Introduction
Both text-to-image generation and large language models (LLMs) have made significant advancements. However, many text-to-image models still employ the somewhat outdated T5 and CLIP as their text encoders. In this work, we investigate the effectiveness of using modern decoder-only LLMs as text encoders for text-to-image diffusion models.
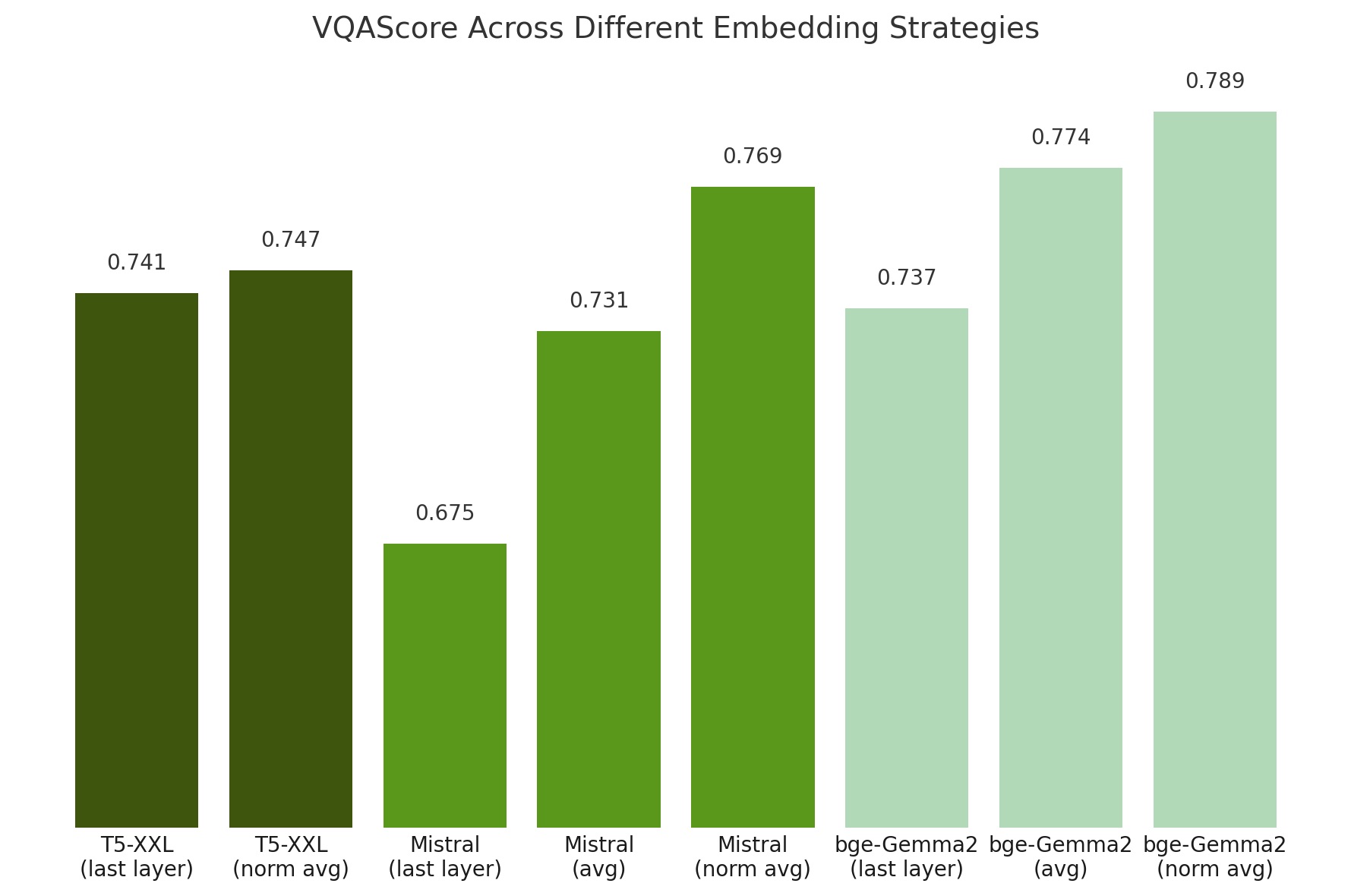
