Abstract
Video generation models have achieved remarkable progress in creating high-quality, photorealistic content. However, their ability to accurately simulate physical phenomena remains a critical and unresolved challenge. This paper presents PhyWorldBench, a comprehensive benchmark designed to evaluate video generation models based on their adherence to the laws of physics. The benchmark covers multiple levels of physical phenomena, ranging from fundamental principles like object motion and energy conservation to more complex scenarios involving rigid body interactions and human or animal motion. Additionally, we introduce a novel "Anti-Physics" category, where prompts intentionally violate real-world physics, enabling the assessment of whether models can follow such instructions while maintaining logical consistency. Besides large-scale human evaluation, we also design a simple yet effective method that could utilize current MLLM to evaluate the physics realism in a zero-shot fashion. We evaluate 10 state-of-the-art text-to-video generation models, including five open-source and five proprietary models, with a detailed comparison and analysis. we identify pivotal challenges models face in adhering to real-world physics. Through systematic testing of their outputs across 1,050 curated prompts—spanning fundamental, composite, and anti-physics scenarios—we identify pivotal challenges these models face in adhering to real-world physics. We then rigorously examine their performance on diverse physical phenomena with varying prompt types, deriving targeted recommendations for crafting prompts that enhance fidelity to physical principles.
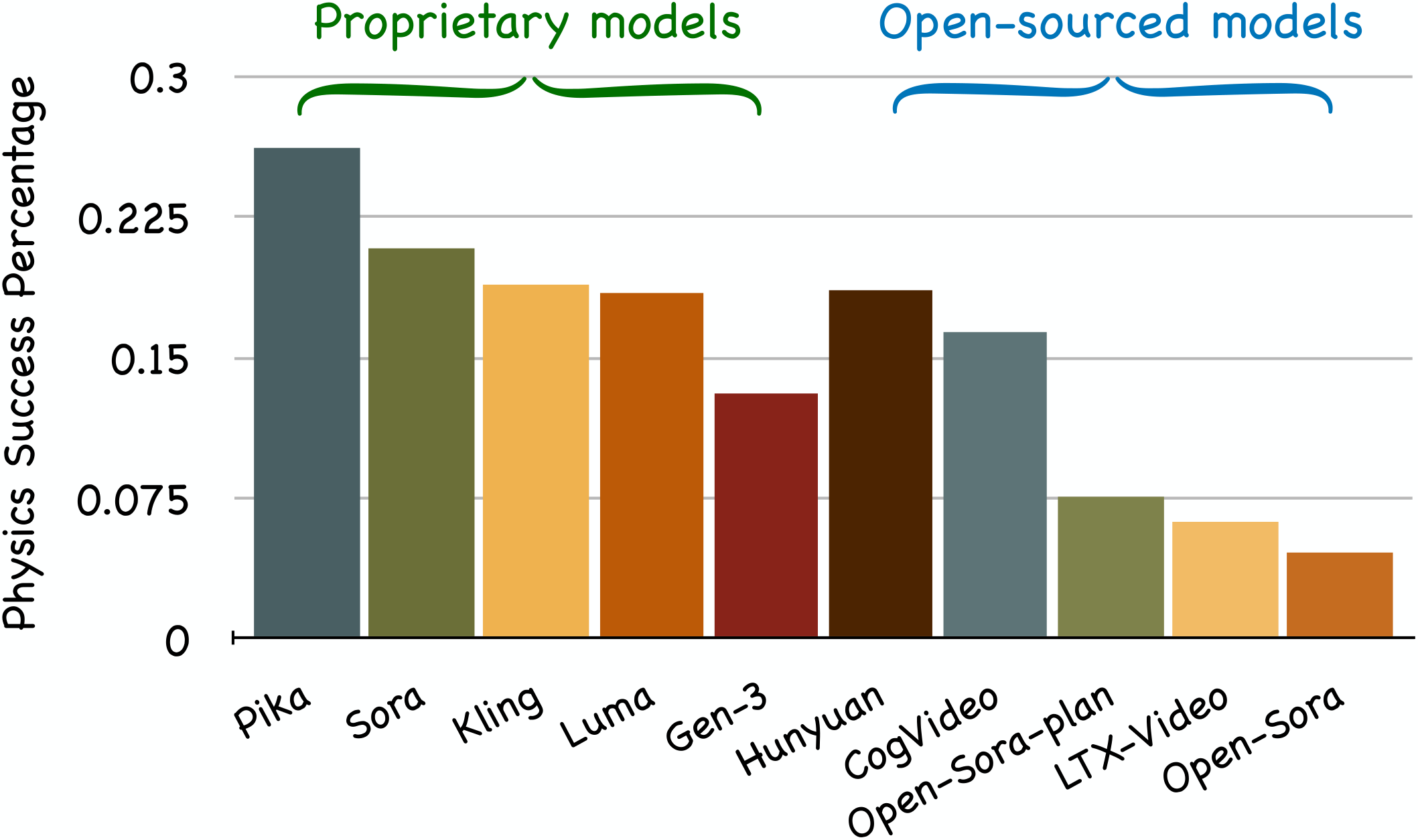
Success rates of video generation models on PhyWorldBench. Among open-source models, Hunyuan demonstrated the highest performance, while Pika achieved the best results among proprietary models with a success rate of 0.262.
Benchmark Overview
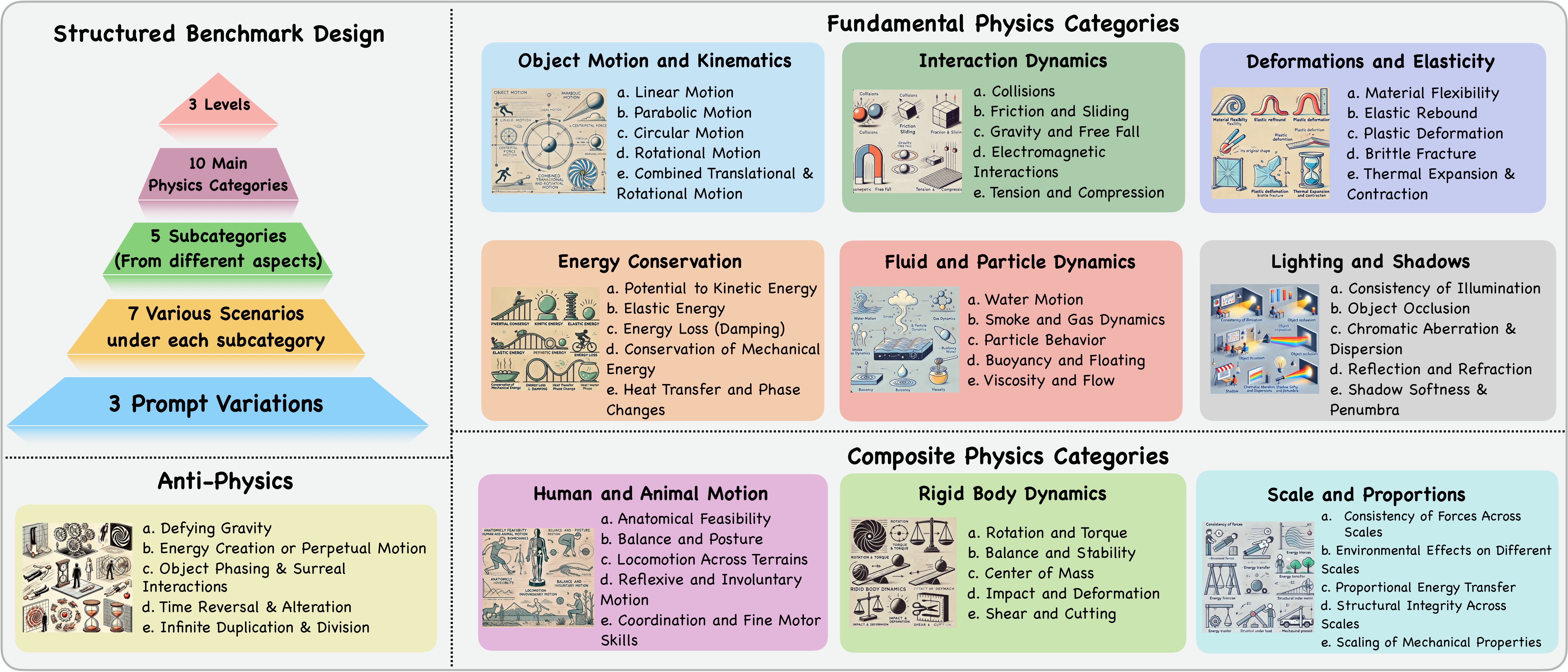
The benchmark follows a structured design, starting with 10 main physics categories, derived from physics literature and expert consultations. Each category is divided into 5 subcategories, capturing different aspects. Under each subcategory, 7 scenarios are created, with 3 prompt variations per scenario to provide varying levels of detail and complexity. The figure presents the benchmark structure, showcasing the 10 main categories and their corresponding 5 subcategories.
