Abstract
We present SPACE, a method for generating high-resolution, expressive videos with realistic head pose, using just speech and a single image. It uses a multi-stage approach, combining the controllability of facial landmarks with the high-quality synthesis power of a pretrained face generator. SPACE also allows for the control of emotions and their intensities. Our method outperforms prior methods in objective metrics for image quality and facial motions and is strongly preferred by users in pair-wise comparisons.
Overview
Speech-driven portrait animation concerns animating a still image of a face using an arbitrary input speech signal. SPACE allows you to animate a photo using just speech, with unprecedented controllability over outputs — head pose, emotion label and intensity, blinking, and eye gaze control.
Comparison with Prior Work
| Input image | PC-AVS | MakeItTalk | Wav2Lip | SPACE (ours) |
 |
||||
 |
||||
 |
||||
 |
||||
 |
||||
Method
SPACE decomposes the task of speech to face animation into 3 stages: 1) Speech2Landmarks (S2L), 2) Landmarks2Latents (L2L), and 3) Video Synthesis. Predicting facial landmarks helps add modifications such as blinking. We can also apply any desired rotation, translation, and scaling to the 3D facial landmarks. Instead of learning to generate a high-quality output image from facial landmarks, we use a state-of-the-art pretrained face-vid2vid generator.
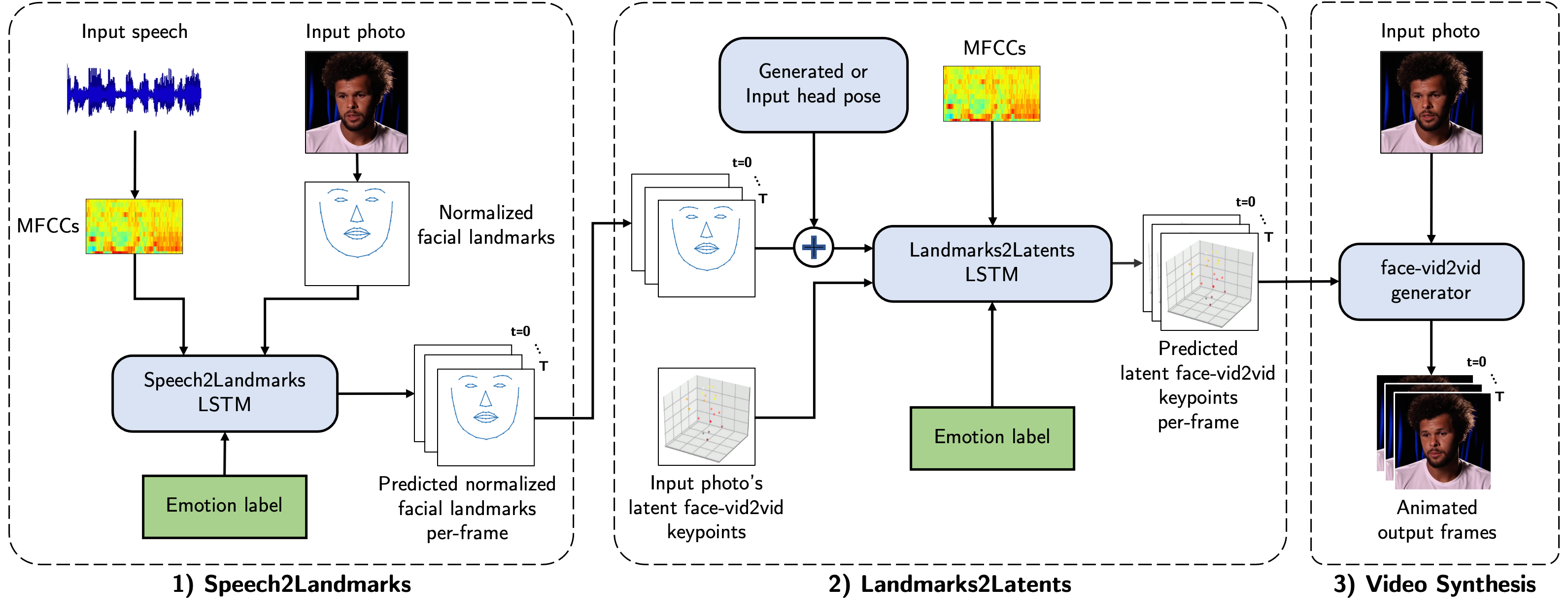
Intermediate Predictions
| Input | Intermediate predictions | Final | ||
| Single Image | Normalized facial landmarks | Posed facial landmarks | Latent face-vid2vid keypoints | Animated output |
 |
||||
 |
||||
Emotion Control
We condition both the Speech2Landmark and Landmark2Latent models on the emotion using FiLM layers. At inference, we can provide the desired combination of emotion labels and their intensities as input.
| Input image | 0.5 Happy | 1.0 Happy |
 |
||
| Input image | 0.5 Angry | 1.0 Angry |
Eye Control — Blinking and Gaze
By manipulating the intermediate facial landmarks corresponding to the eyes, we can introduce eye blinking motion. As face-vid2vid allows control over the eye gaze, we are also able to control the gaze of the output.
| Input image | Blinking | Gaze change |
 |
||
 |
Citation
@inproceedings{gururani2023SPACE,
title={{SPACE: Speech-driven Portrait Animation with Controllable Expression}},
author={Gururani, Siddharth and Mallya, Arun and Wang, Ting-Chun and Valle, Rafael and Liu, Ming-Yu},
booktitle={IEEE/CVF International Conference on Computer Vision (ICCV)},
year={2023}
}