Our experiments reveal that the de facto way of using last-layer embeddings as conditioning leads to inferior performance. Instead, we explore embeddings from various layers and find that using layer-normalized averaging across all layers significantly improves alignment with complex prompts. Most LLMs with this conditioning outperform the baseline T5 model, showing enhanced performance in advanced visio-linguistic reasoning skills.
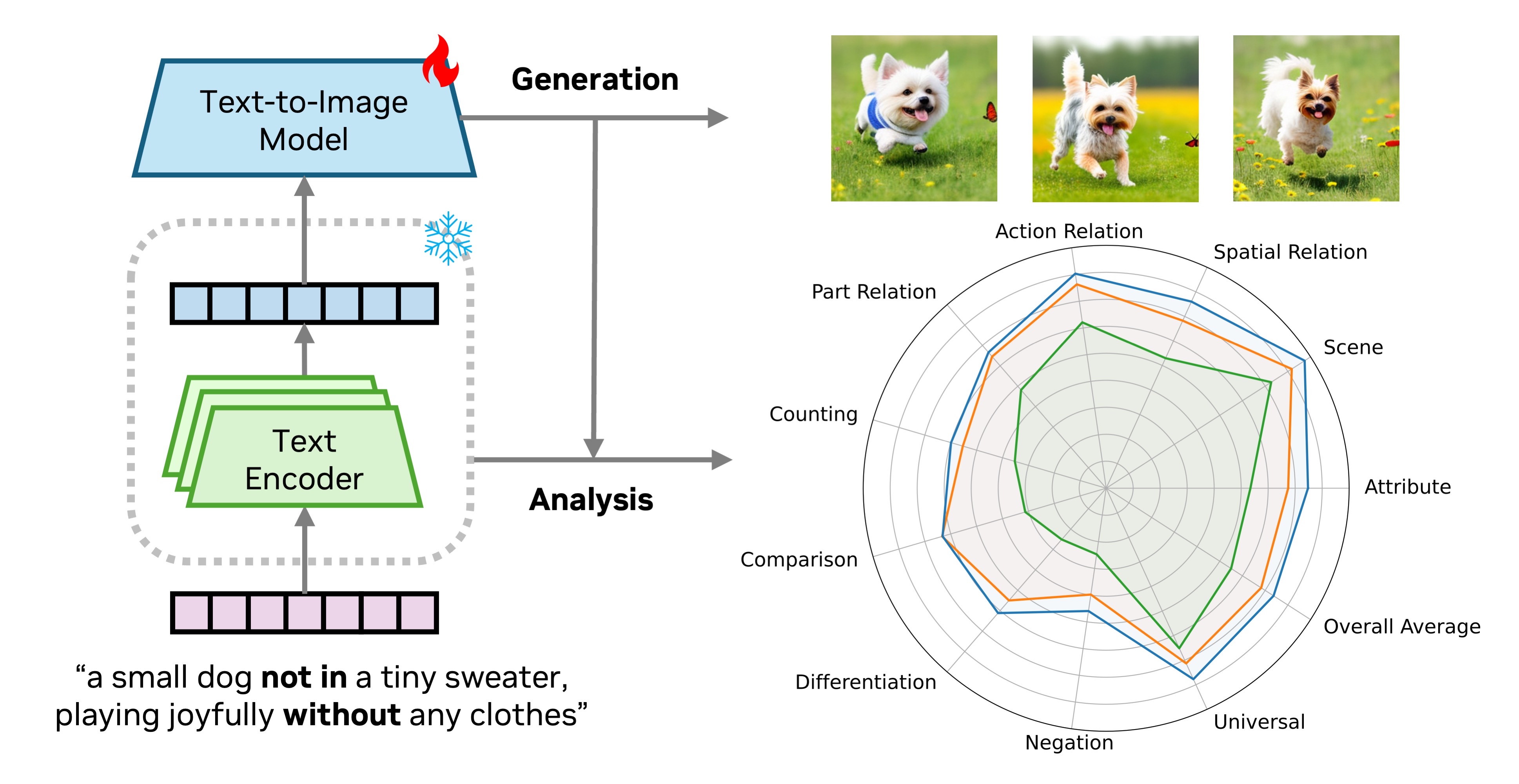
CLIP (last layer)

