Abstract
This work represents the first effort to scale up continuous-time consistency distillation to general application-level image and video diffusion models. Although continuous-time consistency model (sCM) is theoretically principled and empirically powerful for accelerating academic-scale diffusion, its applicability to large-scale text-to-image and video tasks remains unclear due to infrastructure challenges in Jacobian-vector product (JVP) computation and the limitations of standard evaluation benchmarks. We first develop a parallelism-compatible FlashAttention-2 JVP kernel, enabling sCM training on models with over 10 billion parameters and high-dimensional video tasks. Our investigation reveals fundamental quality limitations of sCM in fine-detail generation, which we attribute to error accumulation and the "mode-covering" nature of its forward-divergence objective. To remedy this, we propose the score-regularized continuous-time consistency model (rCM), which incorporates score distillation as a long-skip regularizer. This integration complements sCM with the "mode-seeking" reverse divergence, effectively improving visual quality while maintaining high generation diversity. Validated on large-scale models (Cosmos-Predict2, Wan2.1) up to 14B parameters and 5-second videos, rCM matches or surpasses the state-of-the-art distillation method DMD2 on quality metrics while offering notable advantages in diversity, all without GAN tuning or extensive hyperparameter searches. The distilled models generate high-fidelity samples in only 1~4 steps, accelerating diffusion sampling by 15x~50x.
Highlights
rCM is the first work that:
- Scales up continuous-time consistency distillation (e.g., sCM/MeanFlow) to 10B+ parameter video diffusion models.
- Provides open-sourced FlashAttention-2 Jacobian-vector product (JVP) kernel with support for parallelisms like FSDP/CP.
- Identifies the quality bottleneck of sCM and overcomes it via a forward-reverse divergence joint distillation framework.
- Delivers models that generate videos with both high quality and strong diversity in only 2~4 steps.
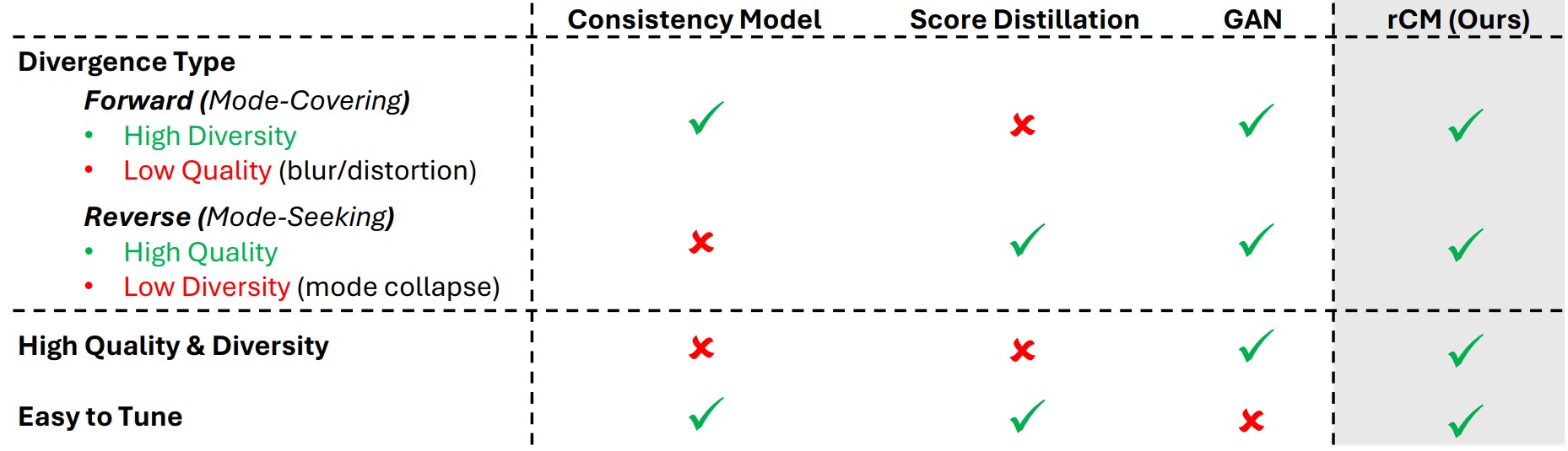
High-level comparison of diffusion distillation methods. Despite the theoretical existence of forward divergence, GANs in practice still suffer from limited diversity and model collapse.
