Introduction
With SEDD winning the Best Paper Award at ICML 2024, discrete diffusion models have emerged as a promising contender to auto-regressive models in text generation. In this blog, however, we uncover a hidden yet critical numerical precision issue that negatively impacts generation diversity in discrete diffusion sampling. This flaw highlights the limitations of previous evaluations, which rely solely on the incomplete metric of generative perplexity, resulting in a secretly unfair comparison to auto-regressive models. For complete analyses and proofs, please refer to our paper.
Score-based diffusion models address the first challenge by learning the score function \(\nabla_x \log p_{\text{data}}(x)\) which cancels out the normalizing constant, and address the second challenge by modeling a series of noise-perturbed distributions \(\{p_t\}_{t \in [0,1]}\).
Discrete diffusion models can be defined in a similar score-based continuous-time approach. For the case of a single dimension (\(d = 1\)), the forward discrete diffusion process is described by a continuous-time Markov chain (CTMC), where the token randomly transits according to some predefined rate matrix \(Q_t\). The forward process can be chosen as uniform or absorbing (or masked).
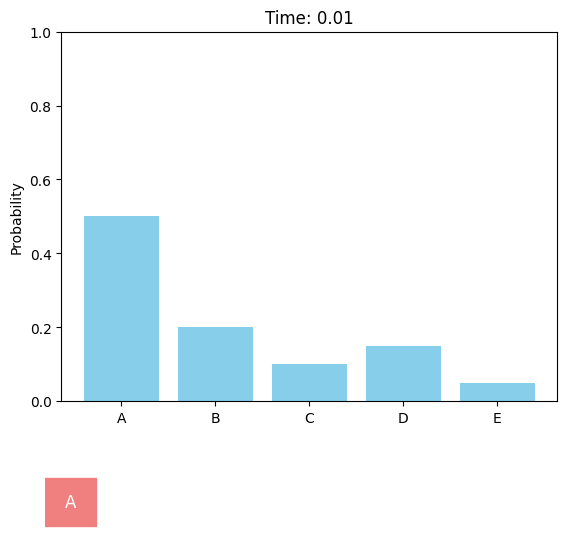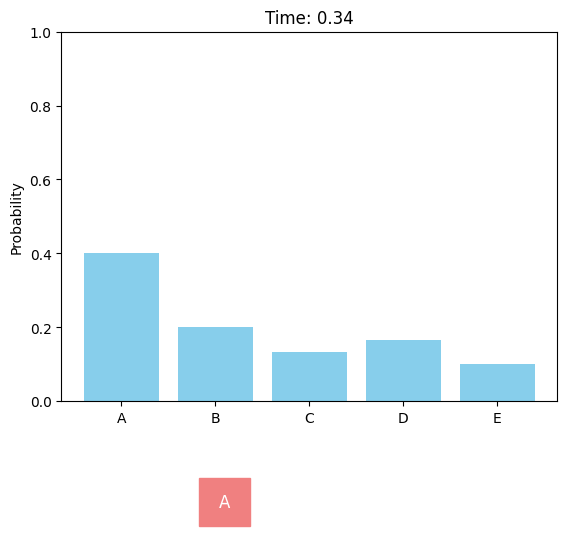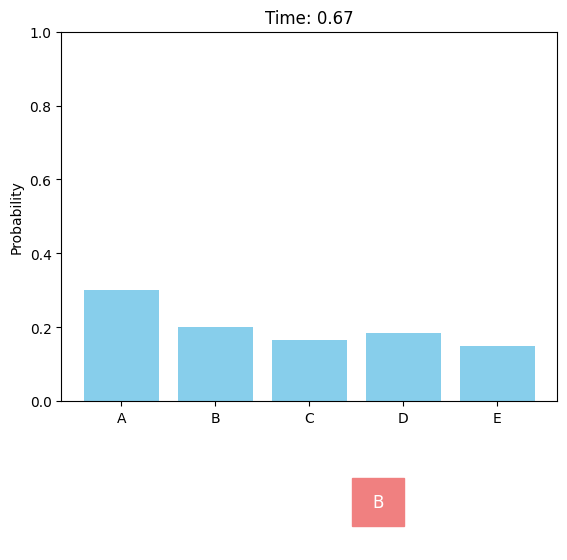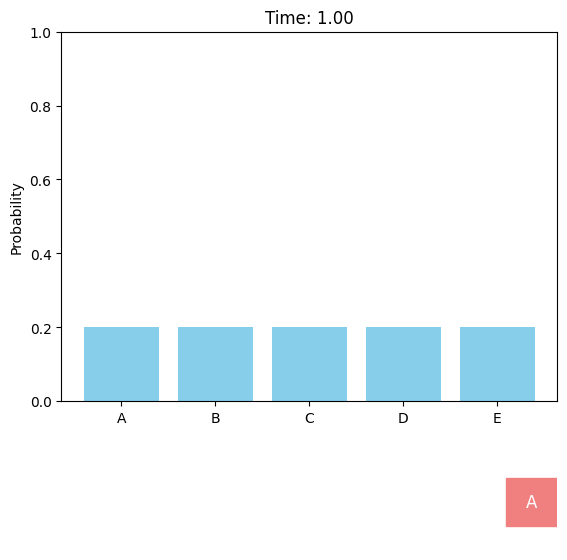
Uniform forward diffusion process.