T5 (last layer)

Mistral (norm avg)

Bge-Gemma2 (norm avg)

A small dog not in a tiny sweater, playing joyfully without any clothes. The fluffy white dog, with big brown eyes and floppy ears, bounds through a sun-drenched field of wildflowers. Its tongue lolls out in pure happiness as it chases a bright red butterfly, its tiny paws barely touching the ground.
Key Findings
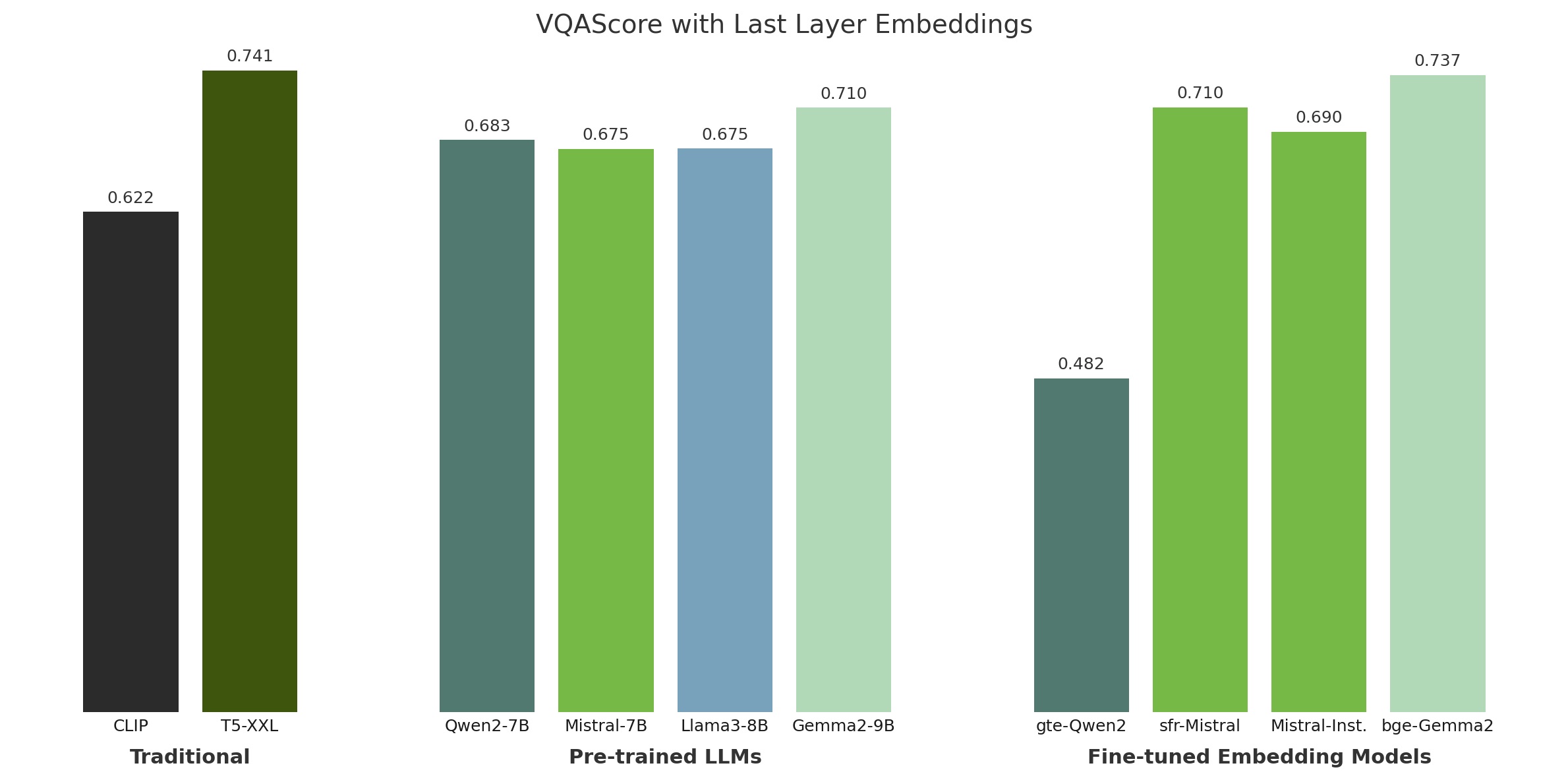
Using text embeddings from the last layer of the LLM is suboptimal
