Abstract
Discrete video tokenization has become essential for streamlining autoregressive generative modeling due to the high dimensionality of video data. To this end, our work introduces a state-of-the-art discrete video tokenizer. Our main contributions are twofold. First, we introduce a new quantization scheme, termed channel-split quantization, which integrates seamlessly with existing methods to effectively enhance the representational power of quantized latents while preserving the token count. Second, we propose an efficient Mamba-based tokenizer that addresses the limitations of previous sequence-based tokenizers and sets a new state-of-the-art, outperforming causal 3D convolution-based approaches across multiple datasets. Our experimental analyses further underscore its potential as a robust tokenizer for autoregressive video generation.
* Equal contribution.
Discrete Video Tokenization
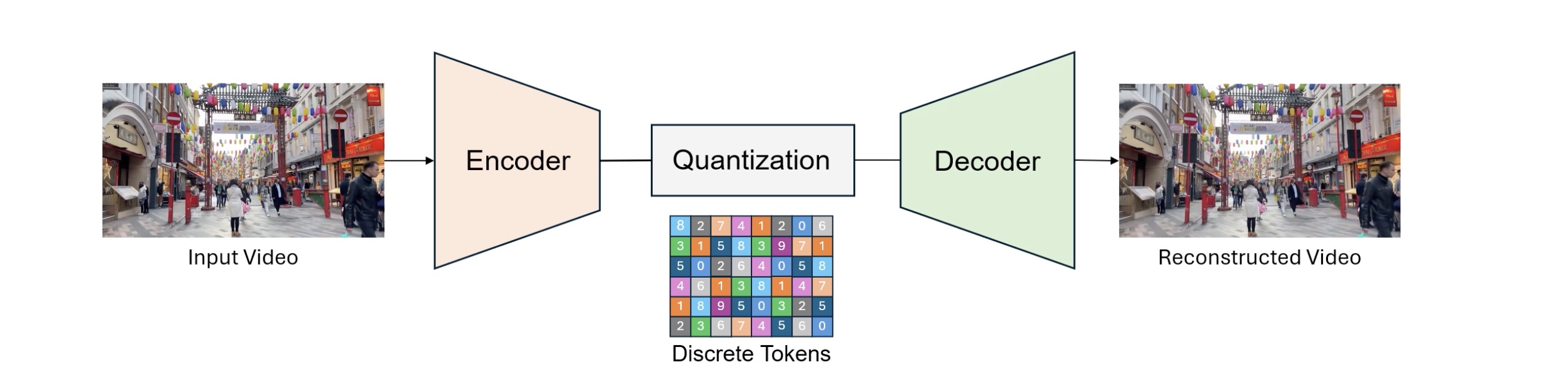
The most commonly used approaches for discrete video tokenization (DVT) follow three main steps. First, an encoder network compresses the input video into latent features. Second, a quantization layer maps the continuous encoded features to discrete tokens (codes) using a codebook. Third, the quantized representation is fed into a decoder network to reconstruct the input video.
Background
Quantization Methods
Most discrete tokenization methods use vector quantization (VQ) with a learnable codebook for compressed, semantic data representation. However, VQ has notable drawbacks: (1) unstable training requiring additional losses and hyperparameters, (2) underutilization of larger codebooks, which hampers generative performance, and (3) computational inefficiency from exhaustive codebook searches. To overcome these issues, recent approaches explore quantization schemes with non-learnable codebooks. For instance, MAGViT-v2 introduced look-up free quantization (LFQ), which converts encoded latent values in the channel dimension into a binary sequence of -1's and 1's. Similarly, finite scalar quantization (FSQ) maps encoded latent values in the channel dimension to a small set of fixed values, implicitly forming a codebook as the product of these sets.
Notation: Let \(V\) denote the input video with size \(T\times H\times W\times 3\). If the spatio-temporal compression rate is \(\times thw\), then the encoded latent \(v\) will have dimensions \(\frac{T}{t}\times \frac{H}{h}\times \frac{W}{w}\times c\), where \(c\) denotes the latent channel size. After quantization, the total number of tokens is \(\frac{THW}{thw}\).
Look-up Free Quantization (LFQ): Given codebook \(C\) of size \(|C| = 2^N\), LFQ requires \(c = N\) and each value of \(v\) in the channel dimension is quantized to -1 or 1, i.e., \(\hat{v} = \mathrm{sign}(v)\). This significantly limits the representational expressiveness of LFQ compared to VQ.