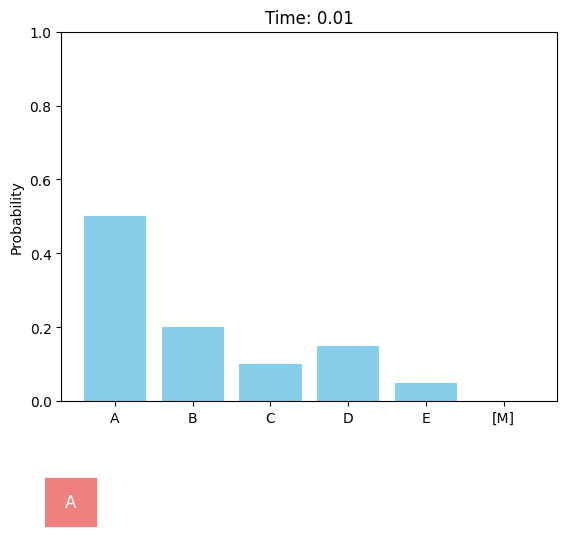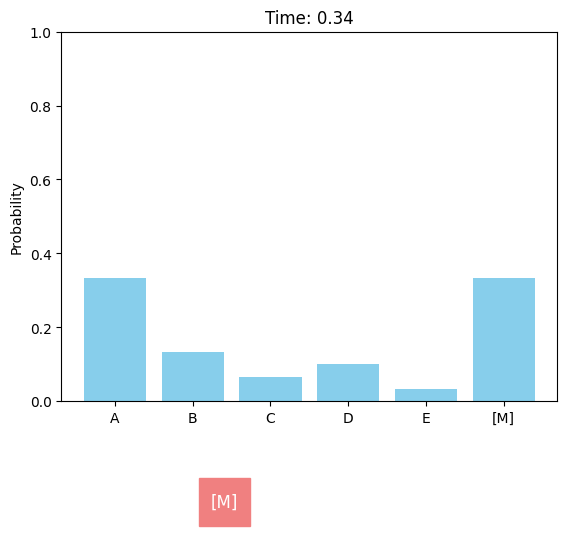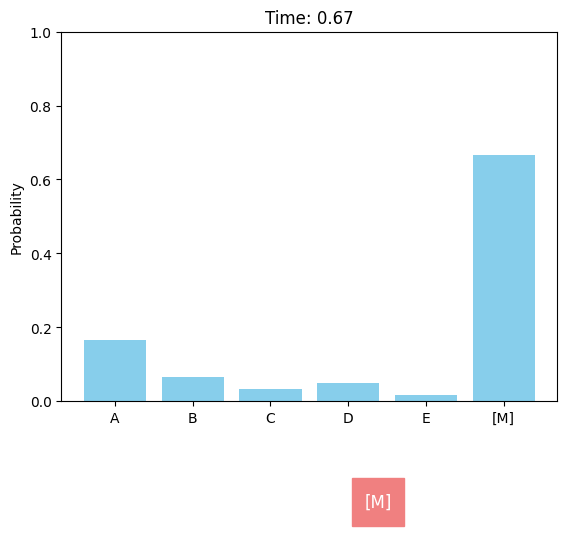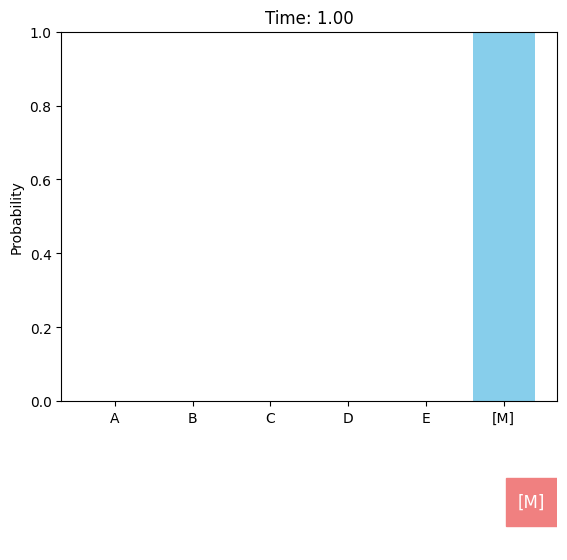
Absorbing (masked) forward diffusion process.