To our knowledge, all current text-to-image diffusion models utilize the embeddings from the final layer of the text encoders as the conditional embedding. However, our results reveal that this approach does not translate effectively to LLMs, leading to inferior results compared to using T5.
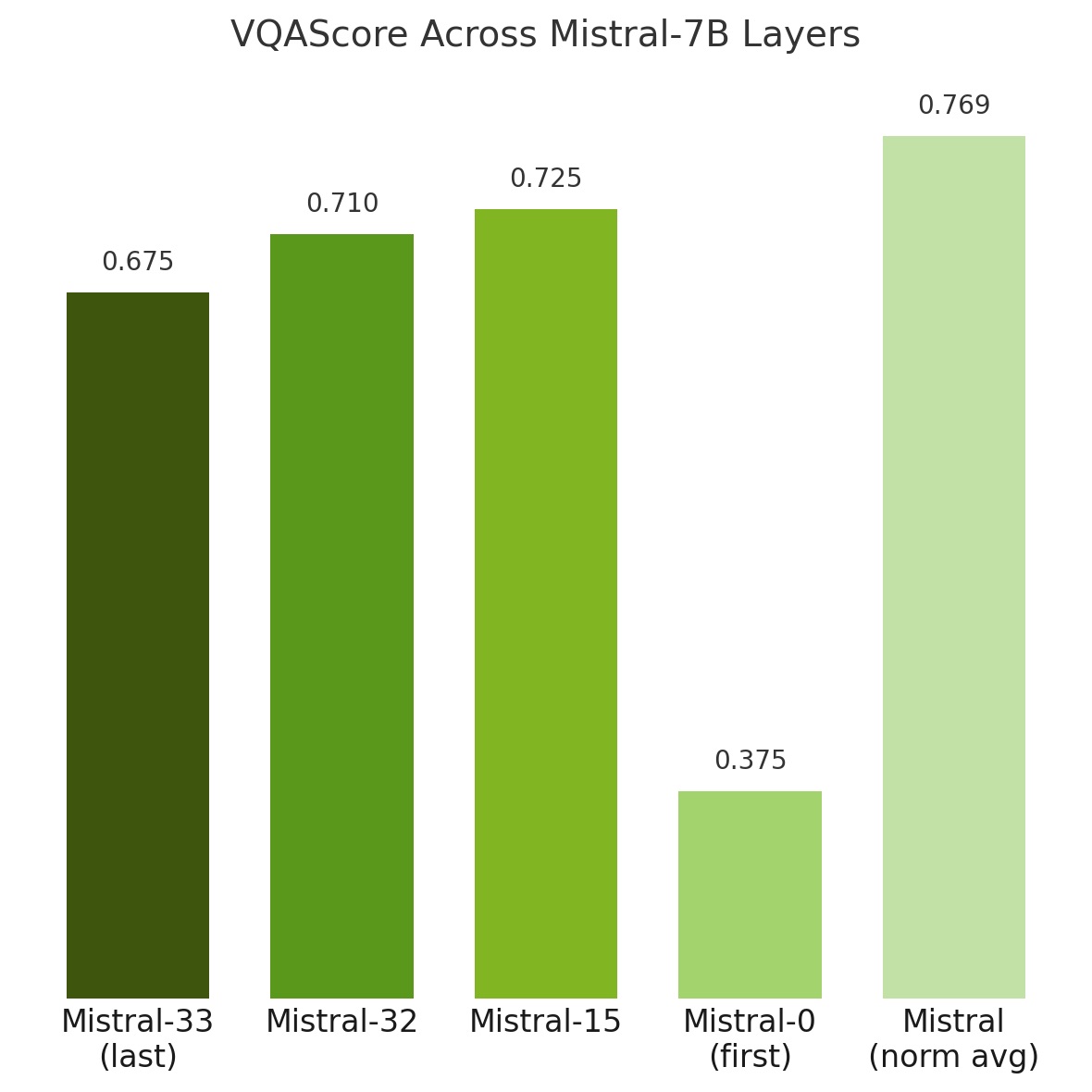
Aggregating features from multiple layers outperforms using a single layer
We find that using embeddings normalized and averaged across all layers yields far better performance than relying on any single layer alone. This is because each layer within an LLM captures different