Abstract
We present PlenopticDreamer, a method for plenoptic video generation that re-renders input video under novel camera trajectories while preserving long-term spatio-temporal memory in an autoregressive manner. Its core is an autoregressive multi-camera video generator that retrieves video–camera pairs from the memory bank using a 3D FOV-based video retrieval strategy. Conditioned on the retrieved pairs and the target camera, the model performs noisy scheduling and learnable reconstruction to generate the target video. To enable long video generation, a portion of the preceding frames is preserved as clean inputs during training.
Results & Capabilities
Memory-Preserving Multi-Shot Generation
PlenopticDreamer enables multi-shot video re-rendering while preserving spatio-temporal memory from previously generated shots.
Long Video Generation
Our method supports consistently long-range video re-rendering across various frames.
Focal Length Effect
Our method simulates varying depth-of-field effects corresponding to different focal lengths (18mm→100mm). Shorter focal length leads to larger change in field-of-view (FOV) in generated video.
Method
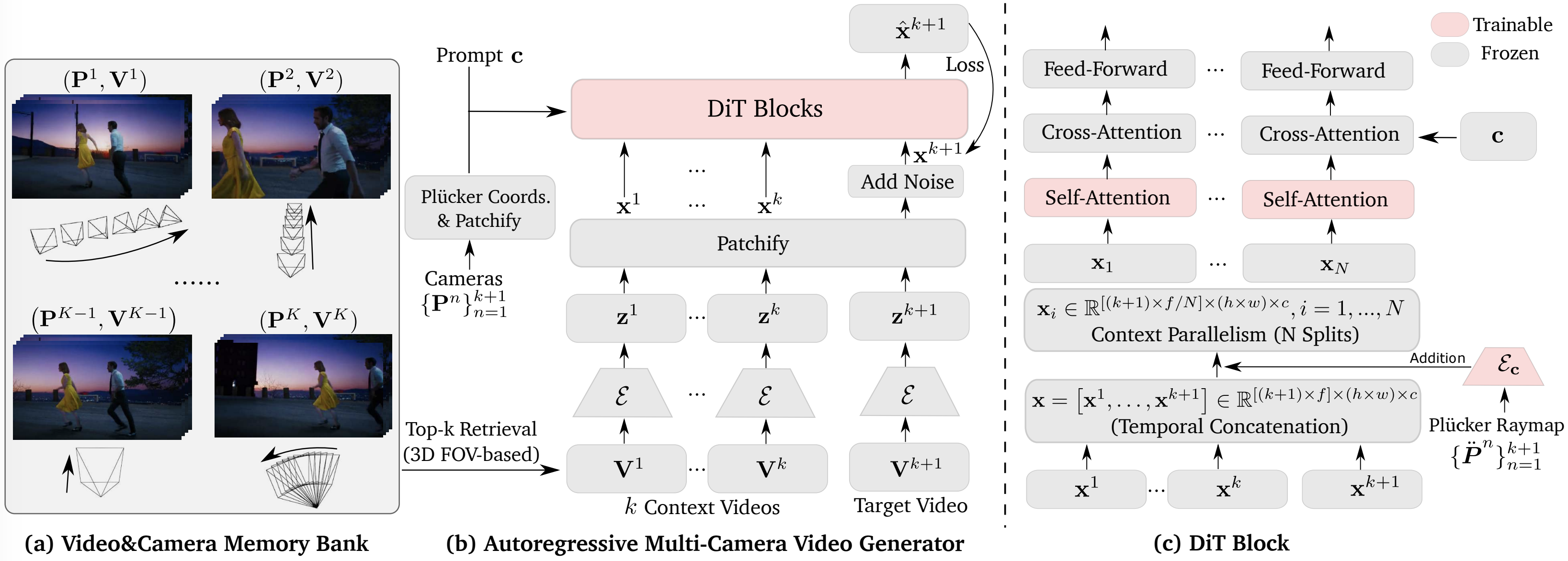
Its core is an autoregressive multi-camera video generator that retrieves $k$ video–camera pairs $\{(\mathbf{P}^n, \mathbf{V}^n)\}_{n=1}^k$ from the memory bank using a 3D FOV–based video retrieval strategy. Conditioned on these retrieved pairs and the target camera $\mathbf{P}^{k+1}$, the model performs noisy scheduling and learnable reconstruction to generate the target video $\mathbf{V}^{k+1}$. To enable long video generation, a portion of the preceding frames in $\mathbf{V}^{k+1}$ is preserved as clean inputs at a certain ratio during training. Within each DiT block, temporal concatenation is applied to form video tokens $\mathbf{x}$ as in-context condition.
