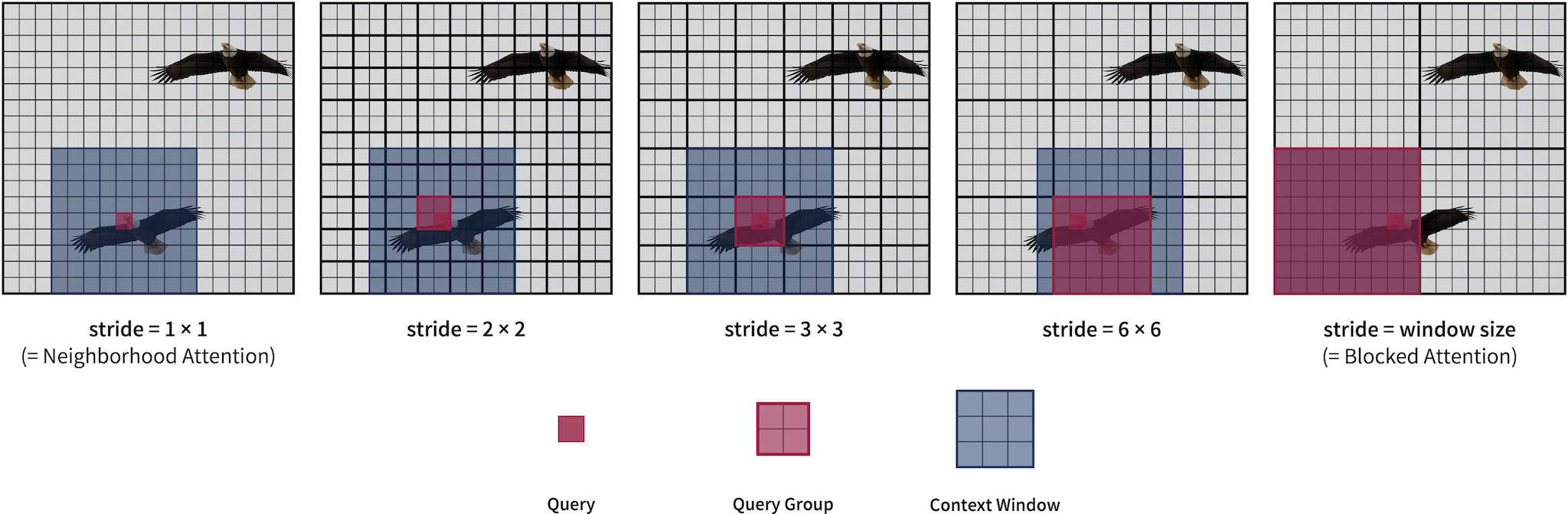
Generalized Neighborhood Attention allows customizable "delay steps" in the sliding window pattern through the new stride parameter. Stride can take any positive integer value smaller than or equal to window size.
- Stride 1 is equivalent to standard neighborhood attention.
- When stride is equal to window size, it is equivalent to blocked attention (a.k.a. Window Self Attention).
- All other values are instances of strided sliding window attention (i.e. HaloNet's blocked local attention).
NATTENSim: analytical performance model
Given GNA's massively large parameter space for any given use case, we create a tool for simulating the behavior of different kernels, calculating actual tile-wise savings as opposed to FLOP-wise savings. This tool can also further prune undesirable settings in which larger strides do not improve performance, and only focus on settings that offer speedup over smaller strides.