Finite Scalar Quantization (FSQ): Given the encoded latent \(v\), FSQ first applies a bounding function \(f\), and then rounds to integers. The function \(f\) is chosen such that each channel in the quantized latent \(\hat{v} = \mathrm{round}(f(v))\) takes one of \(L\) unique values. Due to this condition, FSQ requires a much smaller latent channel size \(c = M (< N)\) for a codebook size of \(2^N\).
Encoder-Decoder Architecture
The encoder-decoder architectures of existing discrete video tokenizers can be broadly categorized into 3D convolution-based (VideoGPT, MAGViT-v2) and Transformer-based (OmniTokenizer, CiViT). While state-of-the-art discrete image tokenizers use vision Transformers (ViTs), leading video tokenizers favor causal 3D convolutions for their superior computational efficiency with video data. The reliance on positional embeddings in Transformer-based tokenizers also makes it difficult to tokenize unseen spatial and temporal resolutions.
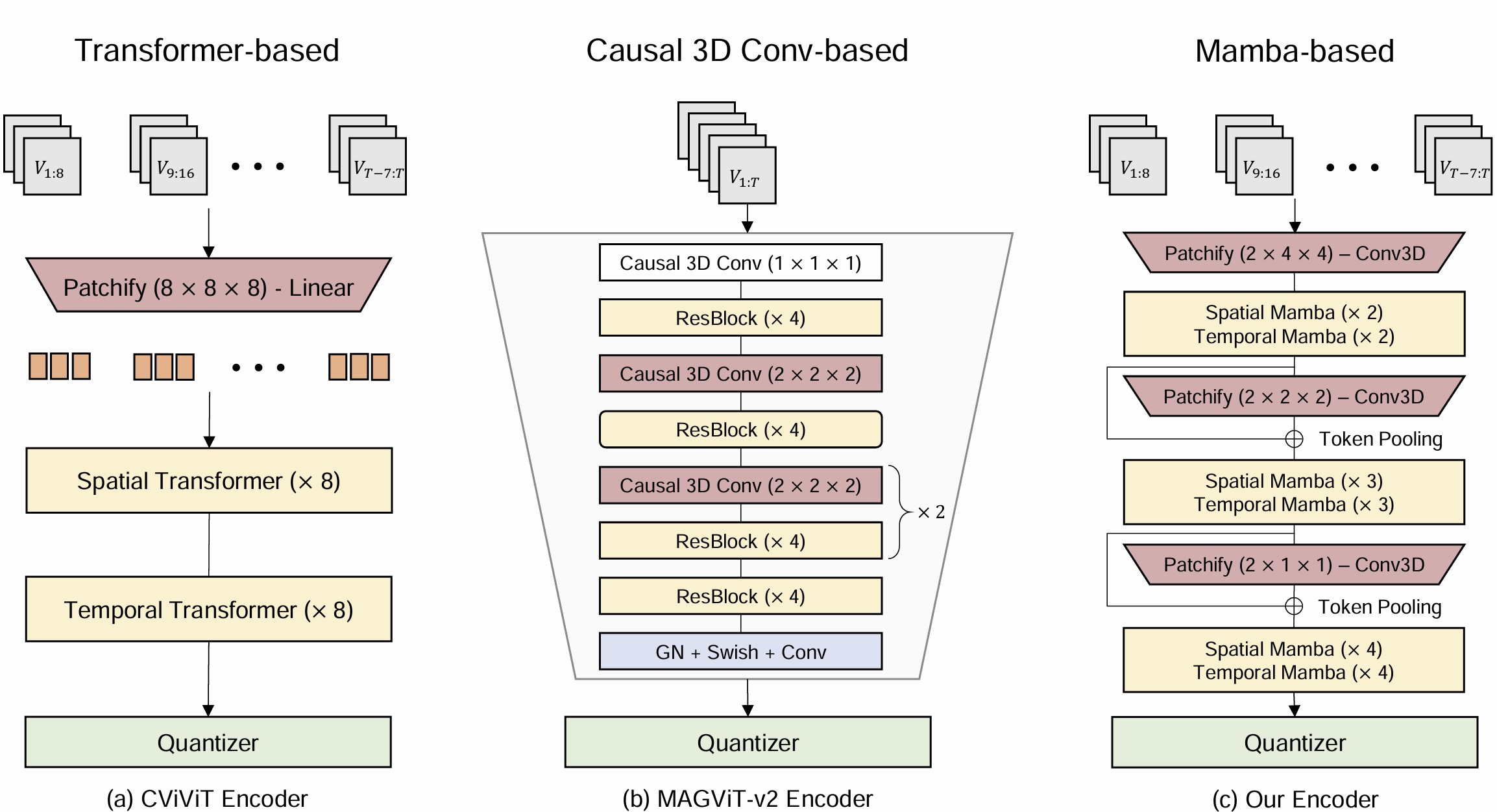
Figure 1: Architecture Overview: (a) The encoder network for CViViT, a state-of-the-art Transformer-based tokenizer. (b) The encoder network for MAGViT-v2, a state-of-the-art causal 3D convolution-based tokenizer. (c) The encoder architecture of the proposed Mamba-based tokenizer. Each model is designed with an \(8 \times 8 \times 8\) spatio-temporal compression rate.
