
Abstract
Visual AutoRegressive modeling (VAR) has shown promise in bridging the speed and quality gap between autoregressive image models and diffusion models. VAR reformulates autoregressive modeling by decomposing an image into successive resolution scales. During inference, an image is generated by predicting all the tokens in the next (higher-resolution) scale, conditioned on all tokens in all previous (lower-resolution) scales. However, this formulation suffers from reduced image quality due to parallel generation of all tokens in a resolution scale; has sequence lengths scaling superlinearly in image resolution; and requires retraining to change the sampling schedule.
We introduce Hierarchical Masked AutoRegressive modeling (HMAR), a new image generation algorithm that alleviates these issues using next-scale prediction and masked prediction to generate high-quality images with fast sampling. HMAR reformulates next-scale prediction as a Markovian process, wherein prediction of each resolution scale is conditioned only on tokens in its immediate predecessor instead of the tokens in all predecessor resolutions. When predicting a resolution scale, HMAR uses a controllable multi-step masked generation procedure to generate a subset of the tokens in each step. On ImageNet 256×256 and 512×512 benchmarks, HMAR models match or outperform parameter-matched VAR, diffusion, and autoregressive baselines. We develop efficient IO-aware block-sparse attention kernels that allow HMAR to achieve faster training and inference times over VAR by over 2.5× and 1.75× respectively, as well as over 3× lower inference memory footprint.
HMAR Pipeline
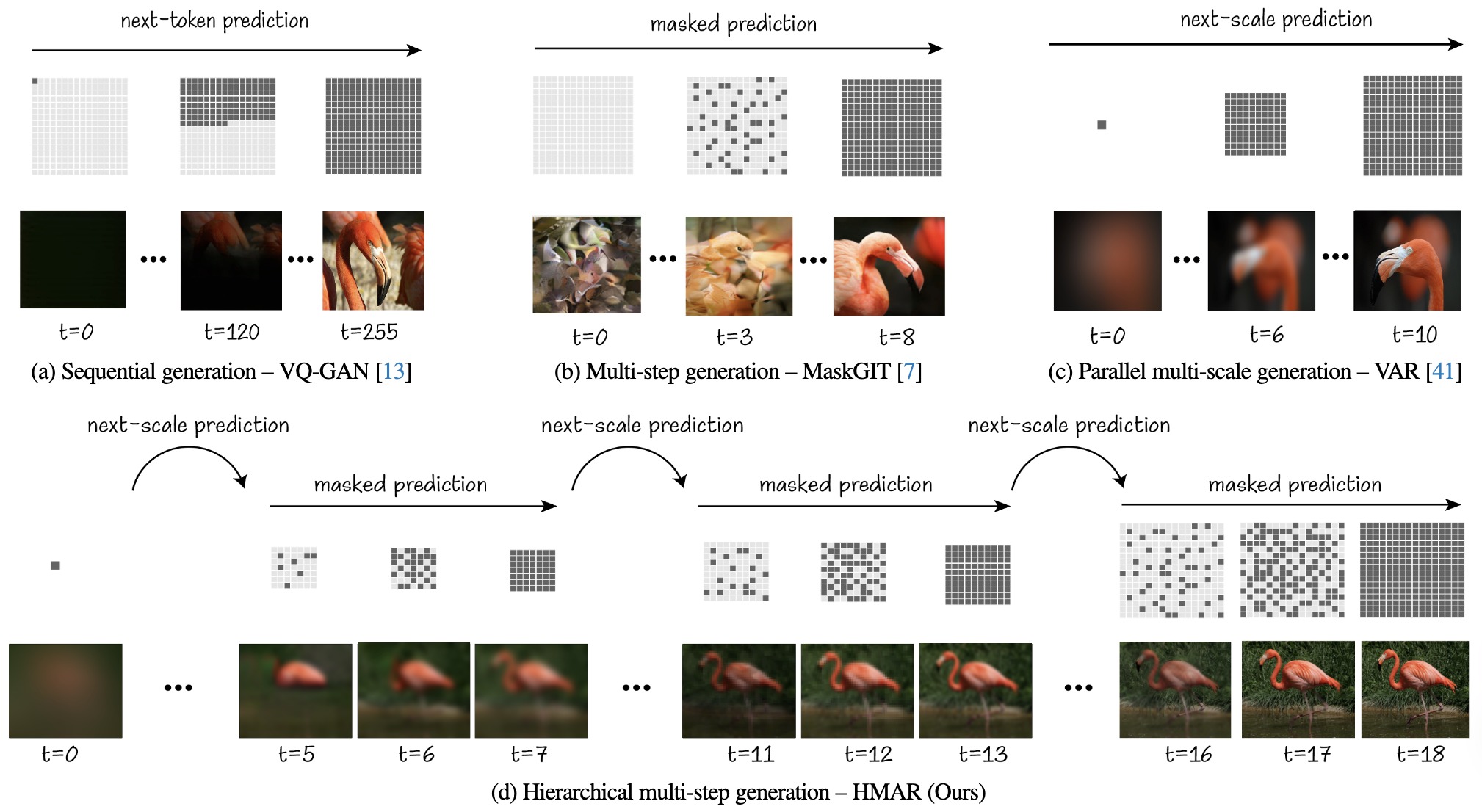
HMAR generates images in an iterative two-step process by first producing a rough prediction of the next scale, then refining it using multi-step masked prediction until the final scale is reached. In addition, in HMAR we only condition on the previous scale instead of all the preceding ones. This allows HMAR to improve over VAR in terms of quality, efficiency and flexibility.
Quality
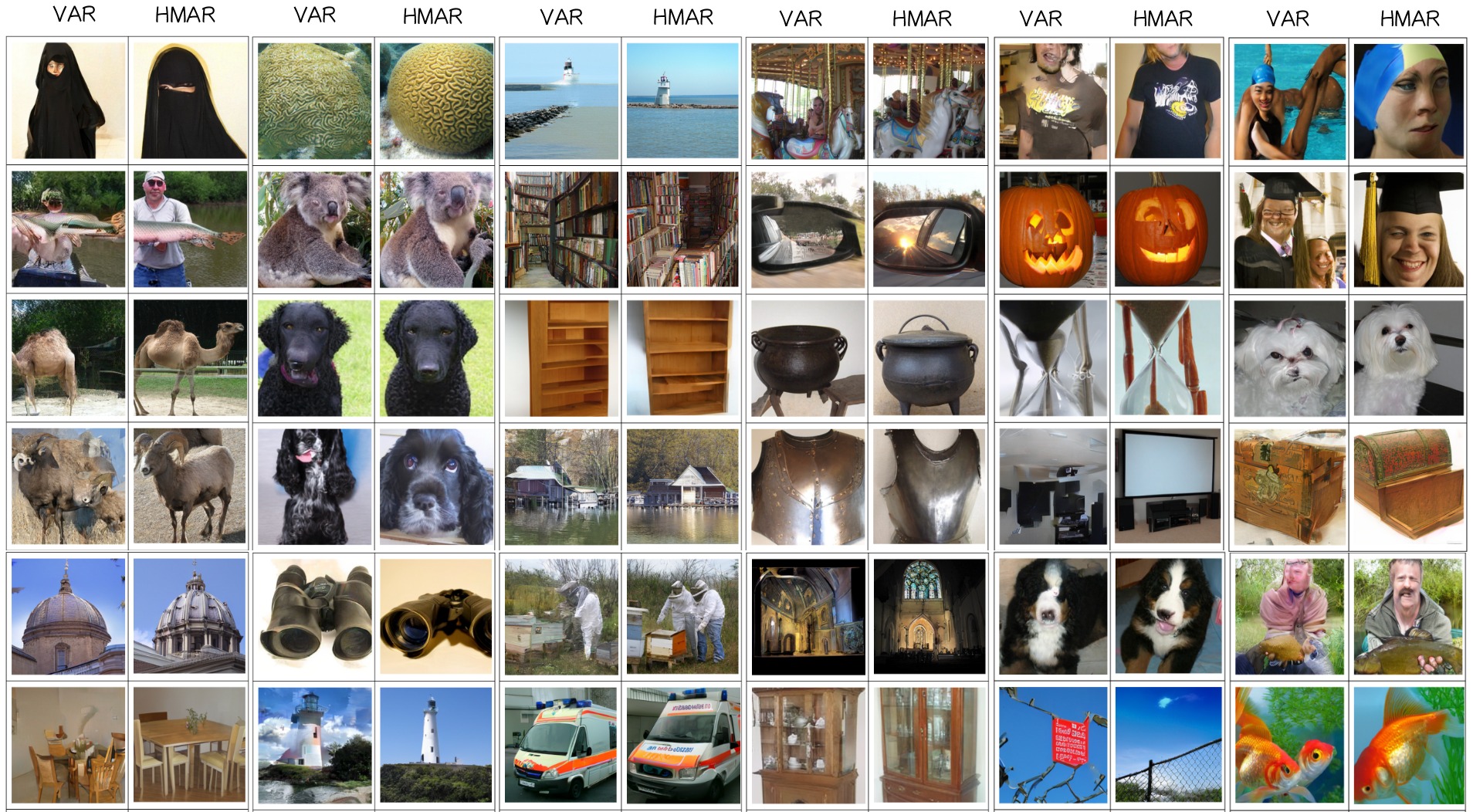