Masked Diffusion Models as the Best-Performing Discrete Diffusion

Forward noising process of masked diffusion models.

Reverse sampling process of masked diffusion models.
Empirically, the absorbing (or masked) variant demonstrates superior performance over other discrete diffusion schedules such as uniform, and is referred to as masked diffusion models (MDMs). In some recent works, the masked diffusion formulation is further simplified to a mean-prediction model \(\mu_\theta\) with simple weighted cross-entropy training objectives, bringing empirical improvements.
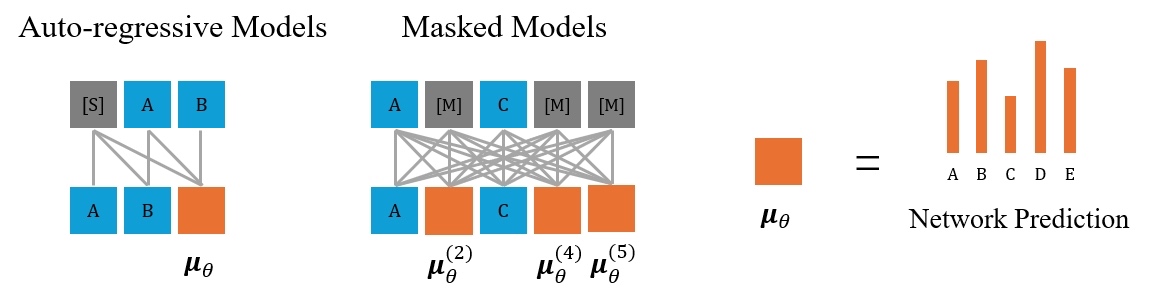
Auto-regressive models with causal attention, and masked models with bi-directional attention.
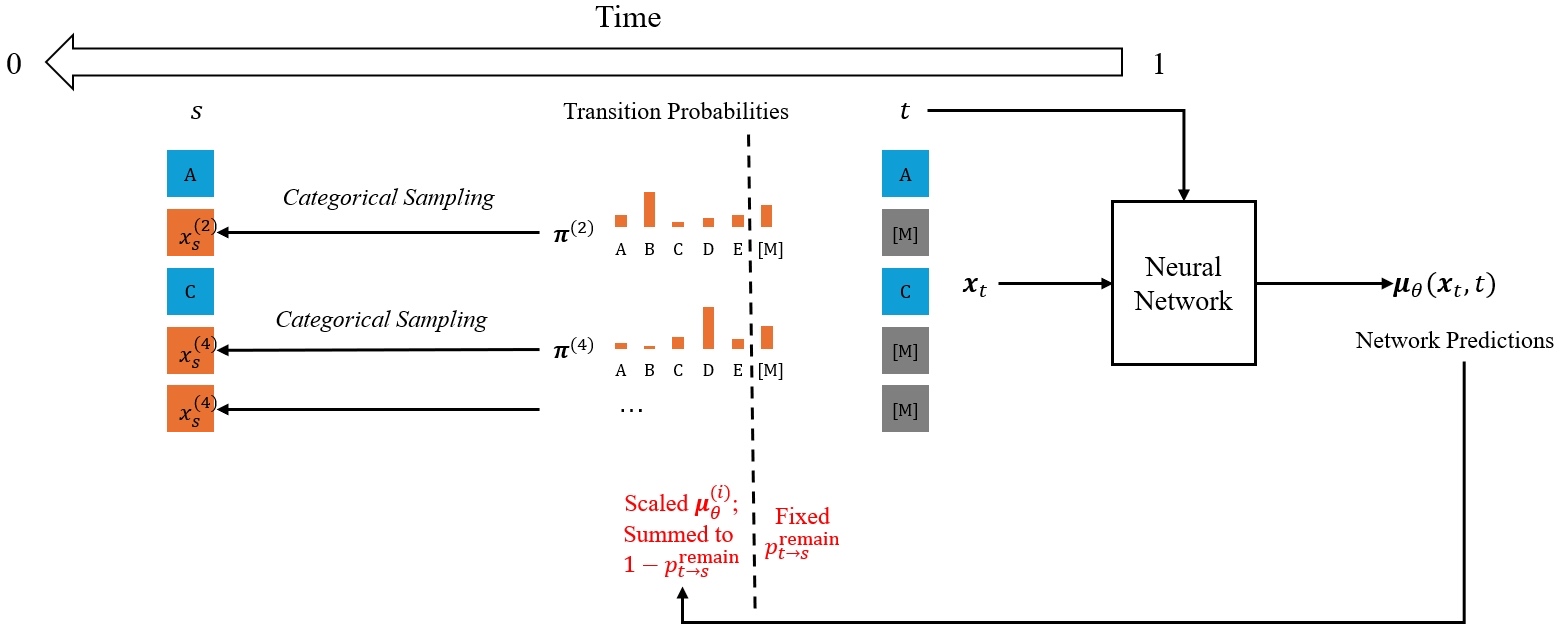
Illustration of the sampling step in masked diffusion models.