Channel-Split Quantization
Due to the limited representational capacity during quantization, LFQ/FSQ-based tokenizers heavily depend on the decoder network for reconstruction, limiting their overall generalization capability. To mitigate this challenge, our work introduces a new quantization scheme, termed channel-split quantization, which enhances the representational power of the quantized latent while preserving the number of tokens and can be easily integrated into both LFQ and FSQ.
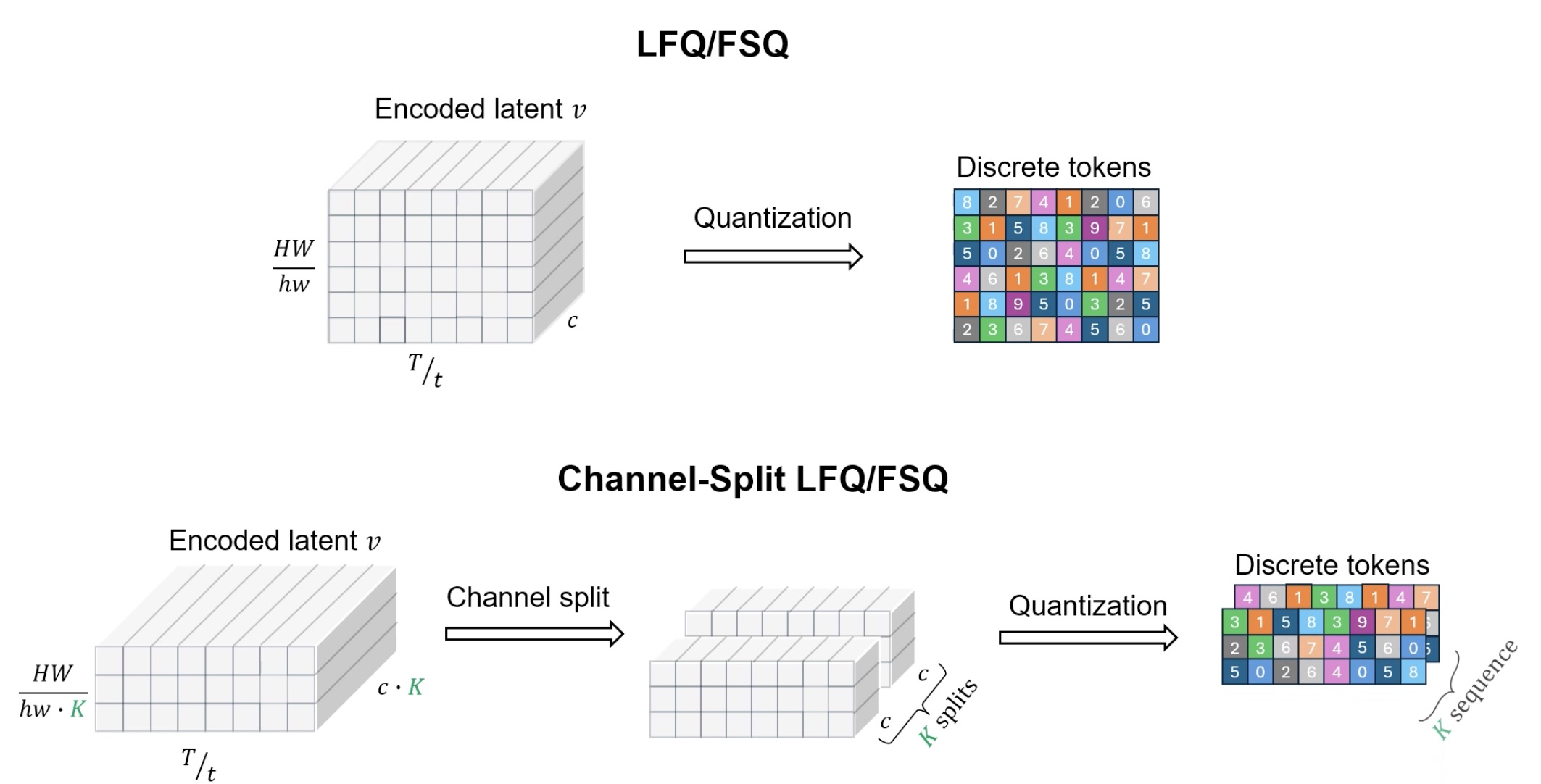
Our key idea is to exploit the trade-off between the compression and quantization steps during tokenization. First, we increase the channel size of the encoded latent by a factor of \(K\). Then, we split the encoded latent in the channel dimension into \(K\) groups, i.e., \(v = \{v_1, \ldots, v_K\}\). Finally, each split is independently quantized using either LFQ or FSQ, which we refer to as channel-split LFQ (CS-LFQ) and channel-split FSQ (CS-FSQ), respectively.