Examples demonstrating how HMAR's multi-step generation approach at each scale can enhance image quality, offering superior results when compared to relying solely on next-scale prediction in VAR.
Flexibility
Application to Image Editing

HMAR can be adapted to image editing tasks like in-painting, out-painting and class conditional editing without additional training.
Adjustable Sampling

HMAR offers flexible sampling capabilities, allowing us to adjust the number of sampling steps to enhance quality without the need for retraining the model from scratch. We can simply increase the number of masked sampling steps at each scale.
Performance
Faster Inference, Faster Training, Lower Memory
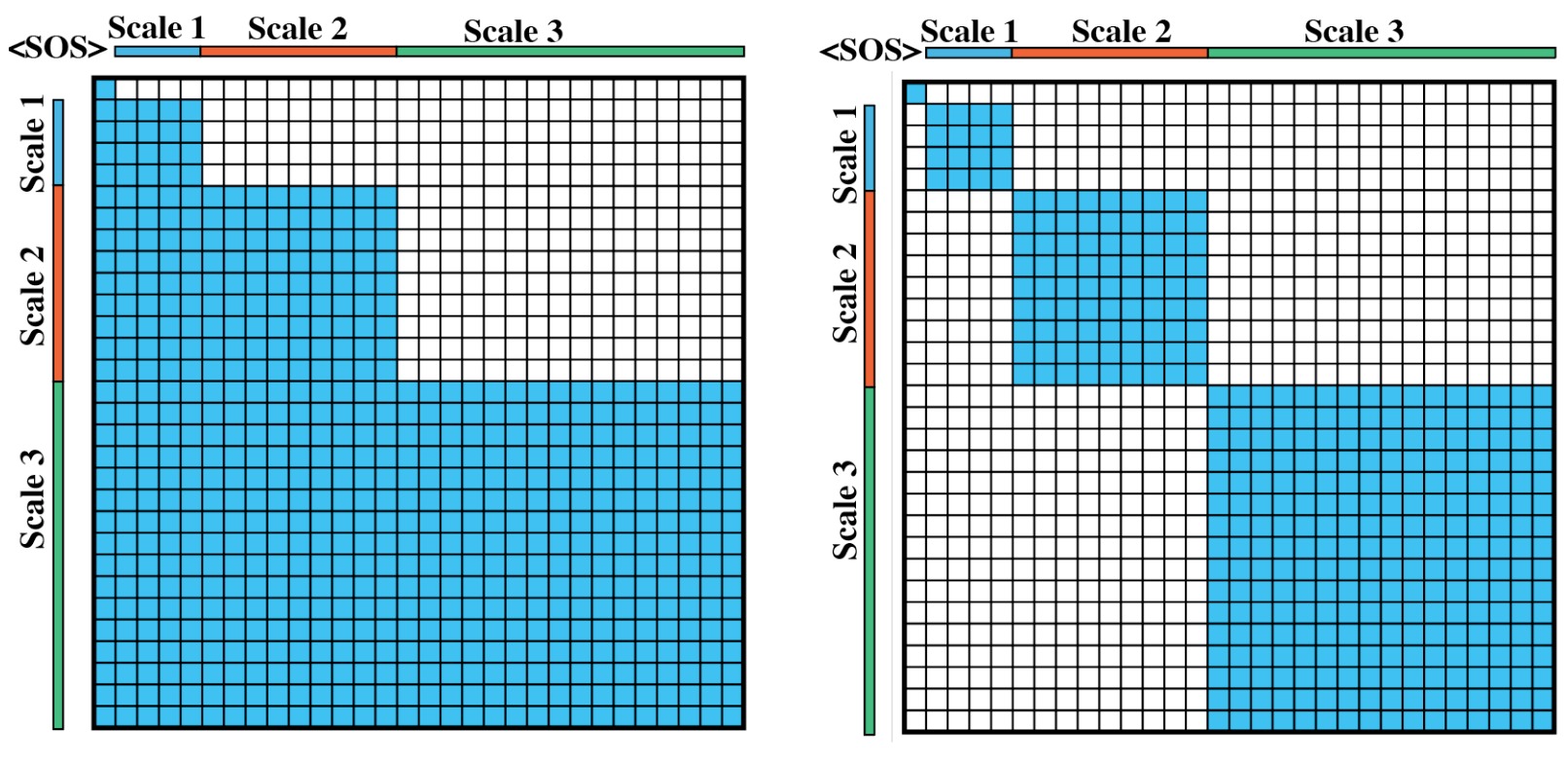
Comparing the attention masks in HMAR and VAR. HMAR leverages a sparse block-diagonal attention mask which is more efficient than the block-causal attention mask in VAR.
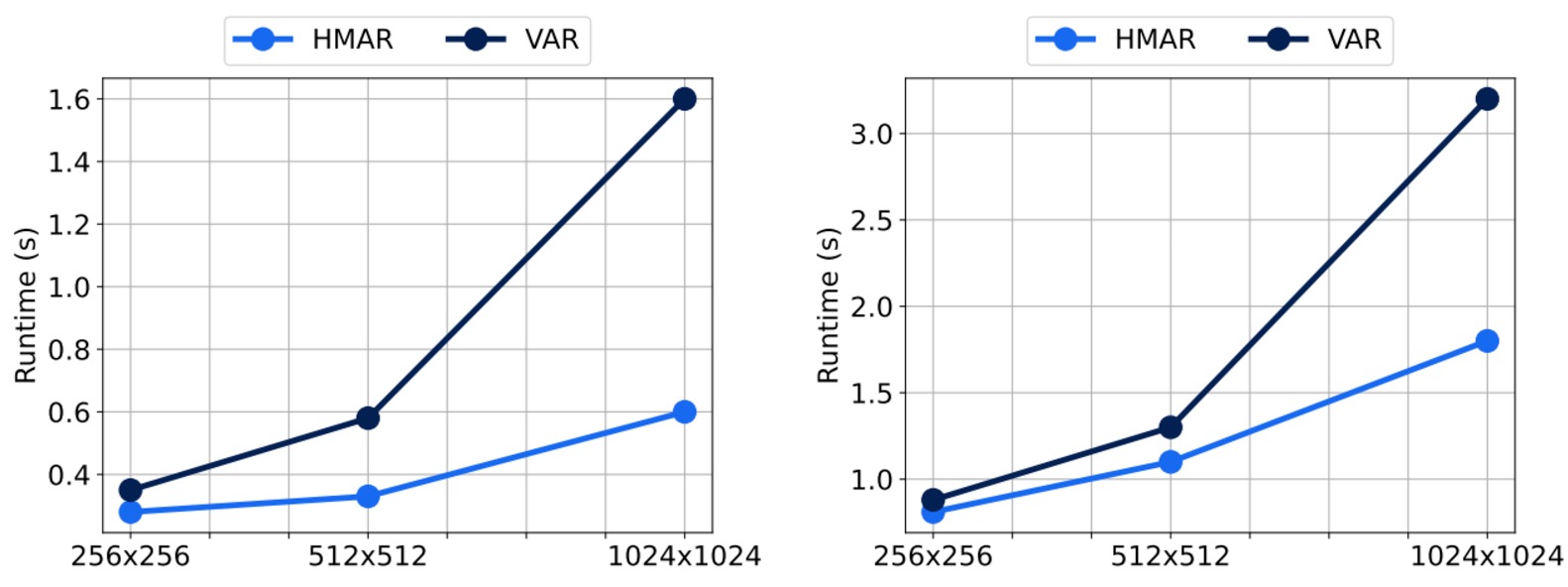
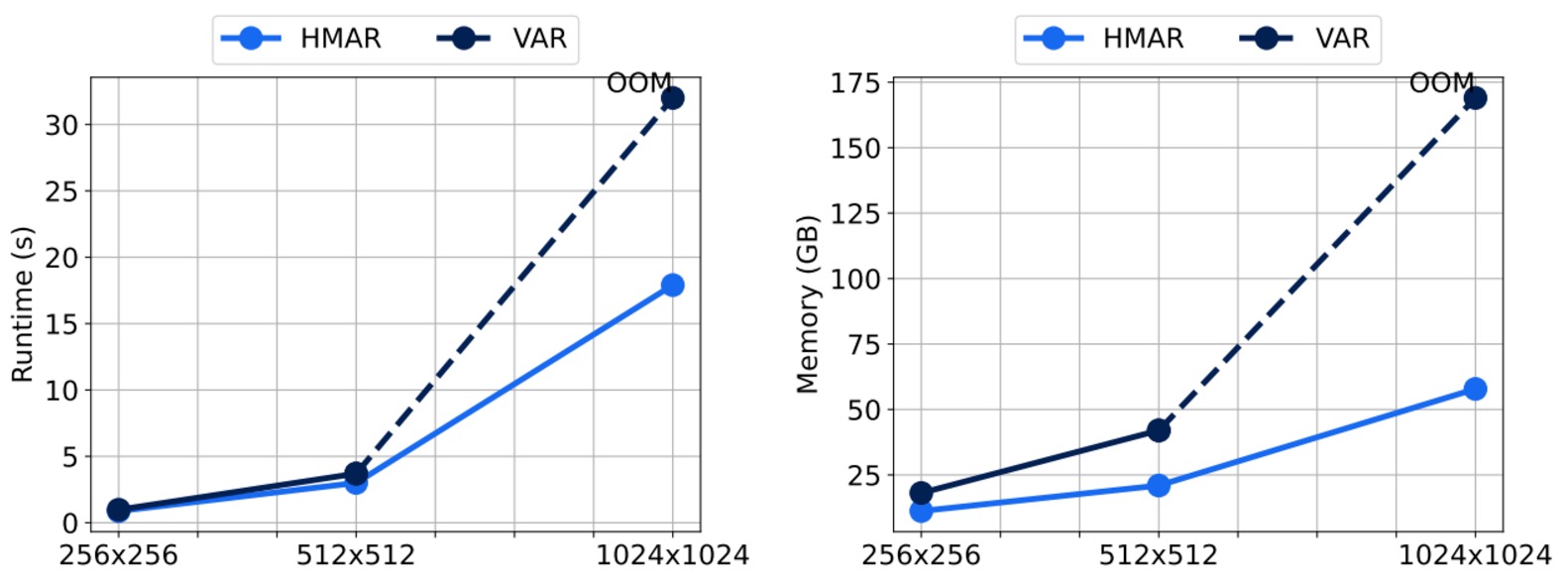
HMAR improves the next-scale prediction from VAR to condition only on the immediate predecessor, as a result this reduces the sequence length required during inference, hence leading to faster inference and a reduced memory footprint with the efficiency gains increasing as we scale up to higher resolutions. This also provides us with a much sparse attention mask which we leverage via custom attention kernels to speedup training.
