Abstract
Diffusion models, praised for their success in generative tasks, are increasingly being applied to robotics, demonstrating exceptional performance in behavior cloning. However, their slow generation process stemming from iterative denoising steps poses a challenge for real-time applications in resource-constrained robotics setups and dynamically changing environments. In this paper, we introduce the One-Step Diffusion Policy (OneDP), a novel approach that distills knowledge from pre-trained diffusion policies into a single-step action generator, significantly accelerating response times for robotic control tasks. We ensure the distilled generator closely aligns with the original policy distribution by minimizing the Kullback-Leibler (KL) divergence along the diffusion chain, requiring only 2%–10% additional pre-training cost for convergence. We evaluated OneDP on 6 challenging simulation tasks as well as 4 self-designed real-world tasks using the Franka robot. The results demonstrate that OneDP not only achieves state-of-the-art success rates but also delivers an order-of-magnitude improvement in inference speed, boosting action prediction frequency from 1.5 Hz to 62 Hz, establishing its potential for dynamic and computationally constrained robotic applications.
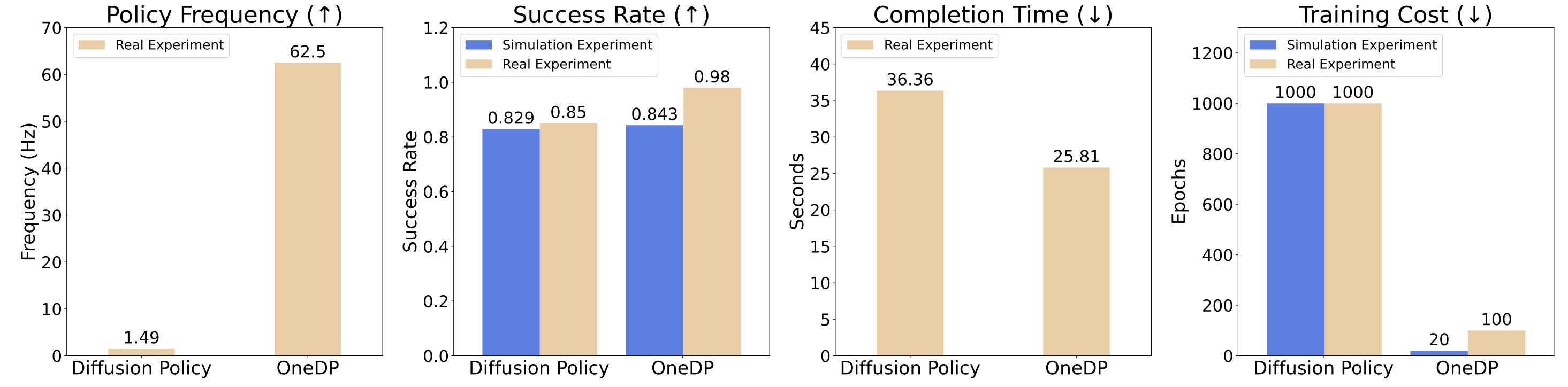
Quantitative comparison between OneDP and Diffusion Policy in Frequency, Success Rate, Completion Time, and Training Cost.
