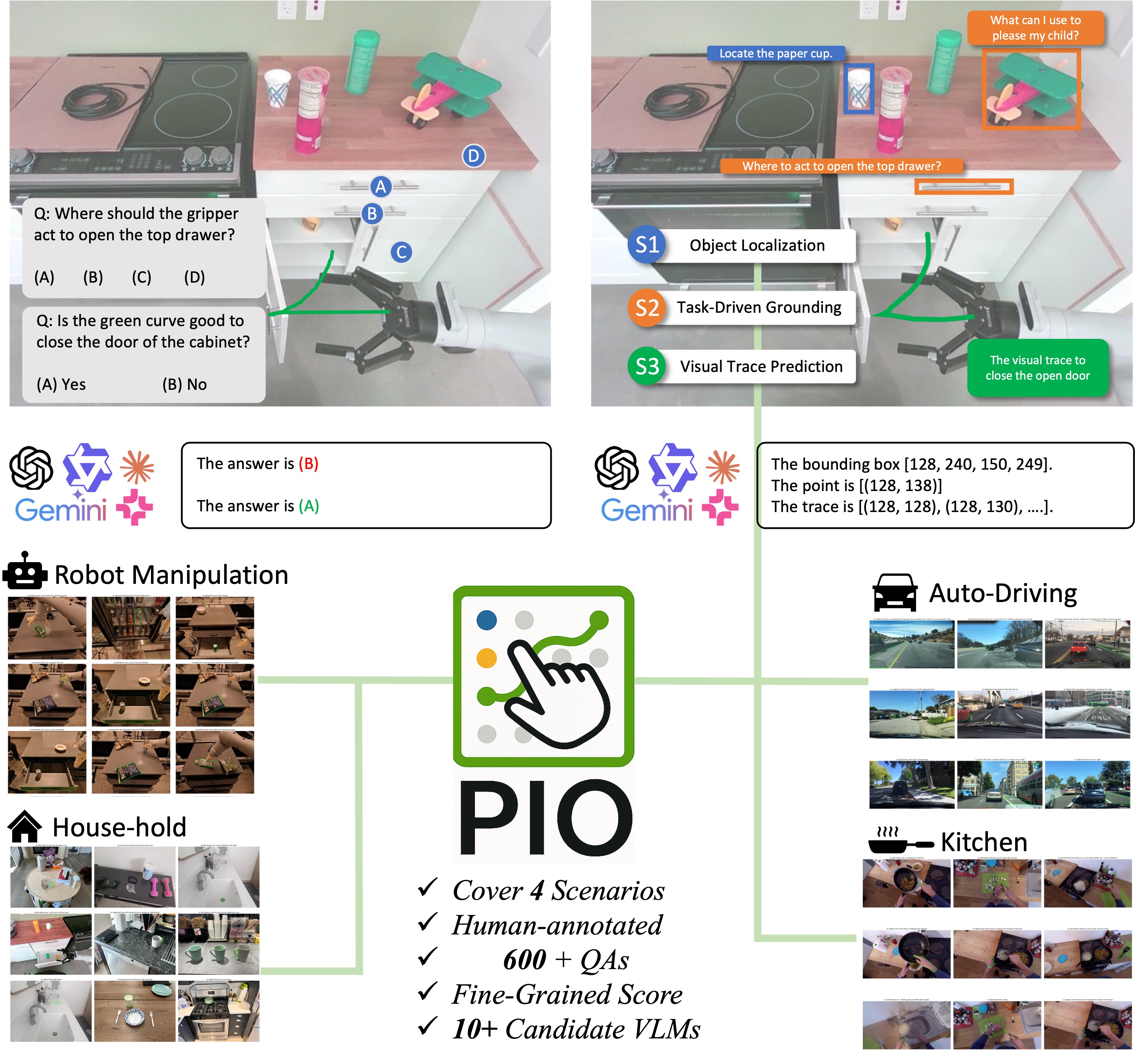
Abstract
Vision-Language Models (VLMs) have demonstrated impressive world knowledge across a wide range of tasks, making them promising candidates for embodied reasoning applications. However, existing benchmarks primarily evaluate the embodied reasoning abilities of VLMs through multiple-choice questions based on image annotations -- for example, selecting which visual trace best describes an event in the image. In this work, we introduce the Point-It-Out (PIO) benchmark, a novel benchmark designed to systematically assess the embodied reasoning abilities of VLMs through precise visual grounding. We propose a hierarchical evaluation protocol spanning three stages (S1: referred-object localization, S2: task-driven pointing, and S3: visual trace prediction), with data collected from critical domains for embodied intelligence, including indoor, kitchen, driving, and robotic manipulation scenarios. Extensive experiments with over ten state-of-the-art VLMs reveal several interesting findings. For example, strong general-purpose models such as GPT-4o, while excelling on many benchmarks (e.g., language, perception, and reasoning), underperform compared to some open-source models in precise visual grounding; models such as MoLMO perform well in S1 and S2 but struggle in S3, which requires grounding combined with visual trace planning.