Speedy Attention Kernels
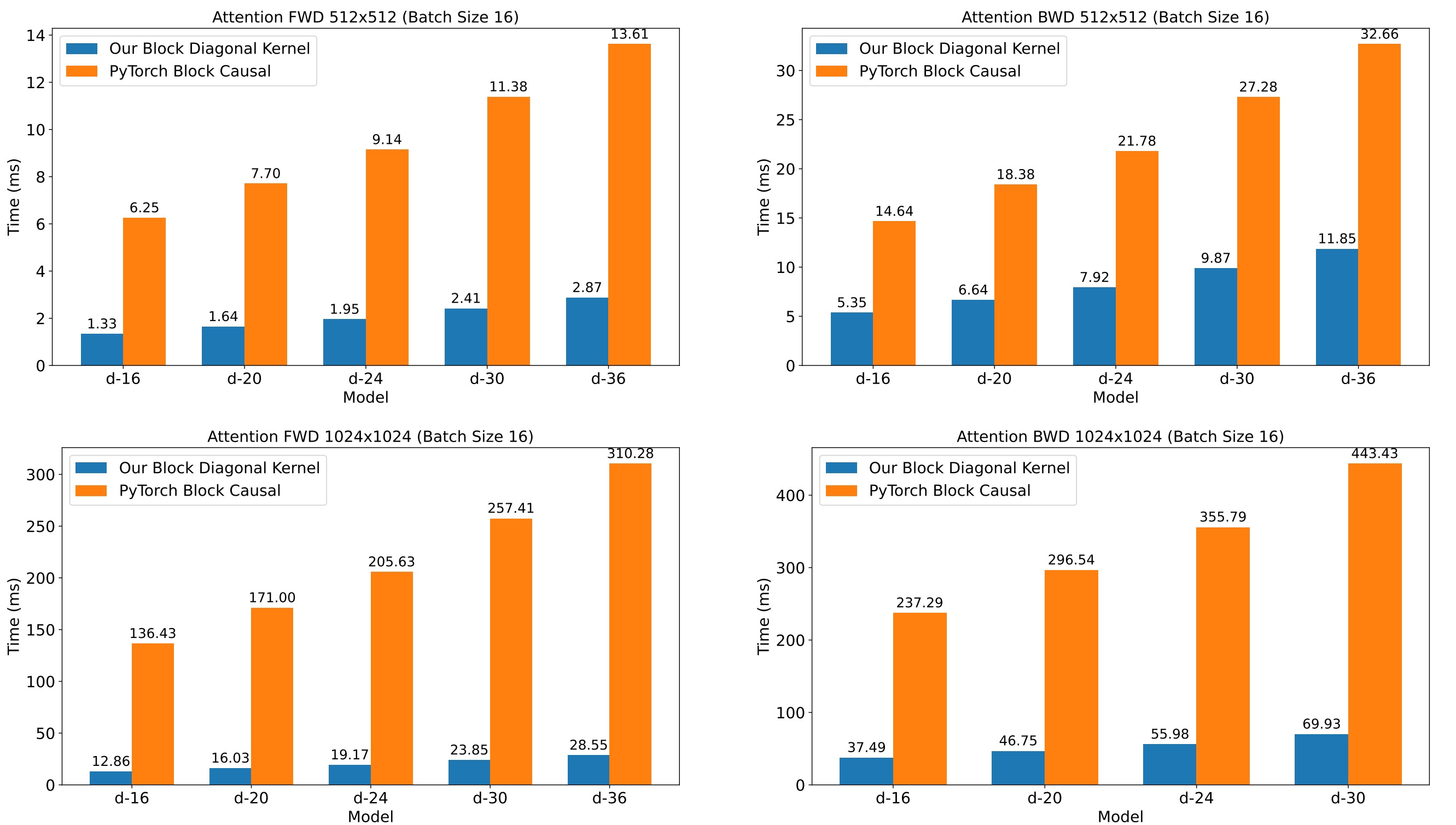
The block-causal attention pattern in VAR and the block-diagonal attention pattern in HMAR are not supported by efficient attention implementations like FlashAttention. We provide efficient attention kernels to speed up training HMAR models.
Citation
@inproceedings{kumbong2025hmar,
title={HMAR: Efficient Hierarchical Masked AutoRegressive Image Generation},
author={Kumbong, Hermann and Liu, Xian and Lin, Tsung-Yi and Liu, Xihui and Liu, Ziwei and Fu, Daniel Y and Liu, Ming-Yu and Re, Christopher and Romero, David W},
booktitle={IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2025}
}