OneDP Distillation Pipeline
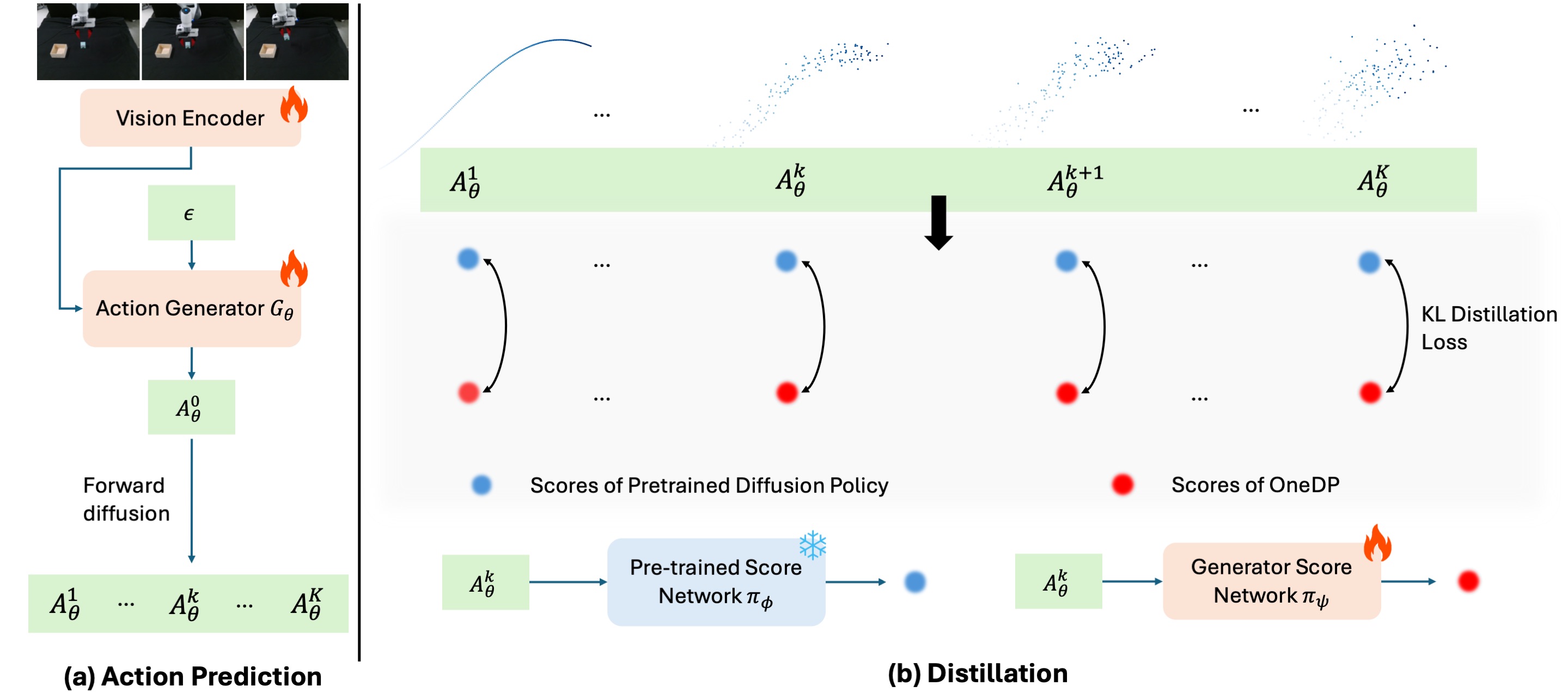
(a) Our one-step action generator processes image-based visual observations alongside a random noise input to deliver single-step action predictions. (b) We implement KL-based distillation across the entire forward diffusion chain. Direct computation of the KL divergence is often impractical; however, we can effectively utilize the gradient of the KL, formulated into a score-difference loss. The pre-trained score network remains fixed while the action generator and the generator score network are trained.