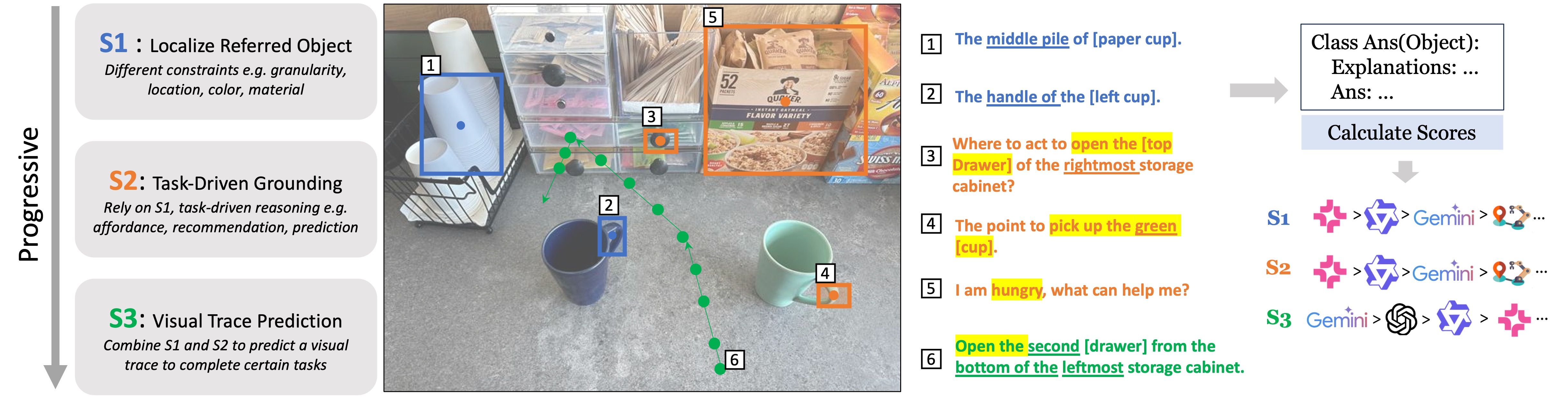
Hierarchical Definition of Embodied Visual Grounding
The PIO benchmark introduces a hierarchical evaluation protocol that consists of three stages:
- S1: Referred-Object Localization — Localizing objects referred to in the input text
- S2: Task-Driven Grounding — Pointing to specific objects or regions in the image based on task requirements
- S3: Visual Trace Prediction — Predicting 2D visual trace to complete the task
More Examples of S1 / S2 / S3 Grounding
Here are more examples of S1, S2 and S3 grounding:
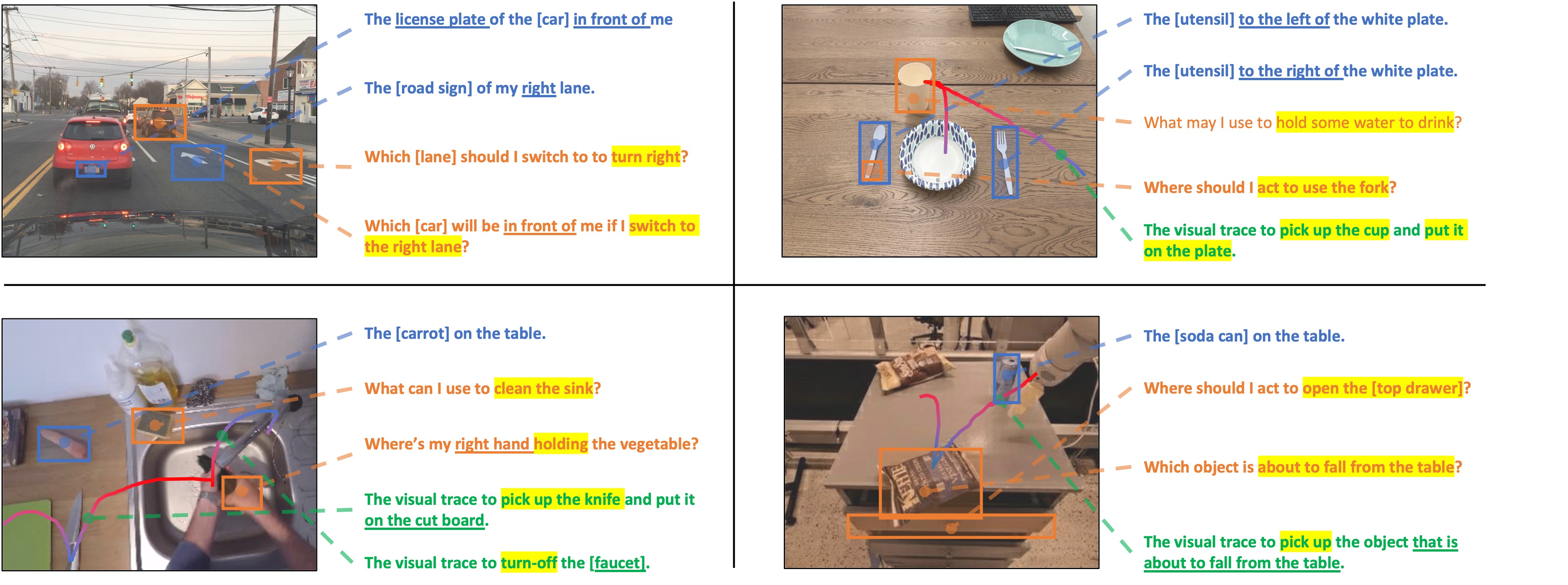
More Examples of Subclasses in S1 and S2
- S1 Subclasses: Object without Ambiguity | Object with Ambiguity | Object Part
- S2 Subclasses: Affordance | Contact | Safety | Prediction | Recommendation

Benchmark Curation
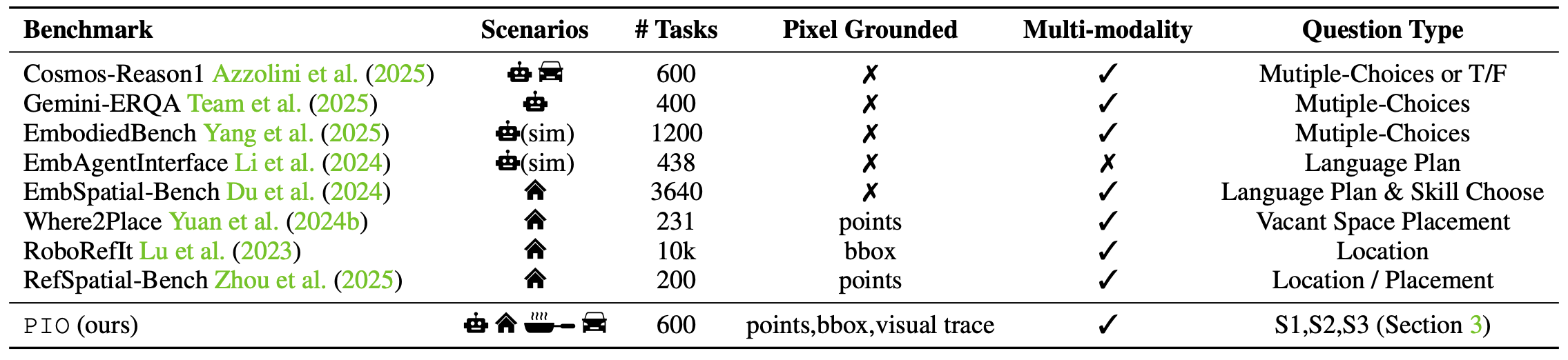
We collected data from four critical domains for embodied intelligence, including indoor household, kitchen, driving, and robotic manipulation scenarios. In total, we have approximately 600 QA pairs across S1, S2, and S3.