Does Lower Generative Perplexity Indicate Better Quality?
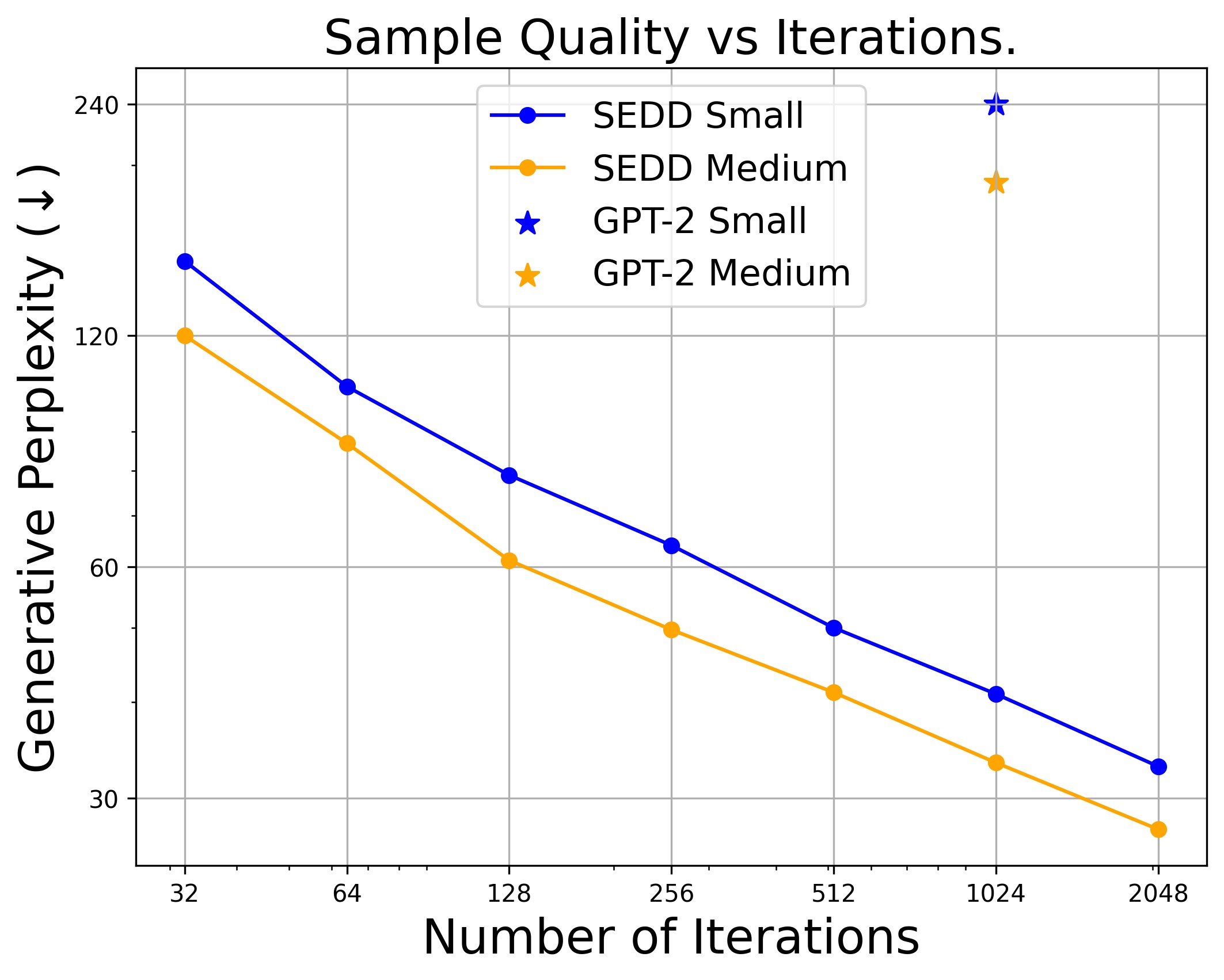
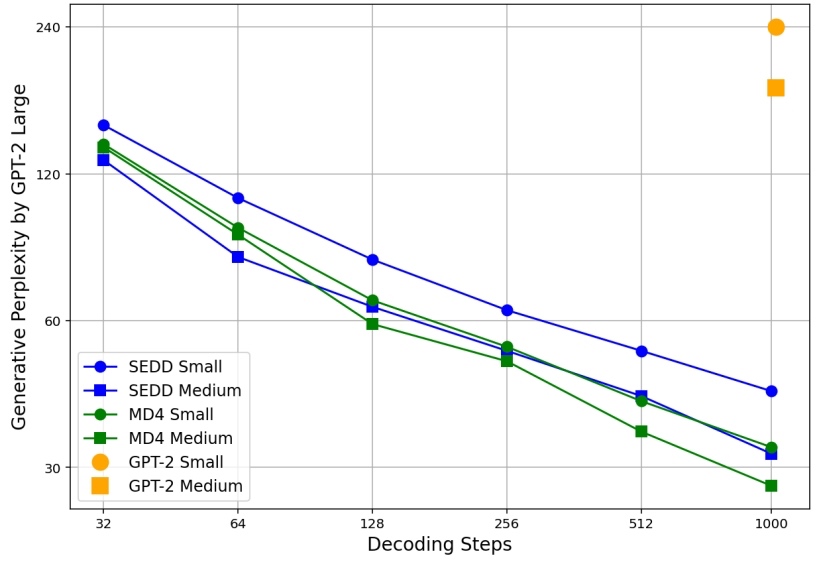
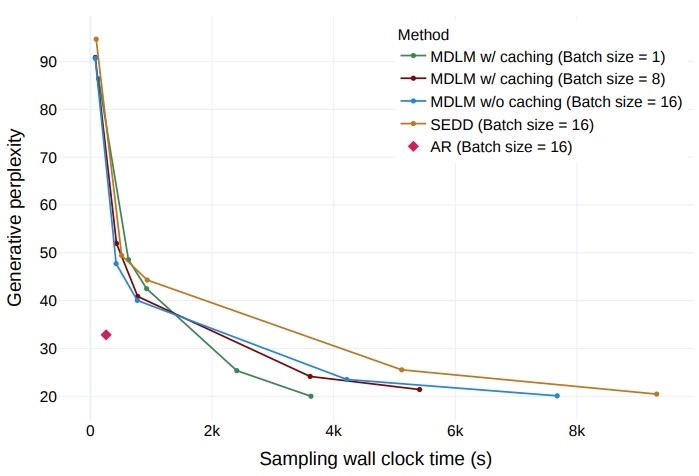
Trade-off between generative perplexity and the number of sampling steps from SEDD, MD4, and MDLM.
Generative perplexity (Gen PPL) is the main metric in previous works to evaluate generation quality. It measures the likelihood of generated text under some off-the-shelf model (typically GPT-2 Large). Lower Gen PPL means larger probability of the generated sample. However, we argue that Gen PPL is not comprehensive for evaluating the generation quality of text — it only favors high-probability samples, while neglecting diversity and mode coverage.
