
Abstract
Existing conditional image synthesis frameworks generate images based on user inputs in a single modality, such as text, segmentation, sketch, or style reference. They are often unable to leverage multimodal user inputs when available. To address this limitation, we propose the Product-of-Experts Generative Adversarial Networks (PoE-GAN) framework, which can synthesize images conditioned on multiple input modalities or any subset of them, even the empty set. PoE-GAN consists of a product-of-experts generator and a multimodal multiscale projection discriminator. Through our carefully designed training scheme, PoE-GAN learns to synthesize images with high quality and diversity.
Besides advancing the state of the art in multimodal conditional image synthesis, PoE-GAN also outperforms the best existing unimodal conditional image synthesis approaches when tested in the unimodal setting. PoE-GAN is the research project behind the AI tools GauGAN2 and GauGAN360.
Videos
Video (ECCV 2022)
Video (GauGAN2 Official)
Video (GauGAN360)
Product-of-Experts
Our goal is to train a single generative model that captures the image distribution conditioned on an arbitrary subset of modalities. In this paper, we consider four different modalities including text, semantic segmentation, sketch, and style reference. We model the jointly conditioned probability distribution as proportional to the product of singly conditioned probability distributions, previously referred to as product-of-experts.
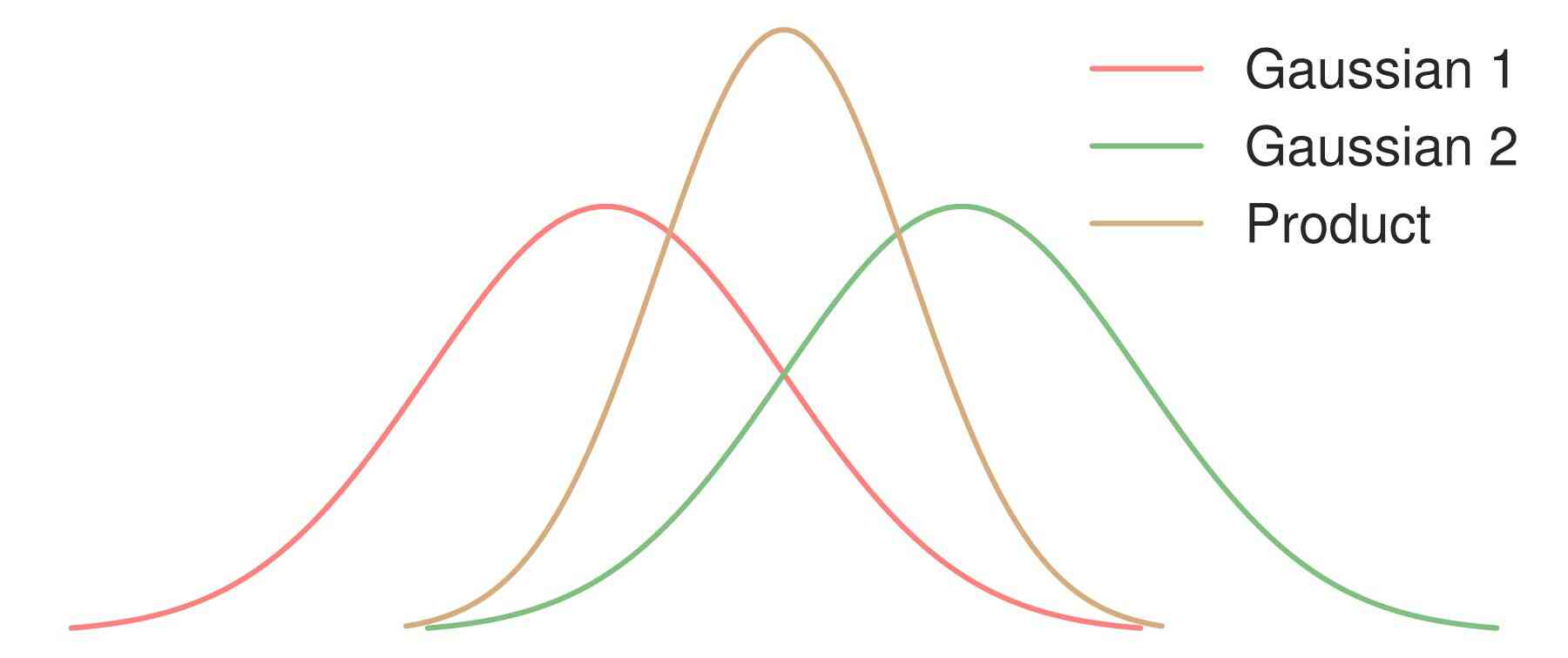
The product of distributions is analogous to the intersection of sets.
Generator Design
We encode each modality into a feature vector which is then aggregated in Global PoE-Net using product-of-experts. The decoder generates the image using the output of Global PoE-Net and skip connections from the segmentation and sketch encoders.