Evaluation
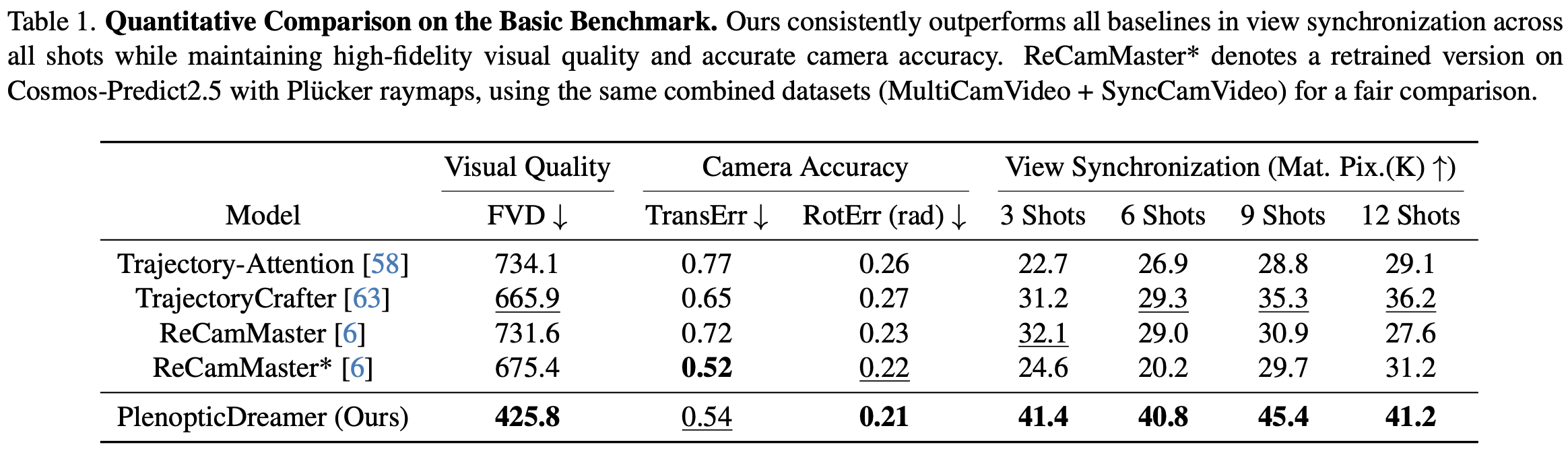
Comparison with SOTAs

Ablation Study
(1) w/o Self-Cond. Training: Removing the self-conditioned training strategy
described in Sec. 3.3 leads to noticeably degraded visual quality.
(2) w/ Random Context Videos: Replacing the video retrieval strategy with
random retrieval results in degraded view synchronization.
(3) w/o Progressive Training: Removing the progressive training strategy
described in Sec. 3.3 leads to poor camera accuracy.
Citation
@inproceedings{fu2025plenoptic,
title={Plenoptic Video Generation},
author={Fu, Xiao and Tang, Shitao and Shi, Min and Liu, Xian and Gu, Jinwei and Liu, Ming-Yu and Lin, Dahua and Lin, Chen-Hsuan},
booktitle={IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2026}
}