Token Diversity Matters
We present two samples from ARMs and MDMs to demonstrate the diversity problem. With as many as 50,000 sample steps, MDMs can reach an extremely low Gen PPL. However, repetitive patterns such as "I bet!" and "I said" frequently appear, diminishing the diversity of tokens in the sequence.
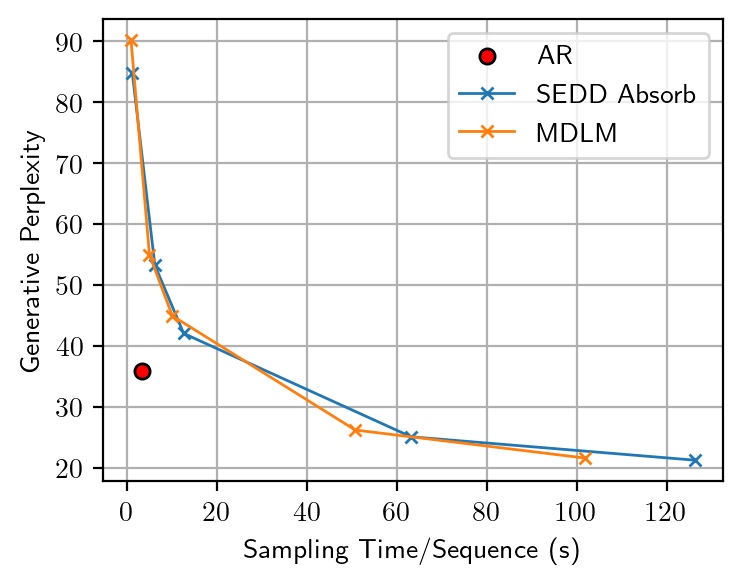
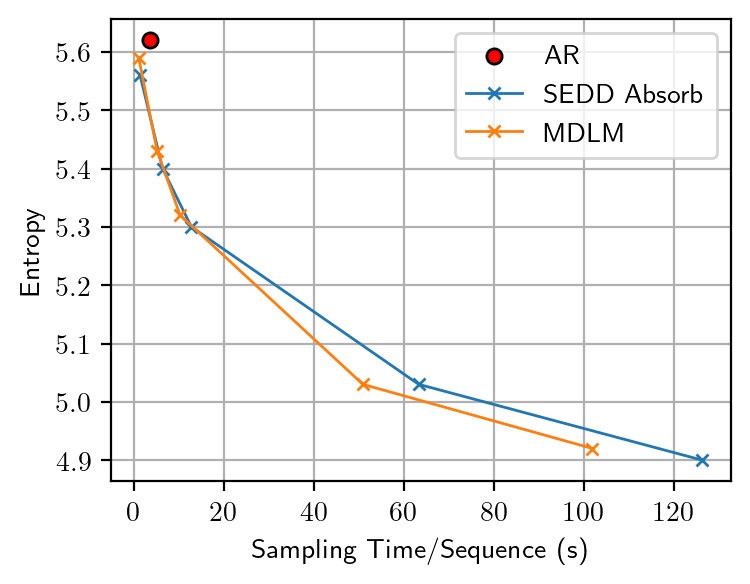
Gen PPL and sentence entropy of SEDD Absorb and MDLM, varying the number of sampling steps in {100, 500, 1000, 5000, 10000}.
Trade-Off between Generative Perplexity and Entropy
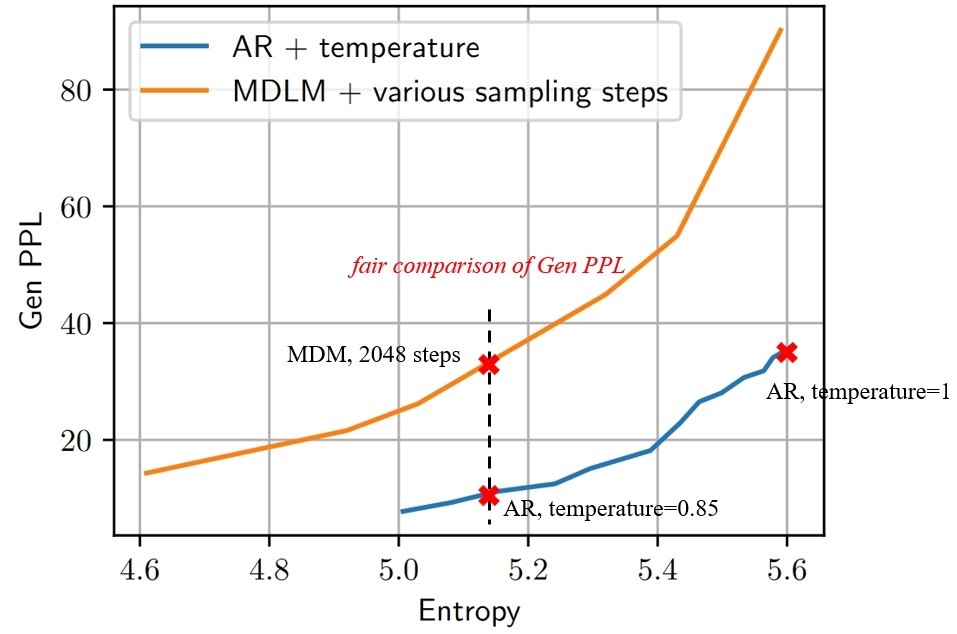
Trade-off curve of Gen PPL and entropy in MDMs and ARMs.
Our observations reveal that varying the number of sampling steps in MDMs creates an inherent trade-off between Gen PPL and entropy. This effectively changes the temperature, leading to an unfair comparison with ARMs, which are not subject to temperature scaling. After manually adjusting the temperature for ARMs to ensure a fair comparison at the same entropy level, we find that the Gen PPL of MDMs falls significantly behind.
What is the Root Cause of Reduced Diversity?
The reduced token diversity and low generation quality is unexpected. In theory, increasing the number of sampling steps should reduce discretization errors and more accurately reflect the true model performance. We therefore consider this an implementation issue and investigate further to identify the root cause.