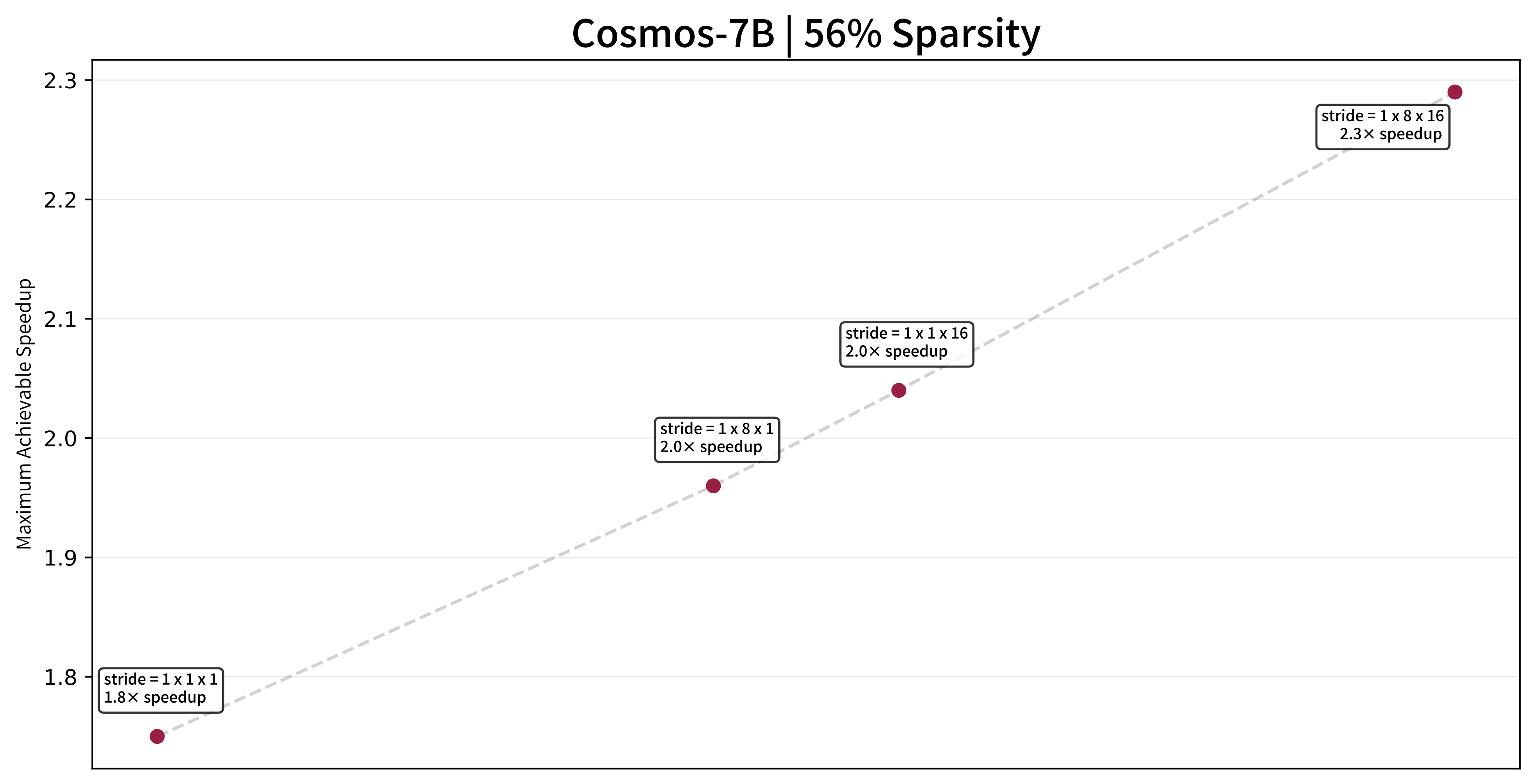
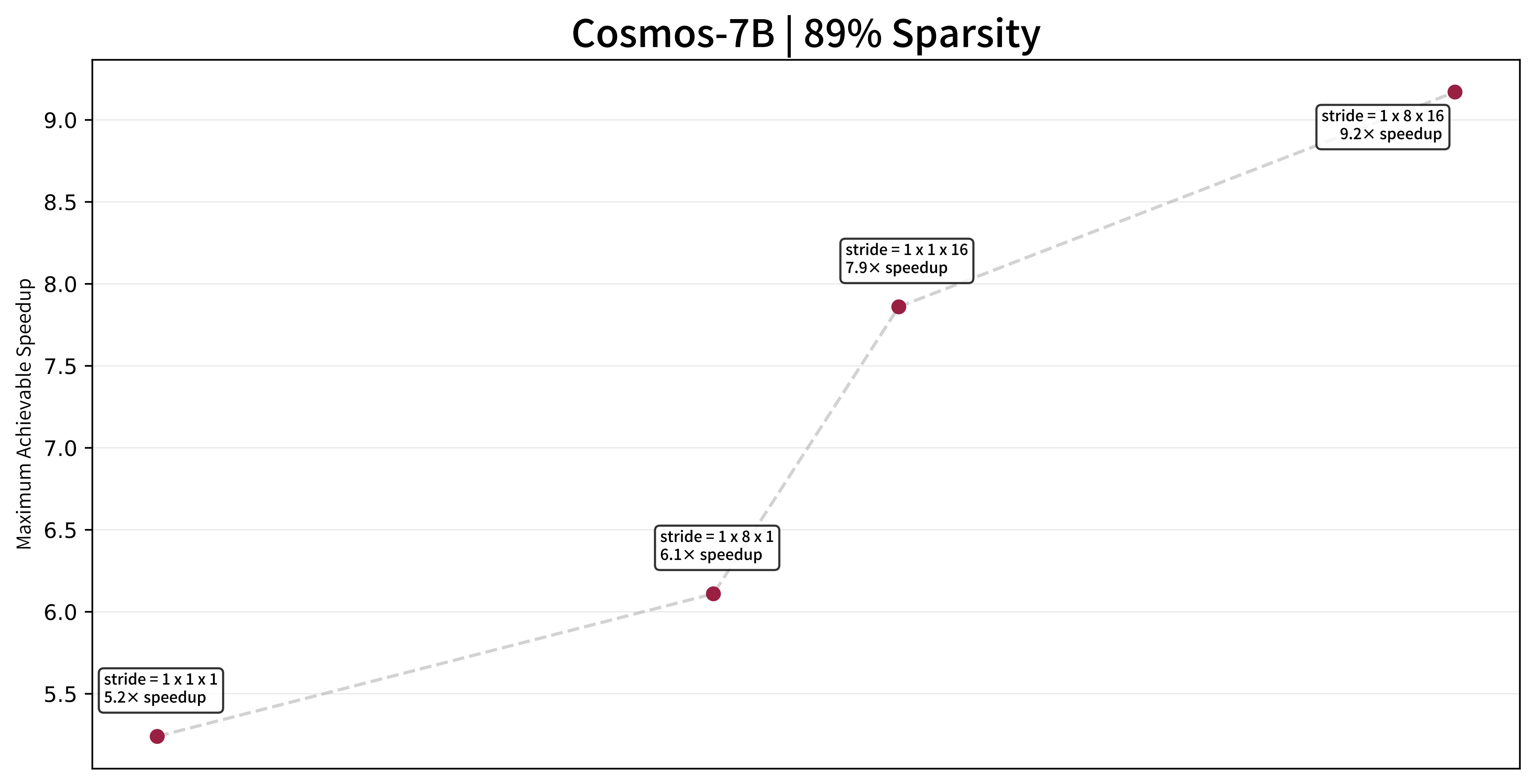
NATTEN for Blackwell
In addition to adding GNA's stride parameter to the existing infrastructure in NATTEN, we also implemented a GNA kernel for the NVIDIA Blackwell architecture, which can in many cases realize the maximum speedup theoretically possible, both with respect to our simulation, and with respect to reduction in FLOPs.