The following table shows the VLMs we evaluated:

Comparison with Other Embodied Reasoning Benchmarks
Compared with existing benchmarks, we include precise visual grounding as an important ability in embodied reasoning. We also cover four different embodied scenarios including autonomous driving, robotic manipulation, indoor household, and kitchen assistance.
Results: Object Localization and Task-Driven Grounding (S1 and S2)
MoLMO and Qwen outperform other models, possibly because they are fine-tuned with a large amount of grounding data. Strong black-box models (e.g., GPT and Claude series) perform poorly on S1 and S2.
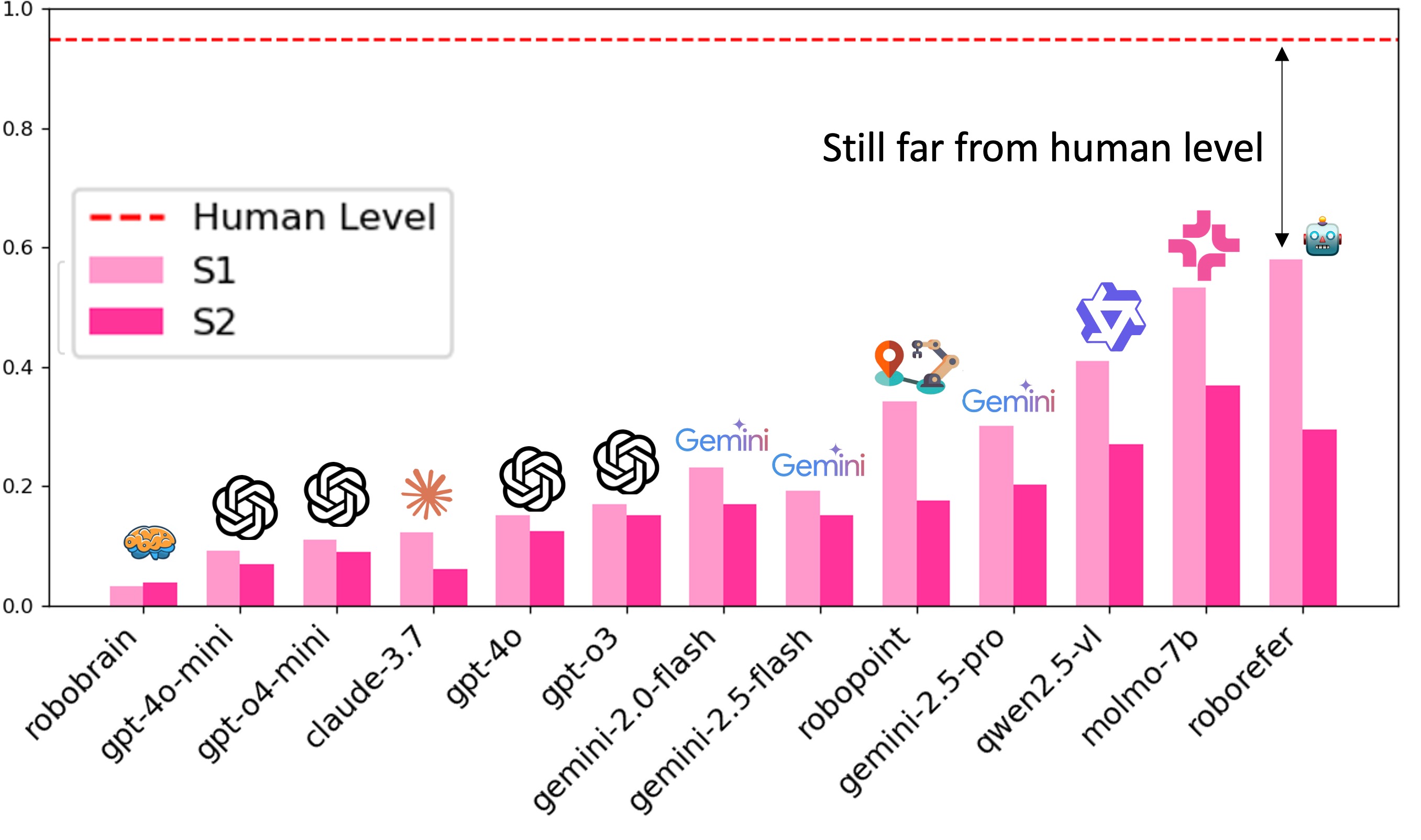
The following figures show the performance of each model in S1 and S2 across different datasets:
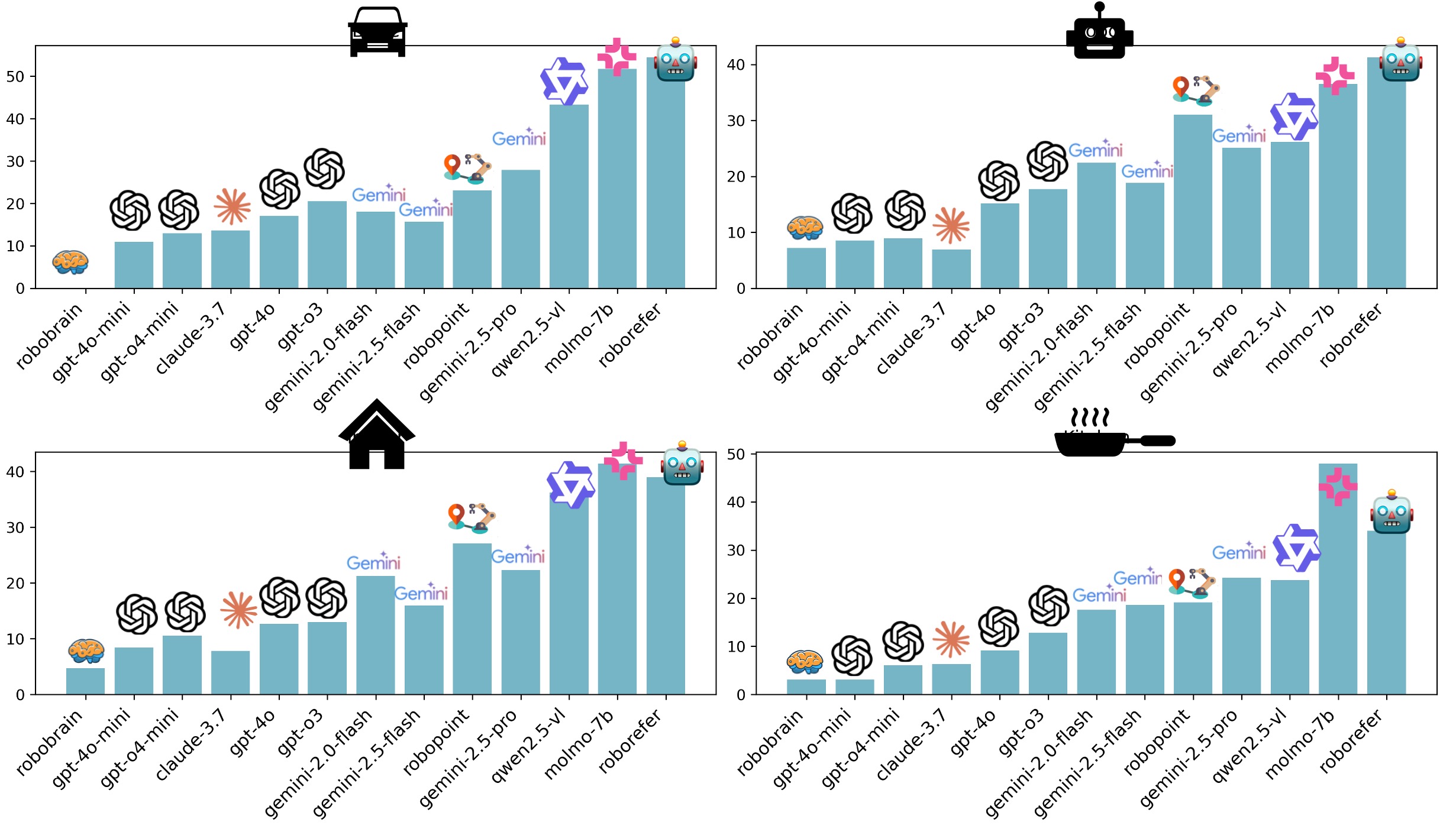

Finding 1: For S1 and S2, models that incorporate explicit grounding supervision such as MoLMO‑7B‑D, Gemini‑2.5‑Pro, and Qwen‑2.5‑VL consistently achieve the highest scores, outperforming more general‑purpose VLMs such as GPT‑4o and Claude‑3.7. This underscores the importance of grounding data when precise spatial reasoning is required.