Identifying the Numerical Precision Issue
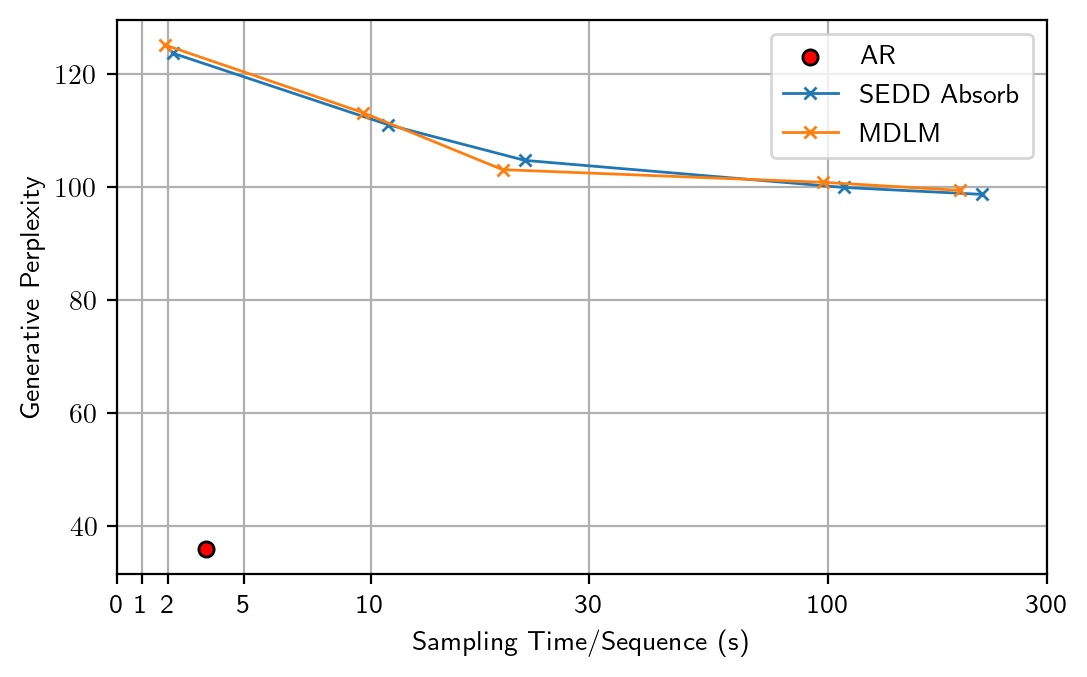
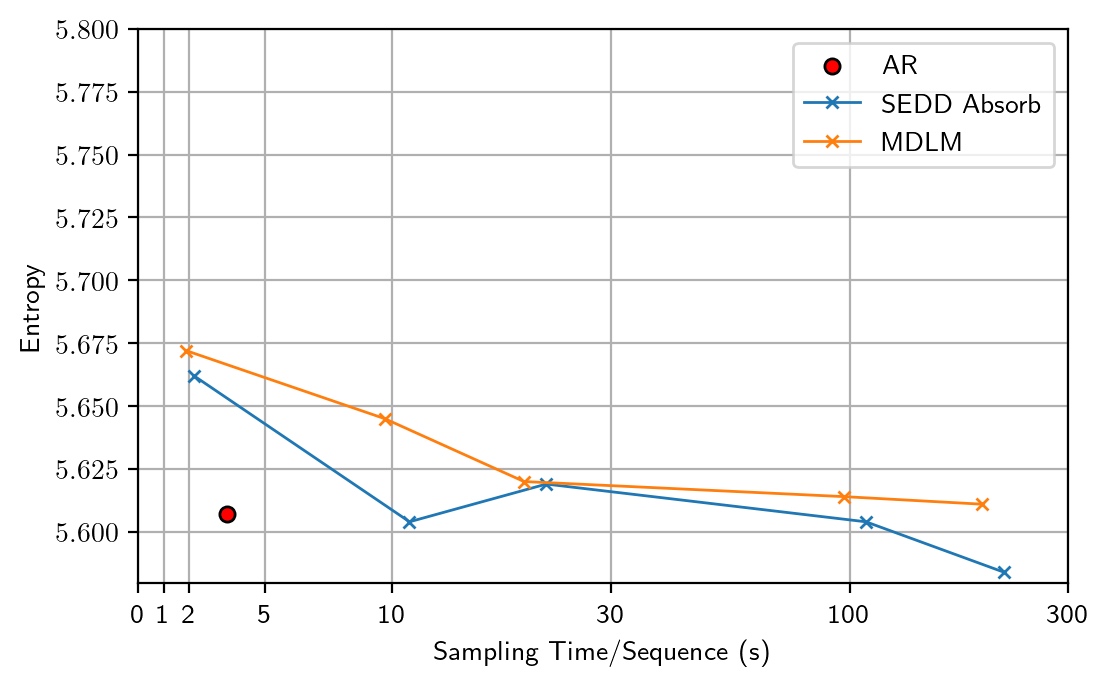
Gen PPL and sentence entropy with 64-bit categorical sampling.