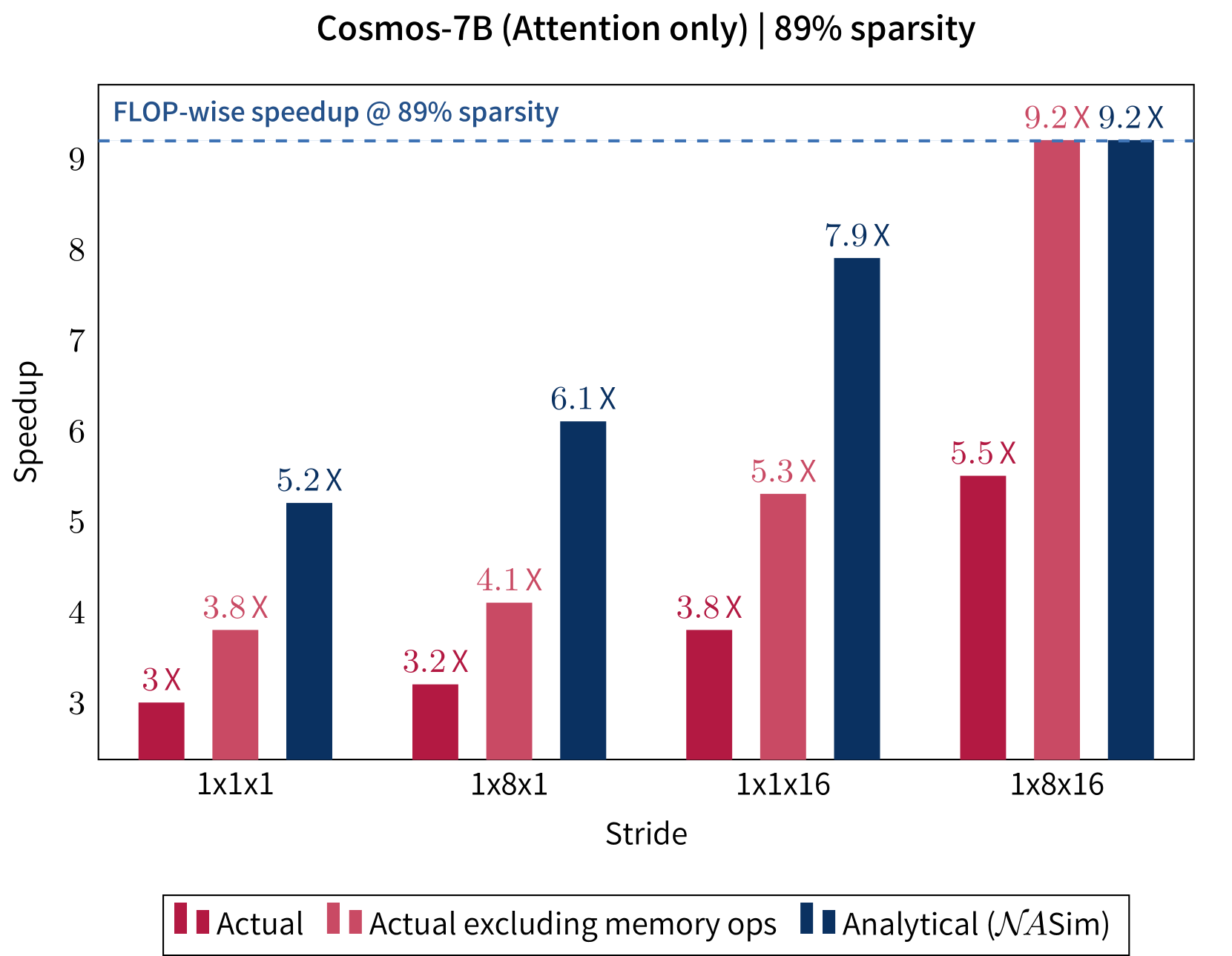
We also apply GNA directly to foundation models, such as Cosmos, and speed up the model while maintaining generation quality without any fine-tuning. This is done by retaining diffusion steps with full self attention, and tuning for the maximum sparsity the model can tolerate.

Sample frames from videos generated by Cosmos-7B, with GNA introduced into the last 23 of the 35 diffusion steps. Window size is 16 × 32 × 48 (≈ 56% sparsity). Maximum speedup achievable under this setting, with the same level of sparsity, is 1.28×.
Citation
@article{hassani2025generalized,
title={Generalized Neighborhood Attention: Multi-dimensional Sparse Attention at the Speed of Light},
author={Hassani, Ali and Zhou, Fengzhe and Kane, Aditya and Huang, Jiannan and Chen, Chieh-Yun and Shi, Min and Walton, Steven and Hoehnerbach, Markus and Thakkar, Vijay and Isaev, Michael and Zhang, Qinsheng and Xu, Bing and Wu, Haicheng and Hwu, Wen-mei and Liu, Ming-Yu and Shi, Humphrey},
year={2025},
journal={arXiv preprint arXiv:2504.16922}
}