Video Tokenization Results for Channel-Split Quantization
Comparison between MAGViT-v2 + FSQ and MAGViT-v2 + CS-FSQ.
MAGViT-v2 + FSQ (\(4\times 8\times 8\))
MAGViT-v2 + CS-FSQ (\(8\times 8\times 8\))
MAGViT-v2 + FSQ (\(4\times 8\times 8\))
MAGViT-v2 + CS-FSQ (\(8\times 8\times 8\))
A tokenizer with channel-split quantization (MAGViT-v2 + CS-FSQ) reconstructs videos with higher fidelity and reduced flickering compared to one using naive FSQ (MAGViT-v2 + FSQ).
MambaVideo-based Discrete Video Tokenizer
Our work develops a robust sequence-based discrete video tokenizer that overcomes the limitations of prior Transformer-based tokenizers and surpasses the current state-of-the-art, the causal 3D CNN-based tokenizer MAGViT-v2.
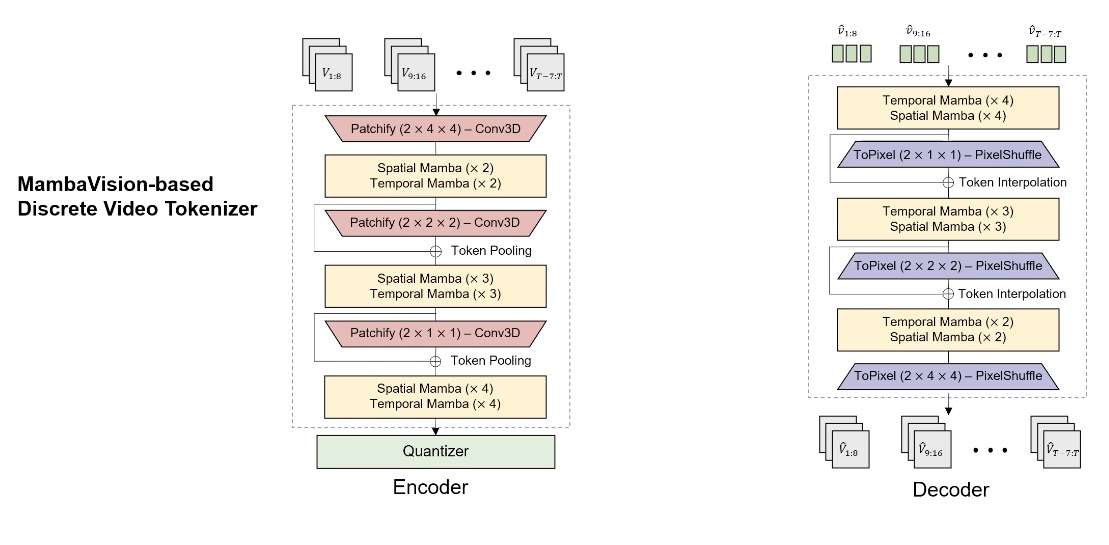
Key Improvements Over the Previous State-of-the-Art
Hierarchical Encoding and Decoding: Our model employs hierarchical encoding and decoding, where the encoder network downscales the input video in a top-down manner through a series of encoder blocks, each consisting of a cascade of patchify and spatial-temporal attention modules. Similarly, the decoder upscales the quantized latent in a bottom-up fashion using a series of decoder blocks.
3D convolution-based Patchify and ToPixel: Unlike previous works that use a linear embedding layer, we employ a 3D convolution-based embedding layer to better capture dependencies between the spatio-temporal patches.
Mamba-based Spatial and Temporal Attention: We use Mamba layers instead of Transformers for the spatial and temporal attention modules. Mamba is a powerful model for reasoning over long-sequence inputs and does not require explicit positional encoding, effectively mitigating the positional encoding bias that limits the generalization capabilities of Transformer-based tokenizers. Additionally, Mamba's linear-scale attention significantly improves computational efficiency compared to Transformers.