Surprisingly, we find that by simply altering the floating-point precision during sampling from 32-bit to 64-bit, the entropy returns to a normal level similar to ARMs (5.6–5.7), but with a generative perplexity \(\approx 100\). After careful ablations, we identify the root cause as the numerical inaccuracy in previous Gumbel-based categorical sampling.
The operation \(g = -\log(-\log u)\) theoretically maps \(u \in [0, 1]\) to \(g \in (-\infty, +\infty)\). But due to the limited representation ability of floating-point numbers, \(u\) is constrained to \([0, 1-\epsilon]\) and \(g\) is constrained to \((-\infty, M]\). Therefore, the sample \(g\) instead follows a truncated Gumbel distribution, which makes the categorical sampling inaccurate.

Code for different versions of Gumbel-based categorical sampling.
To verify that truncation is the fundamental issue, we conduct ablations by only modifying the categorical sampling code:
| Version | Gen PPL | Entropy |
|---|---|---|
| 32-bit | 31.24 | 5.17 |
| 64-bit | 126.11 | 5.66 |
| 64-bit + truncation | 28.64 | 5.12 |
For both Gen PPL and entropy, 32-bit \(\approx\) 64-bit + truncation, which confirms the impact of truncation.
Theoretical Explanations
Through further derivation, we find that the effect of truncation can be precisely described in closed-form. Specifically, suppose the original class probabilities are sorted as \(\pi_1 \leq \pi_2 \leq \cdots \leq \pi_K\). With the truncated Gumbel distribution, the resulting categorical samples instead follow shifted class probabilities \(\pi'\):
\[\pi_n' = \pi_n \sum_{i=1}^{n} \beta(i), \quad \text{where } \beta(i) \geq 0\]
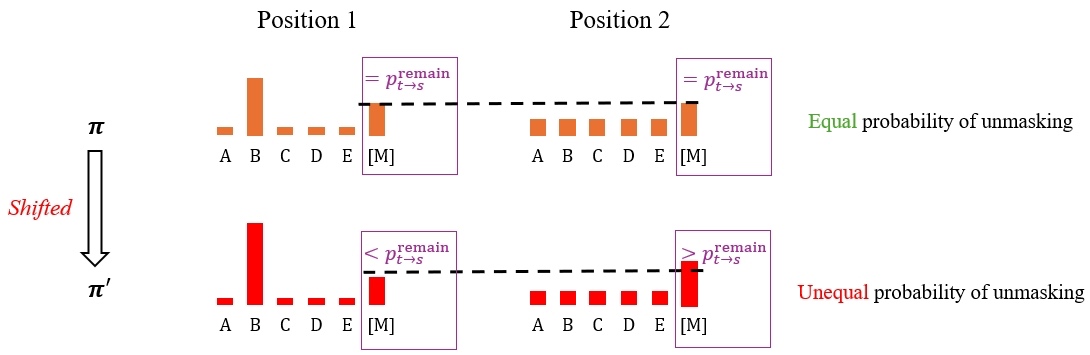
This has two main implications:
- Relatively larger probabilities are further amplified, creating an effect similar to lowering the temperature.
- Some mask tokens are prioritized to be unmasked, thereby reducing randomness.
Concluding Remarks
In this blog, we illustrate how previous works on masked diffusion models secretly suffer from numerical precision issues, leading to somewhat unfair evaluations and doubtful claims. Our investigation suggests:
- Generative perplexity alone cannot comprehensively reflect text generation quality. It is better to use the trade-off curve between generative perplexity and sentence entropy for a more holistic evaluation.
- Masked diffusion models are essentially performing maximum likelihood training of masked models. According to our practice, masked diffusion models, along with other discrete diffusion variants, are far from beating the auto-regressive paradigm in text generation.
Despite our negative findings, we acknowledge that text-based experiments may inherently favor ARMs, as text naturally follows a left-to-right order that ARMs are better suited to model. The masked mechanism could offer advantages over autoregressive next-token prediction in other modalities. In such cases, maximum likelihood training is often unnecessary for achieving good generation quality, and we can directly use masked models like MaskGIT instead of discrete diffusion models, as they are equivalent to the best discrete diffusion variant while offering simpler formulations.
Citation
@inproceedings{zheng2025mdm,
title={Are Discrete Diffusion Models Better Than Auto-regressive Models in Text Generation? Uncovering a Hidden Implementation Issue},
author={Zheng, Kaiwen and Chen, Yongxin and Mao, Hanzi and Liu, Ming-Yu and Zhu, Jun and Zhang, Qinsheng},
booktitle={International Conference on Learning Representations (ICLR)},
year={2025}
}