aspects of linguistic information, so using averaged embeddings can combine the strengths of every layer to create a richer and more comprehensive representation.
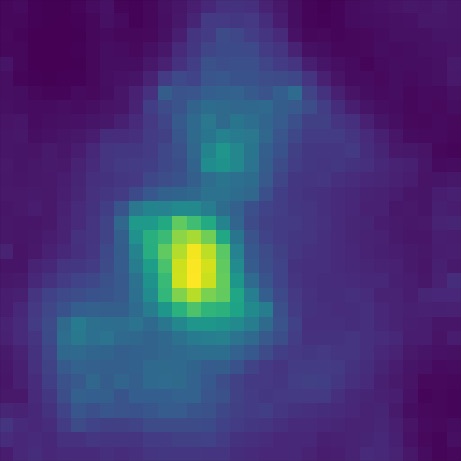
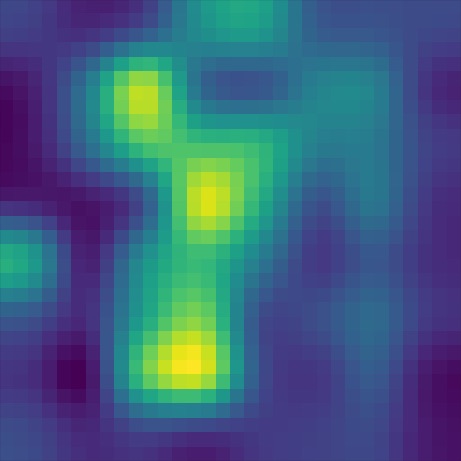
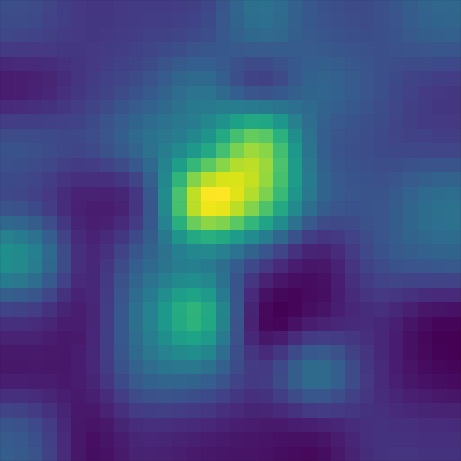
Heatmap visualizations of token cross-attention show how the norm-average model outperforms the last-layer model on prompts requiring advanced visio-linguistic reasoning skills, such as differentiation (left set) and comparison (right set):
Mistral (last layer)