Simulation Benchmarks
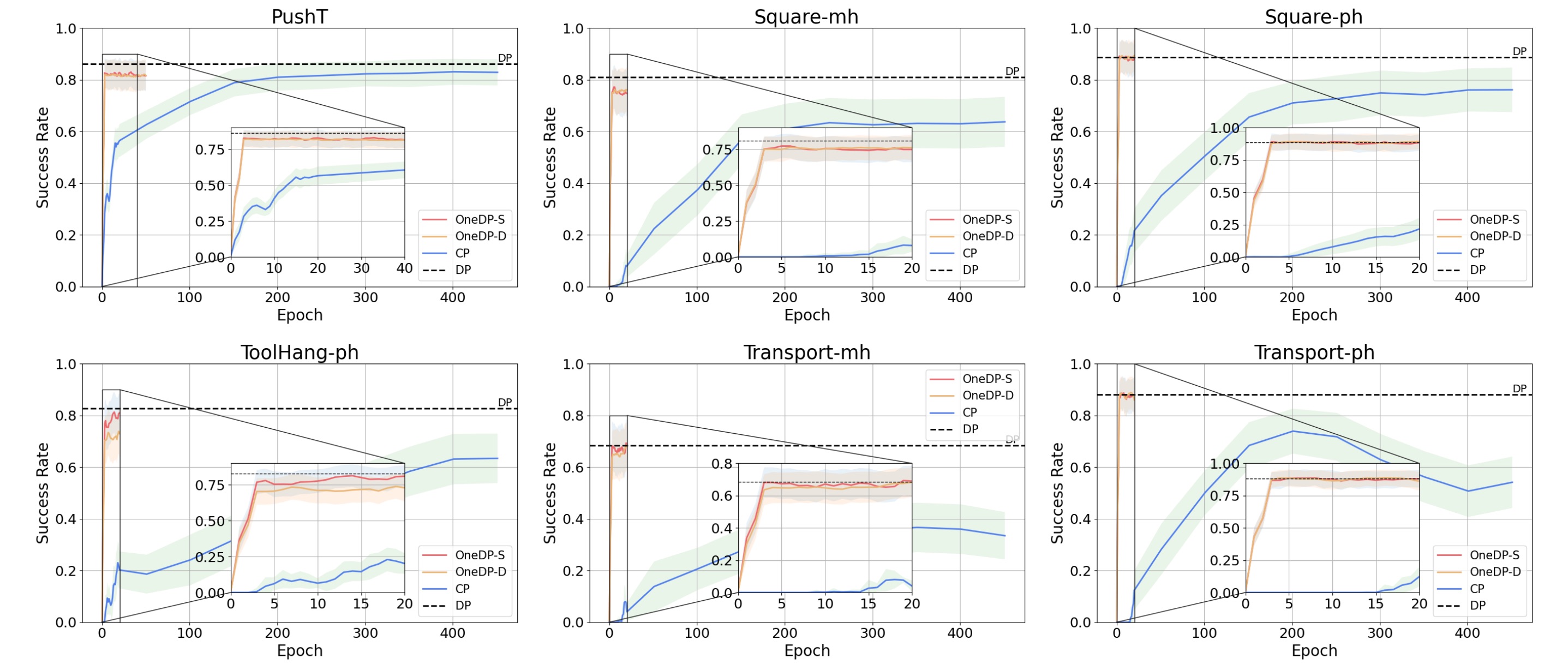
We compare OneDP with Diffusion Policy (DP) and Consistency Policy (CP). OneDP outperforms CP significantly in convergence speed and success rate and matches the performance of the original DP.
Real-World Experiments

Real-World Experiment Illustration. In the first row, we display the setup for the pick-and-place experiments, featuring three tasks: 'pnp-milk', 'pnp-anything', and 'pnp-milk-move'. In total, 'pnp-anything' handles around 10 random objects. The second row illustrates the procedure for the more challenging 'coffee' task, where the Franka arm is tasked with locating the coffee cup, precisely positioning it in the machine's cup holder, inserting it, and finally closing the machine's lid.
Video demo: pick-and-place milk
Video demo: operating the coffee machine
Success Rate Comparison
| Method | Epochs | NFE | pnp-milk | pnp-anything | pnp-milk-move | coffee | Avg |
|---|---|---|---|---|---|---|---|
| DP (DDIM) | 1000 | 10 | 1.00 | 0.95 | 0.80 | 0.80 | 0.83 |
| OneDP-D | 100 | 1 | 1.00 | 1.00 | 1.00 | 0.80 | 0.95 |
| OneDP-S | 100 | 1 | 1.00 | 1.00 | 1.00 | 0.90 | 0.98 |
Citation
@inproceedings{wang2025onedp,
title={One-Step Diffusion Policy: Fast Visuomotor Policies via Diffusion Distillation},
author={Wang, Zhendong and Li, Zhaoshuo and Mandlekar, Ajay and Xu, Zhenjia and Fan, Jiaojiao and Narang, Yashraj and Fan, Linxi and Zhu, Yuke and Balaji, Yogesh and Zhou, Mingyuan and Liu, Ming-Yu and Zeng, Yu},
booktitle={International Conference on Machine Learning (ICML)},
year={2025}
}