Creation Process of PhyWorldBench
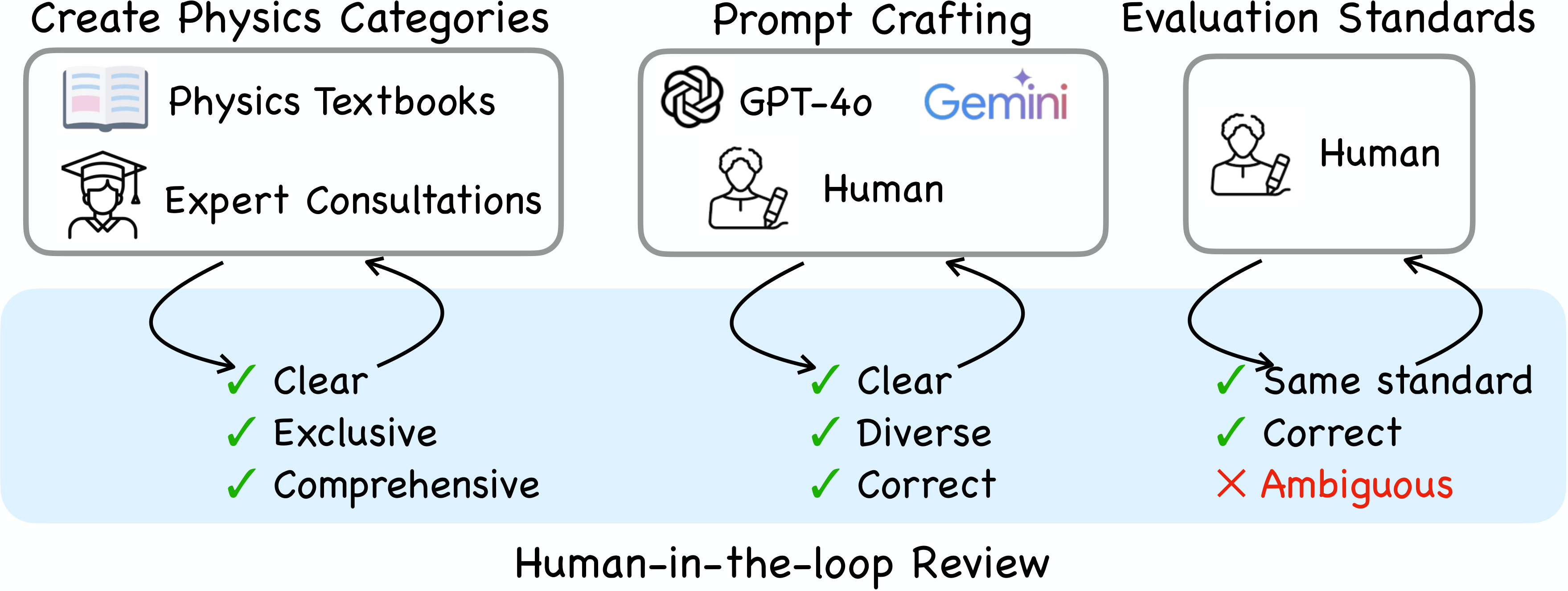

The dataset is built through a three-stage pipeline for clarity, consistency, and completeness. First, physics categories and prompts are defined using literature and expert input. Next, GPT-4o, Gemini-1.5-Pro together with human refine prompts for diversity and accuracy. Finally, a curation phase standardizes all prompts, with human-in-the-loop reviews ensuring clarity and eliminating ambiguities.