Mistral (norm avg)

Mistral (last layer)

Mistral (norm avg)

A larger gorilla hands a smaller, mechanical monkey a banana
A tomato vine with several tomatoes on it, all yellow except the largest which is red
Scaling up the LLM is beneficial, but not across all aspects
Increasing the model size of LLMs consistently leads to improved performance. However, we observe that model size does not uniformly enhance all aspects of compositional text-to-image generation. These results suggest that simply scaling model size may not be the most efficient approach for improving performance across all skills, highlighting the potential of alternative strategies, such as hybrid models or skill-specific fine-tuning.
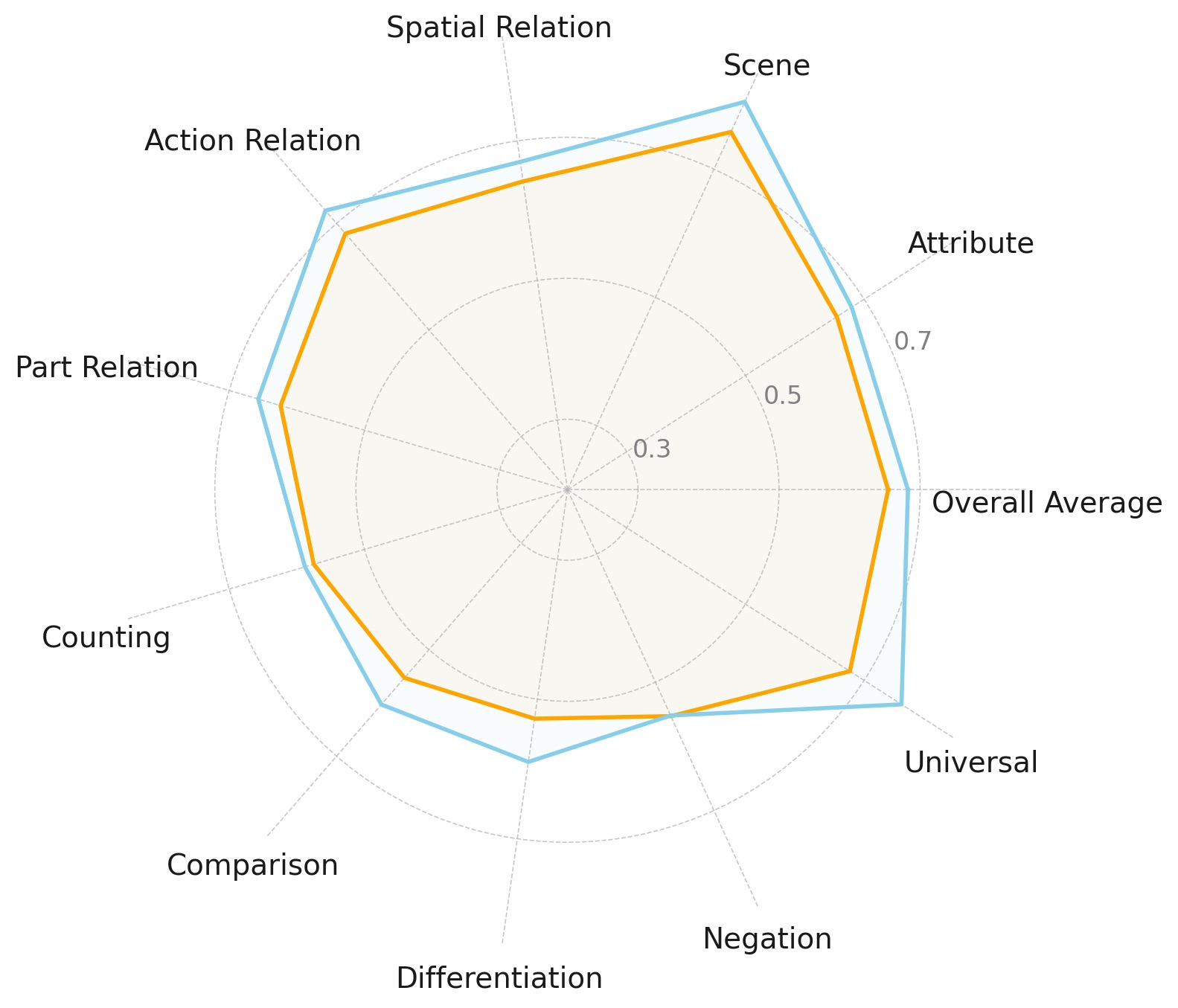
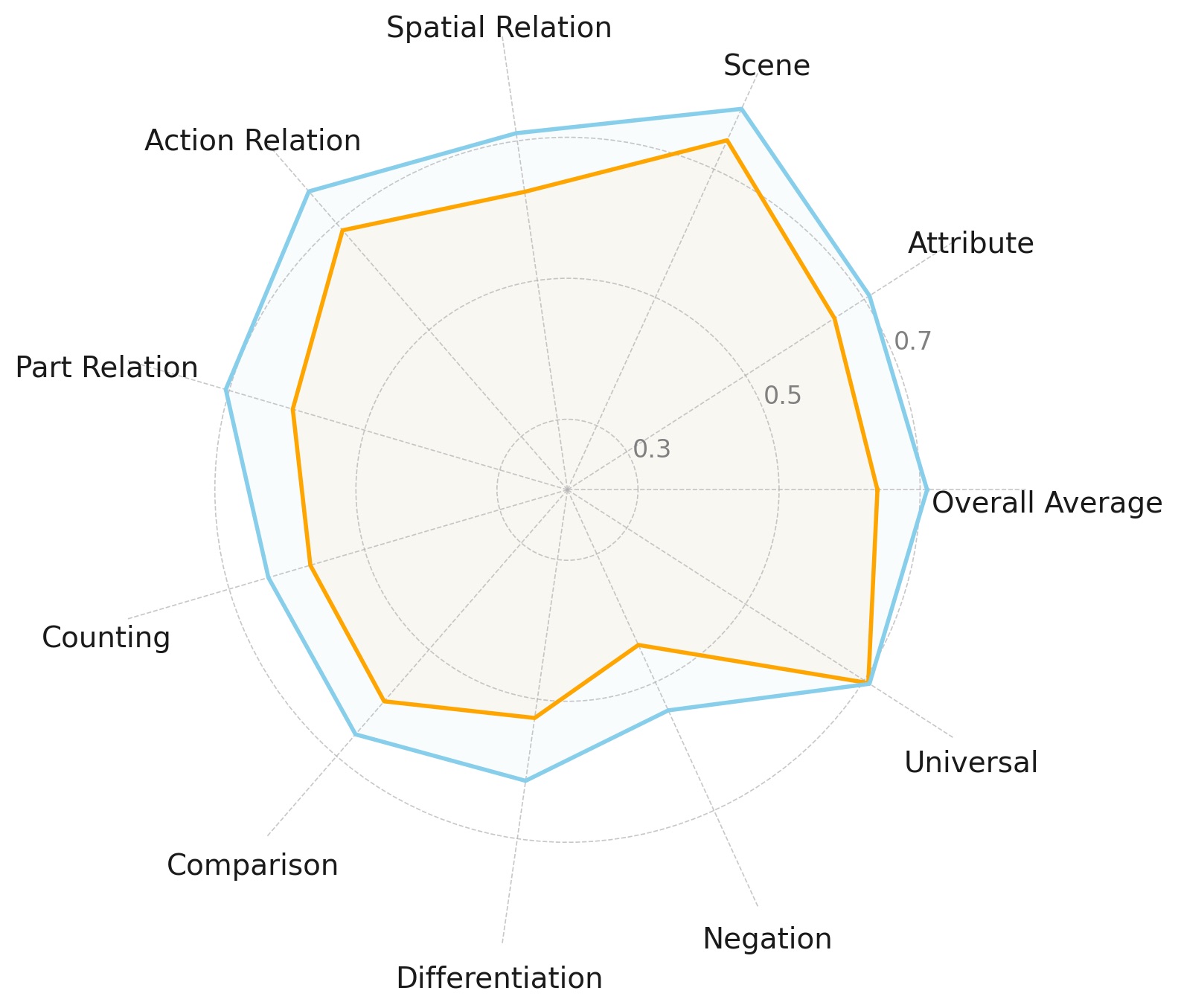
We evaluate differently sized Qwen2 and Gemma2 models. The smaller models (orange) do not exhibit substantial differences in some aspects compared to the larger models (blue). Our results show that scaling does improves performance, but not uniformly across compositional skills.
Experimental Setup
Training Pipeline
Our training pipeline is designed to evaluate the performance of various text encoders within a standardized text-to-image diffusion model framework. Following the SD2 architecture, we retain and freeze all model components except for the UNet. In each experiment, we replace the text encoder with a different LLM or fine-tuned embedding model.
Models of Interest
We mainly explore four types of text encoders:
- T5: A traditional encoder-decoder model widely used in text-to-image models to effectively capture linguistic and semantic information for image generation.
- CLIP: Aligns visual and textual representations within a shared embedding space through contrastive learning, making it a popular choice for strong text-image alignment.
- Pre-trained LLMs: Several open-source, high-performing LLMs trained for autoregressive language modeling with a next token prediction objective.
- Fine-tuned Embedding Models: Fine-tuned versions of the LLMs, examining whether improvements in semantic comprehension translate into improved image generation and text-image alignment.
Benchmarking and Metrics
We adopt GenAI-Bench as our primary benchmarking suite. GenAI-Bench includes 1,600 diverse and challenging prompts, each annotated with specific aspects in the compositional text-to-visual generation. We use VQAScore as our primary evaluation metric, as VQA-based automatic evaluation methods have demonstrated higher reliability and correlation with human judgements.
Visual Results
Additional visual comparisons on GenAI-Bench
CLIP (last layer)