Detailed Results by Subclass (S1 and S2)
For S1, most models perform poorly on object part grounding, which is a lower granularity task requiring fine-grained spatial understanding. For S2, most models perform well at recommendation, which only requires simple reasoning in language space (e.g., "I am thirsty—what can I get from the table?"). Models can easily find the water bottle. However, they struggle with affordance and contact prediction, which require more complex reasoning and understanding of physics and tasks.
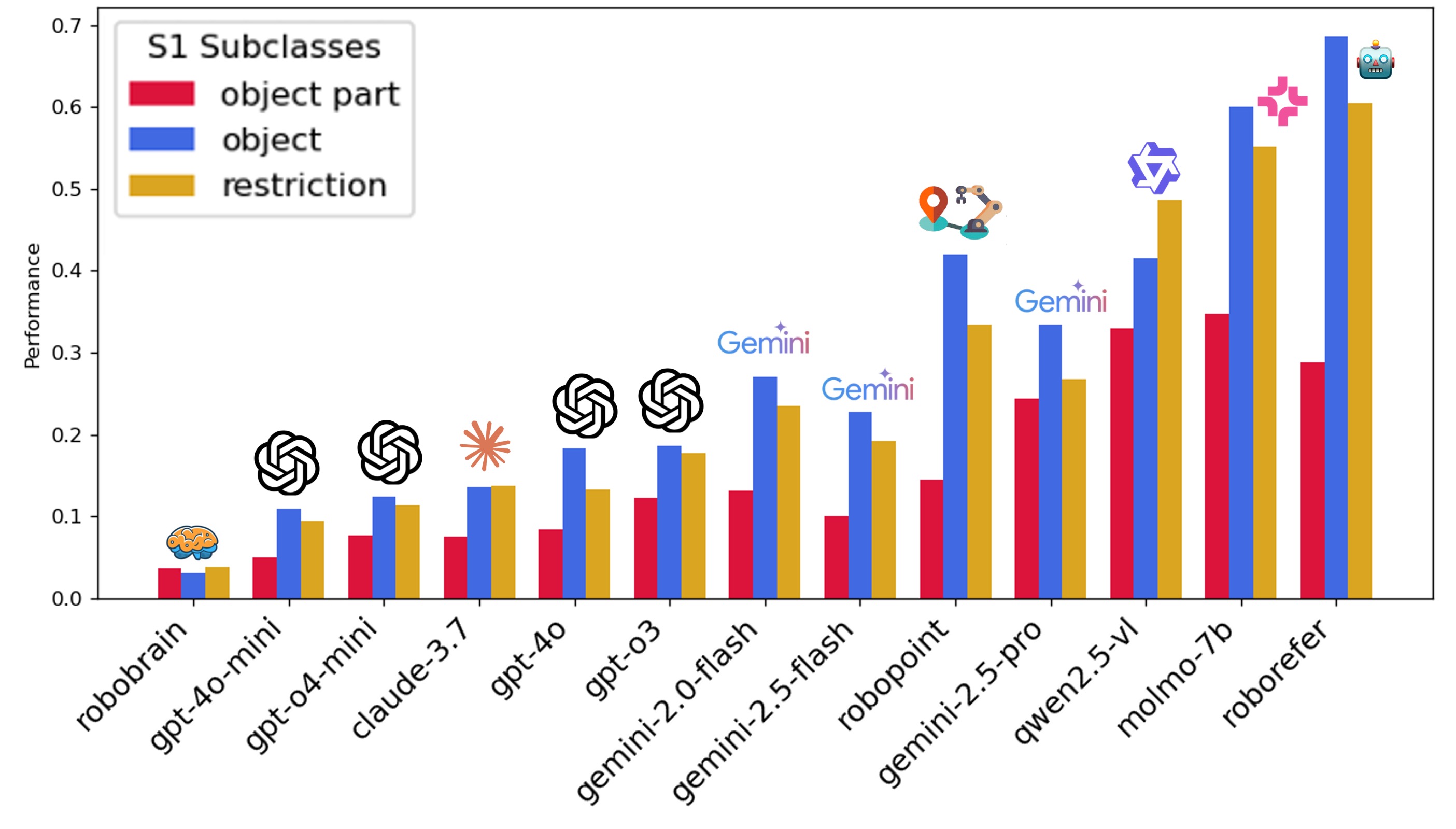
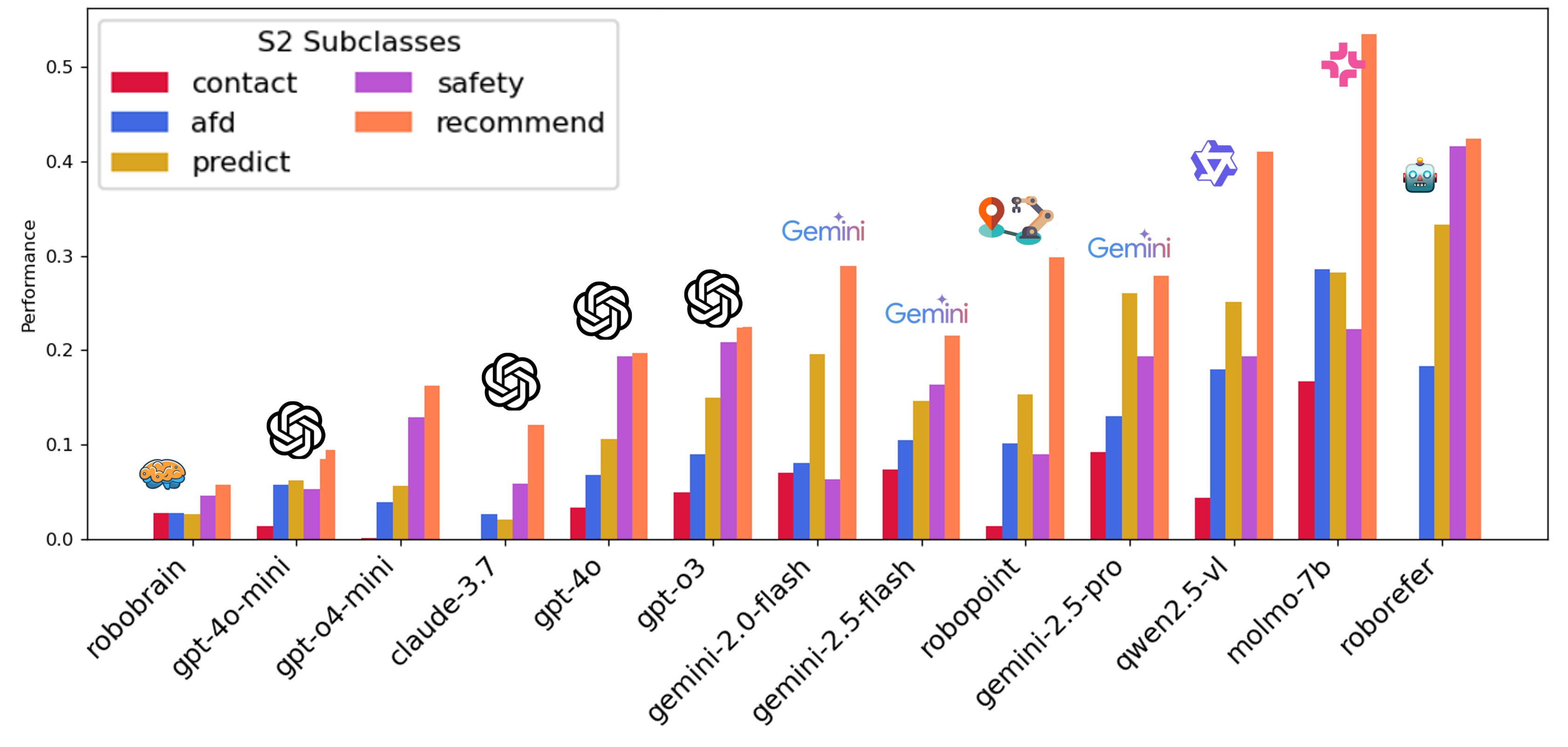
Finding 2: (i) Across all subclasses, every model exhibits a clear performance drop from S1 to S2. (ii) Two critical embodied skills suffer most: in S1 they often miss the correct object part to point to, and in S2 they struggle with affordance and contact prediction.