Example of Three Prompt Types for a Scenario

This figure illustrates a scenario from the subcategory Linear Motion under the main category Object Motion and Kinematics. The scenario is presented through three levels of prompts: (1) Event Prompt, providing a concise and straightforward event description; (2) Physics-Enhanced Prompt, which builds on the general prompt by incorporating physics-related phenomena while avoiding explicit physical laws; and (3) Detailed Narrative Prompt, enriching the Event Prompt with vivid details and contextual elements.
Illustration of Our Evaluation Metric and Human Annotations

We demonstrate our evaluation process for assessing the quality of generated videos based on two evaluation criteria: Basic Standards and Key Standards. For Basic Standards, we verify whether the generated video contains the correct number of objects and accurately represents the intended action or event. For Key Standards, we define specific physical phenomena as ground truth and measure if all of these phenomena the generated video satisfies. Both lead to either a score of 0 or 1 for a generated video. Red circles and yellow lines in the figure highlight instances where the generated videos fail to meet the Key Standards.
Evaluation & Results
CAP Evaluation

In the two examples, prompt (a) explicitly tells the MLLM that the video is generated by video models and could be of low quality, while prompt b does not. We found that the quality assessment is usually more accurate when the context is used. The text is irrelevant to quality is ignored for readability. This phenomenon applied to all our tested models including GPT-4o, GPT-o1, Gemini-2.0-flash, and Qwen-VL-2.0.
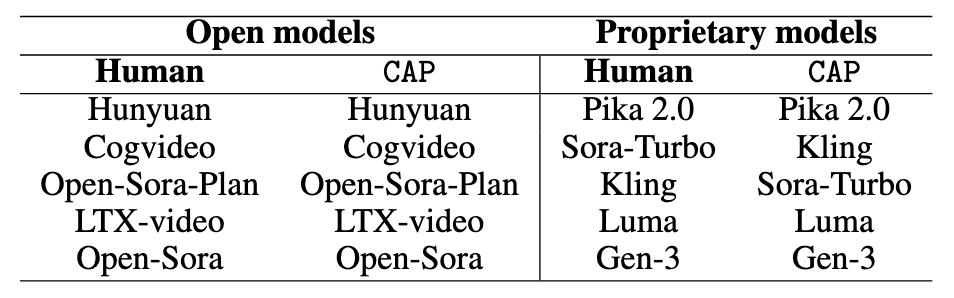
Our method consistently achieves great performance on both open-sourced and proprietary models.
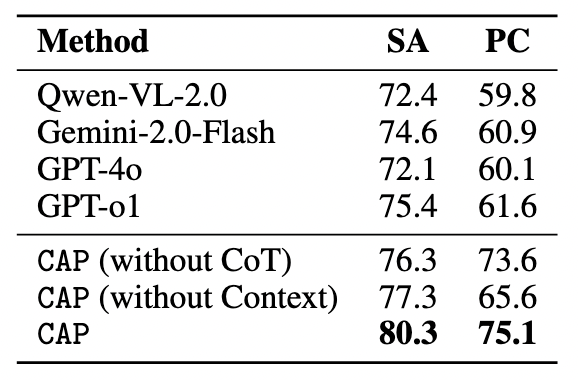
We report leaderboard on both human evaluation and CAP.