T5 (last layer)

Mistral (norm avg)

Bge-Gemma2 (norm avg)

A single, vibrant red rose blooms defiantly through a narrow crack in the weathered, grey concrete. Its velvety petals unfurl gracefully, reaching for the sunlight that filters weakly through the urban haze.




A scene with two blue balls amidst many yellow ones. The blue balls are slightly larger than the yellow ones and have a smooth, glossy surface that reflects the light.




A yellow felt box has no metallic blue spheres on the left side and has blue metallic spheres on the right side.




There is a large fish aquarium in the center of the luxurious living room, but there are no fish in it. The aquarium is made of polished, rippling glass, reflecting the warm glow of the chandelier above.




A woman with three dogs and no umbrella in the drizzle. Two golden retrievers bound ahead, their tails wagging despite the light rain, while a small terrier trots obediently by her side.
Additional visual comparisons on common text-to-image prompts
CLIP (last layer)

T5 (last layer)

Mistral (norm avg)

Bge-Gemma2 (norm avg)

A photo of a Shiba Inu dog with a backpack riding a bike. It is wearing sunglasses and a beach hat.




A high contrast portrait of a very happy fuzzy panda dressed as a chef in a high end kitchen making dough. There is a painting of flowers on the wall behind him.




A mischievous ferret with a playful grin squeezes itself into a large glass jar, surrounded by colorful candy. The jar sits on a wooden table in a cozy kitchen, and warm sunlight filters through a nearby window.




An icy landscape under a starlit sky, where a magnificent frozen waterfall flows over a cliff. In the center of the scene, a fire burns bright, its flames seemingly frozen in place, casting a shimmering glow on the surrounding ice and snow.
Citation
@inproceedings{wang2025decoder,
title={A Comprehensive Study of Decoder-Only LLMs for Text-to-Image Generation},
author={Wang, Andrew Z. and Ge, Songwei and Karras, Tero and Liu, Ming-Yu and Balaji, Yogesh},
booktitle={IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2025}
}