Results: Visual Trace Prediction (S3)
We provide visualization and both human and VLM-based evaluation for S3. Most models struggle with visual trace prediction, showing that S3 is harder than S1 and S2. Gemini-2.5-Pro performs best, while MoLMO and Qwen lag behind, despite being the top performers in S1 and S2.
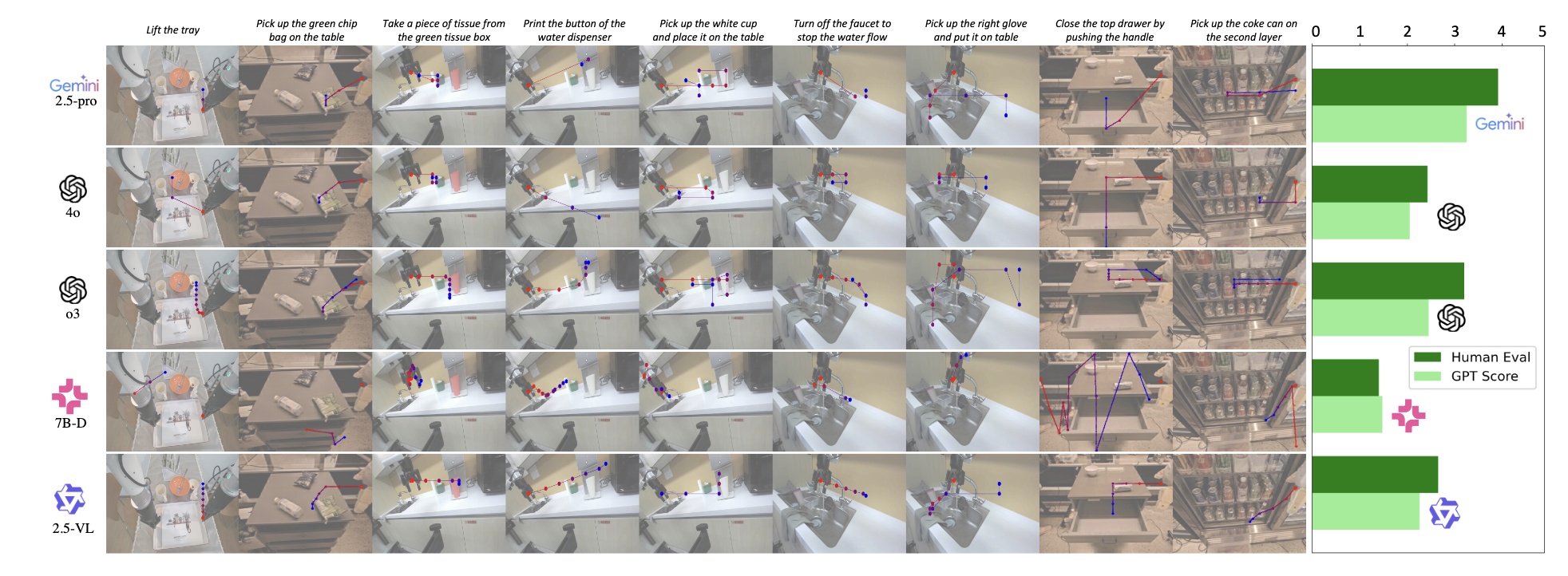
Finding 3: S3 requires models to integrate single-target grounding into coherent visual trace generation. While S1 and S2 are necessary prerequisites, they are not sufficient for a model to succeed in S3. Gemini-2.5-Pro shows promising results in S3 and also performs well in S1 and S2. MoLMO and Qwen, the top-performing models in S1 and S2, fail in S3.
Guidelines for Model Users
For tasks that do not require action generation (e.g., pick-and-place based on points), prioritize models that perform well on S1 and S2. If the goal is to train a robot policy using a VLM backbone, models that perform well on S3—even if weaker on S1/S2—could be better candidates. Furthermore, users might consider adding grounding data and fine-tuning to further improve performance for different stages.
Citation
@article{xue2025pio,
title={Point-It-Out: Benchmarking Embodied Reasoning for Vision Language Models in Precise Visual Grounding},
author={Xue, Haotian and Ge, Yunhao and Zeng, Yu and Li, Max and Liu, Ming-Yu and Chen, Yongxin and Fan, Jiaojiao},
journal={arXiv preprint arXiv:2509.25794},
year={2025}
}