Human Evaluation
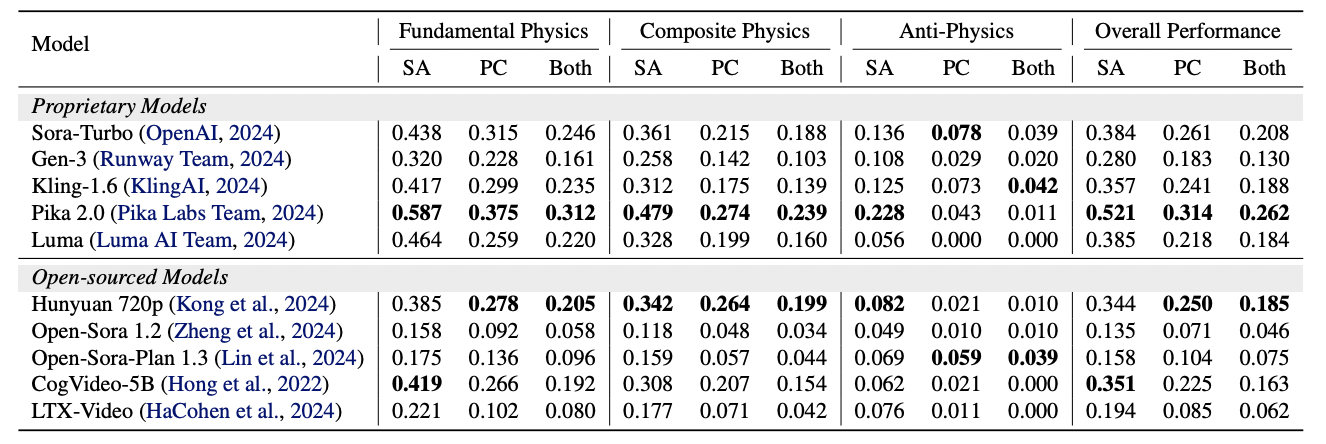
We present the human evaluation results of 10 video generation models across 3 physics types. SA denotes semantic adherence, while PC represents physical commonsense. Both indicate satisfaction of both criteria.
Physics-Following
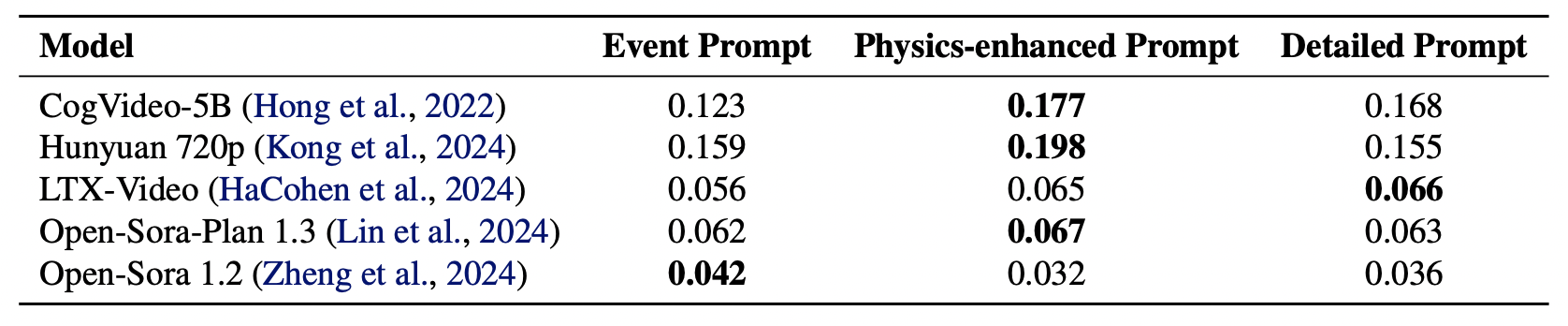
Explicitly adding physics usually increases the physics-following ability of video generation model, while a prompt refinement process does not necessarily lead to improvement.
Citation
@inproceedings{gu2025phyworldbench,
title={PhyWorldBench: A Comprehensive Evaluation of Physical Realism in Text-to-Video Models},
author={Gu, Jing and Liu, Xian and Zeng, Yu and Nagarajan, Ashwin and Zhu, Fangriu and Hong, Daniel and Fan, Yue and Yan, Qianqi and Zhou, Kaiwen and Liu, Ming-Yu and Wang, Xin Eric},
booktitle={International Conference on Learning Representations (ICLR)},
year={2026}
}