Token Pooling and Interpolation: To further enhance encoding and decoding, we introduce residual connections within the encoder and decoder blocks through token pooling and interpolation, respectively.
Video Tokenization Results for Our Tokenizer
Input Video
Reconstructed Video (\(8\times 8\times 8\))
Input Video
Reconstructed Video (\(8\times 8\times 8\))
Quantitative Evaluation: Video Reconstruction
We use two representative video datasets with medium to large degrees of motion—Xiph-2K and DAVIS—to evaluate our model and competing approaches on the video reconstruction task. The quality of the decoded video is measured using PSNR, SSIM, and LPIPS metrics.
Best bolded, second best underlined.
| Tokenizer | Compression | Codebook | Xiph PSNR ↑ | Xiph SSIM ↑ | Xiph LPIPS ↓ | DAVIS PSNR ↑ | DAVIS SSIM ↑ | DAVIS LPIPS ↓ |
|---|---|---|---|---|---|---|---|---|
| VideoGPT (VQ) | 4×4×4 | 211 | 31.09 | 0.819 | 0.327 | 31.30 | 0.771 | 0.305 |
| CViViT (VQ) | 2×8×8 | 213 | 28.92 | 0.708 | 0.232 | 27.73 | 0.660 | 0.272 |
| OmniTokenizer (VQ) | 4×8×8 | 213 | 25.96 | 0.691 | 0.181 | 25.34 | 0.633 | 0.208 |
| MAGViT-v2 (LFQ) | 4×8×8 | 216 | 30.02 | 0.701 | 0.189 | 29.26 | 0.652 | 0.241 |
| MAGViT-v2 + CS-LFQ | 8×8×8 | 216 | 30.97 | 0.719 | 0.172 | 30.57 | 0.670 | 0.226 |
| MAGViT-v2 + FSQ | 4×8×8 | 216 | 30.69 | 0.714 | 0.185 | 30.06 | 0.666 | 0.238 |
| MAGViT-v2 + CS-FSQ | 8×8×8 | 216 | 31.08 | 0.728 | 0.165 | 30.75 | 0.681 | 0.214 |
| Ours + LFQ | 4×8×8 | 216 | 31.05 | 0.711 | 0.171 | 30.02 | 0.669 | 0.224 |
| Ours + CS-LFQ | 8×8×8 | 216 | 31.95 | 0.738 | 0.160 | 31.25 | 0.673 | 0.218 |
| Ours + FSQ | 4×8×8 | 216 | 31.43 | 0.722 | 0.168 | 30.65 | 0.678 | 0.217 |
| Ours + CS-FSQ | 8×8×8 | 216 | 32.54 | 0.747 | 0.151 | 32.36 | 0.691 | 0.206 |
Qualitative Comparison with MAGViT-v2
MAGViT-v2 (\(4\times 8\times 8\))
Ours (\(8\times 8\times 8\))
MAGViT-v2 (\(4\times 8\times 8\))
Ours (\(8\times 8\times 8\))
Video Generation Experiments
One of the primary applications of our work is video generation, where the encoder compresses input video into quantized tokens for generative modeling, and the decoder reconstructs a video from generated tokens. To demonstrate this, we integrate our pretrained video tokenizer, along with tokenizers from competing approaches, into the open-source autoregressive framework VideoGPT and train each for unconditional video generation.
Quantitative Evaluation: Video Generation (FVD)
| Tokenizer | Compression | SkyTimelapse FVD ↓ | UCF-101 FVD ↓ |
|---|---|---|---|
| VideoGPT | 4×4×4 | 218.4 | 2455.9 |
| MAGViT-v2 + FSQ | 4×8×8 | 188.2 | 2037.5 |
| MAGViT-v2 + CS-FSQ | 8×8×8 | 175.8 | 1906.8 |
| Ours + LFQ | 4×8×8 | 182.7 | 1994.1 |
| Ours + CS-LFQ | 8×8×8 | 166.1 | 1845.3 |
| Ours + FSQ | 4×8×8 | 174.3 | 1918.8 |
| Ours + CS-FSQ | 8×8×8 | 152.8 | 1794.7 |
Qualitative Comparison on SkyTimelapse
MAGViT-v2 + VideoGPT
Ours + VideoGPT
Qualitative Comparison on UCF-101
MAGViT-v2 + VideoGPT
Ours + VideoGPT
Citation
@article{argaw2025mambavideo,
title={MambaVideo for Discrete Video Tokenization with Channel-Split Quantization},
author={Argaw, Dawit Mureja and Liu, Xian and Chung, Joon Son and Liu, Ming-Yu and Reda, Fitsum},
journal={arXiv preprint arXiv:2507.04559},
year={2025}
}