Discriminator Design
We propose a multimodal projection discriminator that generalizes the projection discriminator to handling multiple conditional inputs. Unlike the standard projection discriminator that computes a single inner product between the image embedding and the conditional embedding, we compute one inner product per input modality.
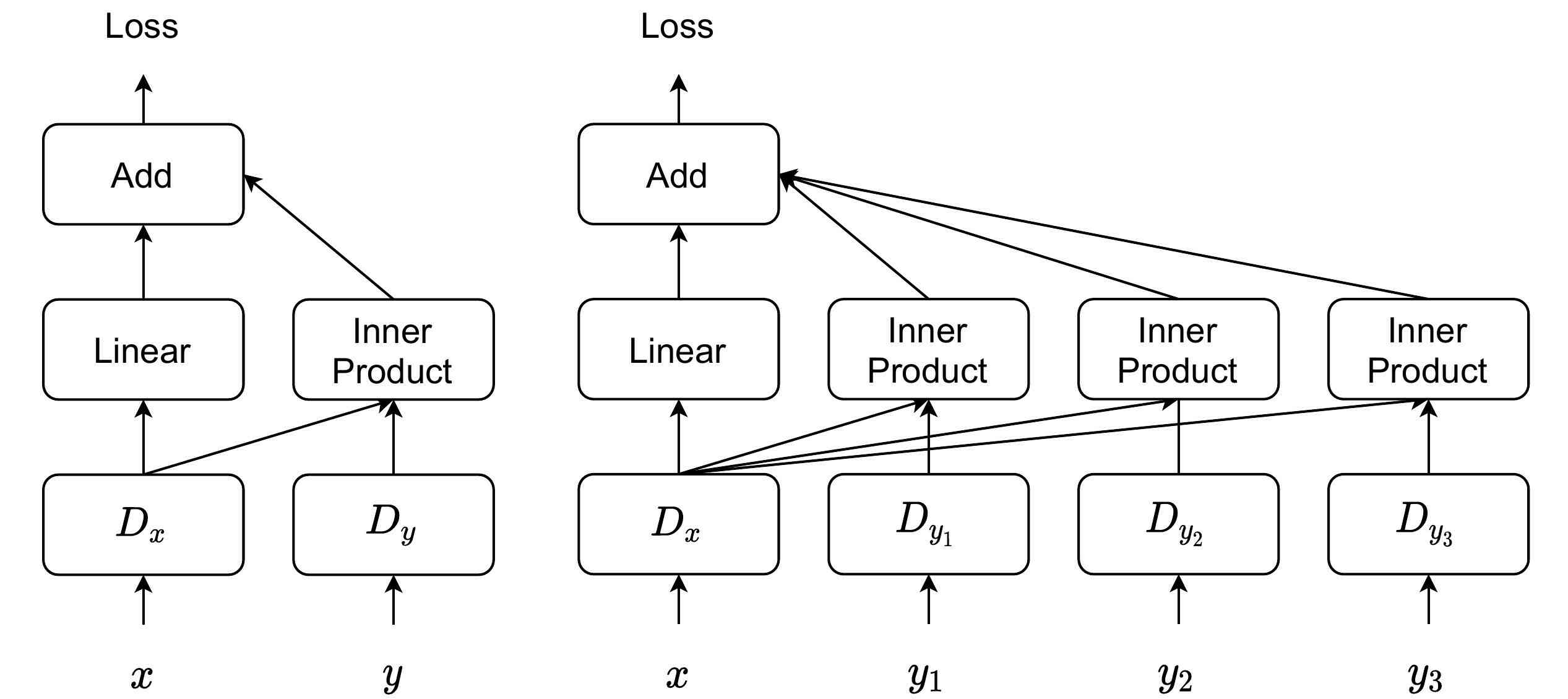
Comparison between the standard projection discriminator (left) and our multimodal projection discriminator (right).
Results
When tested using a single input modality, PoE-GAN outperforms previous state-of-the-art approaches specifically designed for that modality, such as the segmentation-to-image methods (SPADE, OASIS) and the text-to-image synthesis methods (DF-GAN, DM-GAN + CL).





















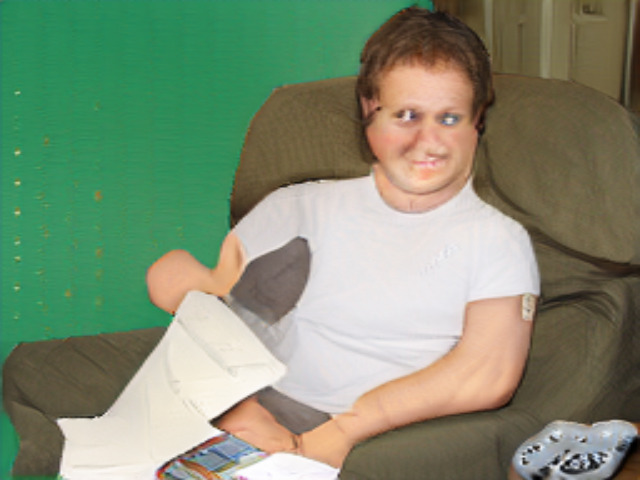









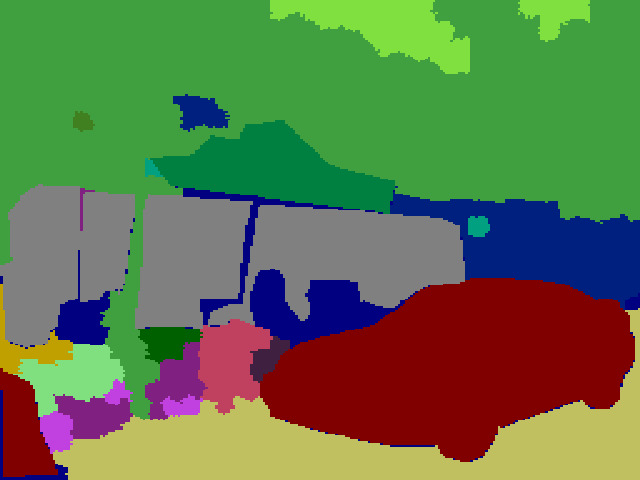



Comparison with Segmentation-to-Image Synthesis Methods on MS-COCO.
Citation
@inproceedings{huang2022poegan,
title={Multimodal Conditional Image Synthesis with Product-of-Experts {GANs}},
author={Huang, Xun and Mallya, Arun and Wang, Ting-Chun and Liu, Ming-Yu},
booktitle={European Conference on Computer Vision (ECCV)},
year={2022}
}