Method
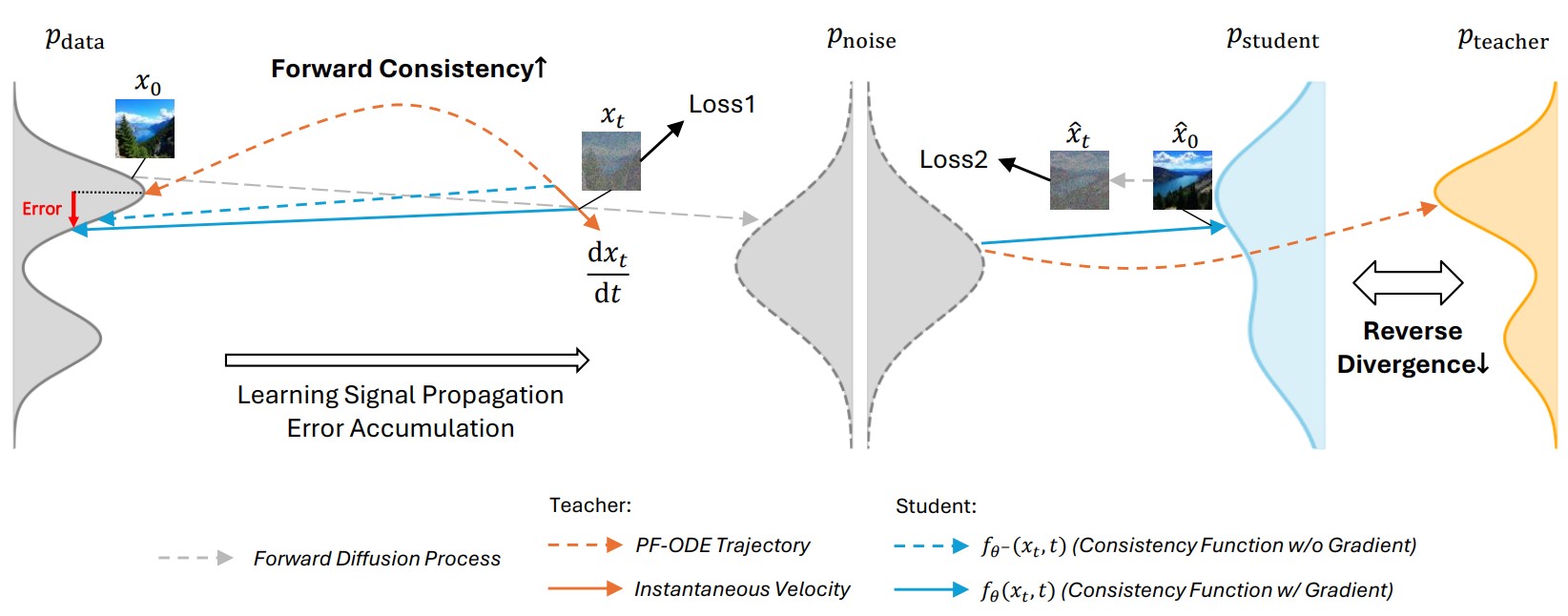

Results
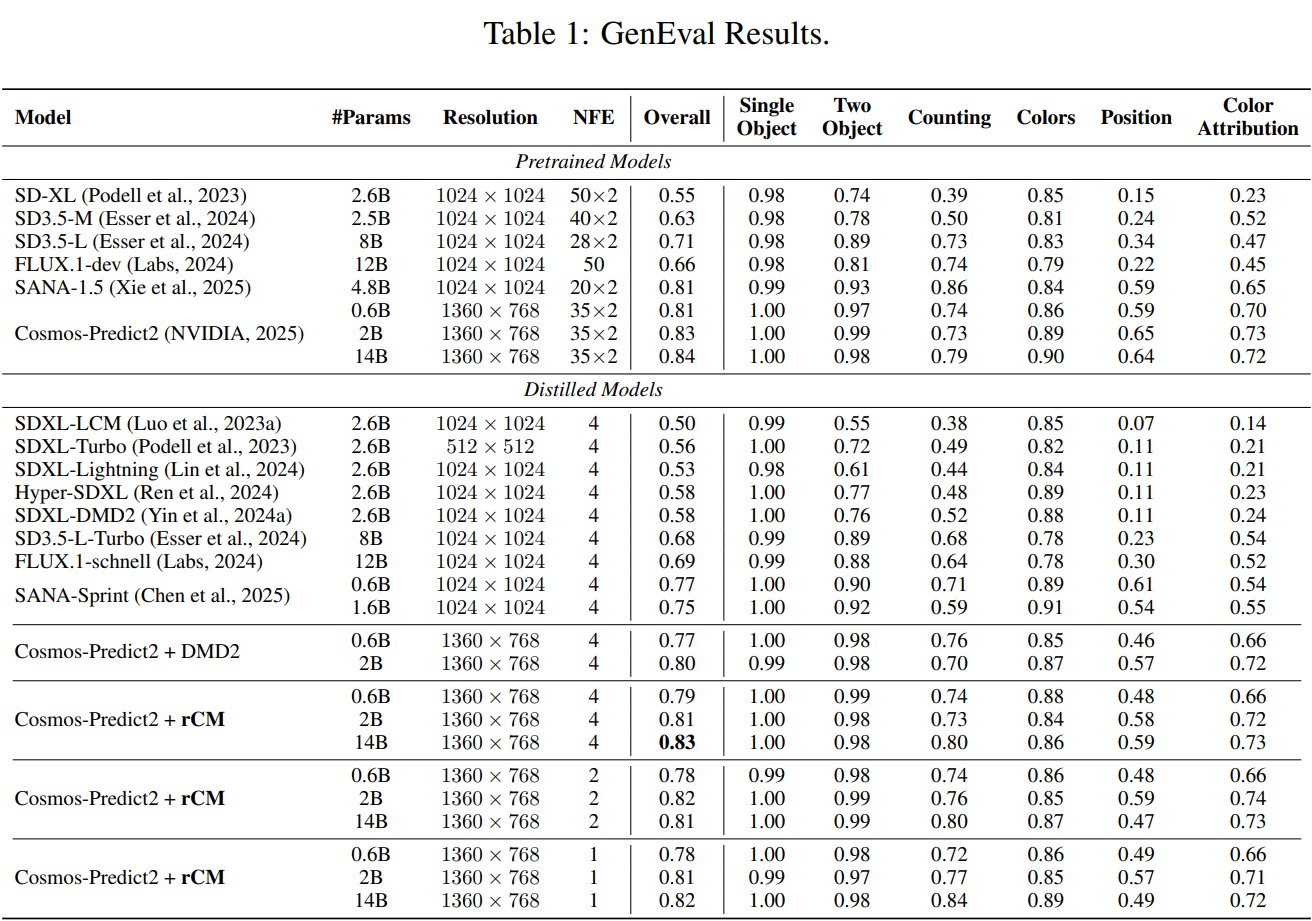
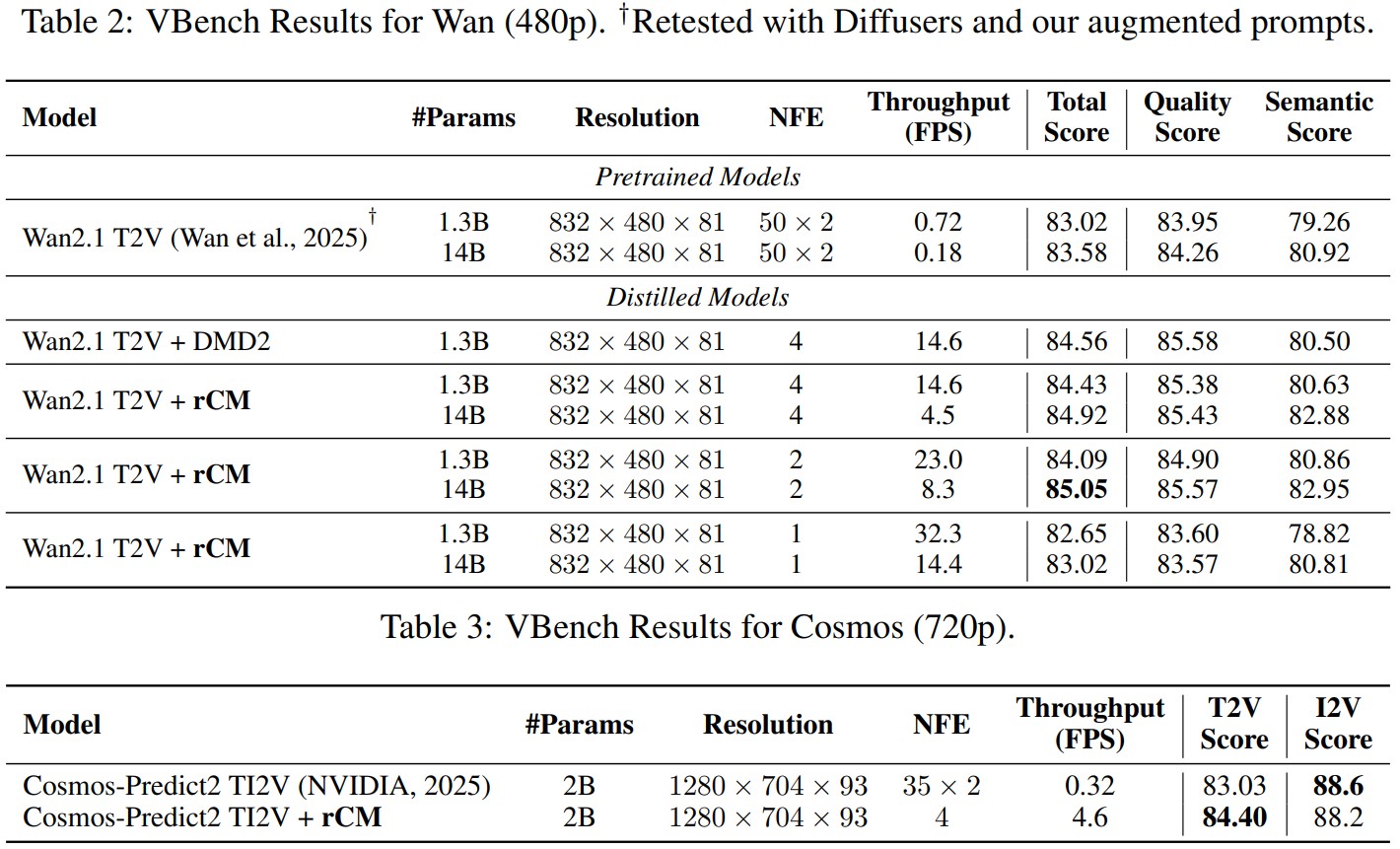
Quantitative Benchmarks
State-of-the-art few-step GenEval and VBench results by distilling Cosmos-Predict2/Wan2.1 image/video models.
Text-to-Image
Fine-grained small text rendering in only 4 steps.

A Casio G-Shock digital watch with a metallic silver bezel and a black face. The watch displays the time as 11:44 AM on Thursday, March 22nd, with additional features like Bluetooth connectivity, water resistance up to 20 bar, and multi-band 6 radio wave reception. The watch strap appears to be made of stainless steel, and the overall design emphasizes durability and functionality.
Quality vs Diversity
Superior quality and diversity compared to sCM/DMD2.
Step Efficiency
Strong performance under fewer (1~2) steps.

Citation
@inproceedings{zheng2026rcm,
title={Large Scale Diffusion Distillation via Score-Regularized Continuous-Time Consistency},
author={Zheng, Kaiwen and Wang, Yuji and Ma, Qianli and Chen, Huayu and Zhang, Jintao and Balaji, Yogesh and Chen, Jianfei and Liu, Ming-Yu and Zhu, Jun and Zhang, Qinsheng},
booktitle={International Conference on Learning Representations (ICLR)},
year={2026}
}