





VFC Caption Example
A happy little girl is standing in a green field, wearing a plaid shirt and holding onto a string of pink balloons. The balloons are floating in the air, creating a playful and joyful atmosphere. The girl appears to be enjoying the moment, with a smile on her face. In the background, there is a vast expanse of green grass, stretching out as far as the eye can see. The sky above is a bright blue, with a few white clouds scattered about. The overall mood of the scene is one of carefree happiness and joy, with the pink balloons adding a touch of whimsy and playfulness to the atmosphere.
Abstract
Existing automatic captioning methods for visual content face challenges such as lack of detail, content hallucination, and poor instruction following. In this work, we propose VisualFactChecker (VFC), a flexible training-free pipeline that generates high-fidelity and detailed captions for both 2D images and 3D objects. VFC consists of three steps: 1) proposal, where image-to-text captioning models propose multiple initial captions; 2) verification, where a large language model (LLM) utilizes tools such as object detection and VQA models to fact-check proposed captions; 3) captioning, where an LLM generates the final caption by summarizing caption proposals and the fact check verification results.
We conduct comprehensive captioning evaluations using four metrics: 1) CLIP-Score for image-text similarity; 2) CLIP-Image-Score for measuring image-image similarity; 3) human study on Amazon Mechanical Turk; 4) GPT-4V for fine-grained evaluation. Evaluation results show that VFC outperforms state-of-the-art open-sourced captioning methods for 2D images on the COCO dataset and 3D assets on the Objaverse dataset.
Approach
2D Image Captioning
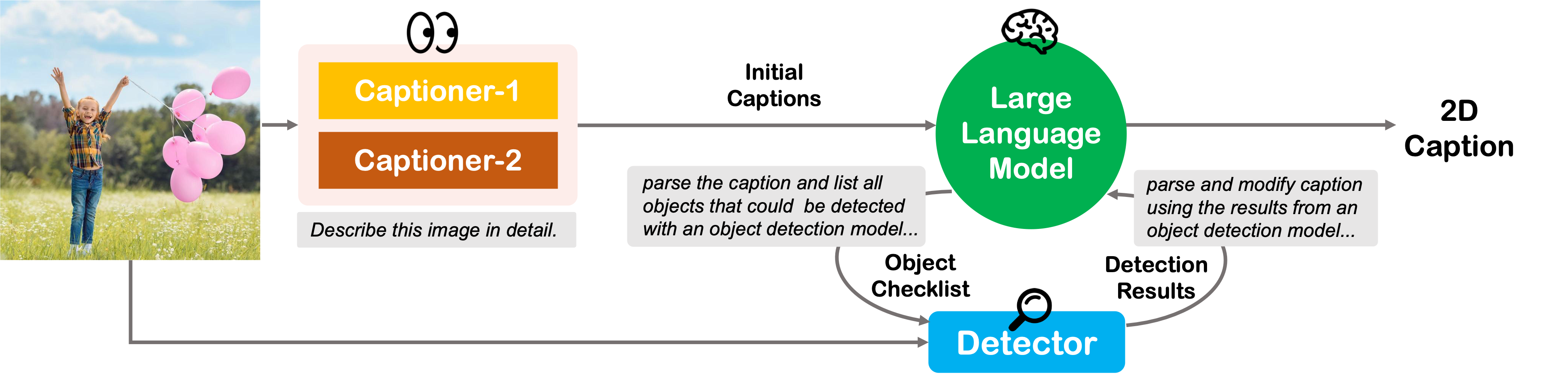
Pipeline of the VisualFactChecker for captioning 2D images. The process begins with the input being captioned by two multimodal captioning models (Captioner-1 and Captioner-2) to generate preliminary captions. These captions are then verified using a Large Language Model (LLM) to call object detection for fact-checking. Finally, the LLM incorporates all the results and summarizes the final caption by following instructions.
3D Object Captioning
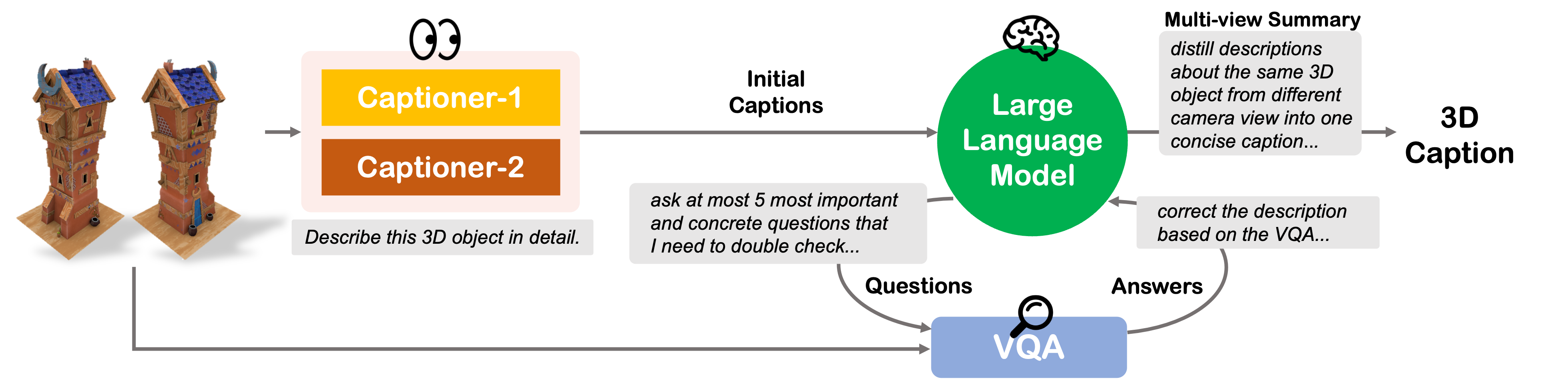
Pipeline of the VisualFactChecker for captioning 3D objects. For each individual view, the process begins with the input being captioned by two multimodal captioning models to generate preliminary captions. These captions are then verified using a LLM to call VQA models for fact-checking. Finally, the LLM synthesizes multiple perspectives into a singular, comprehensive caption for the entire 3D object.
Experiments
CLIP-score and CLIP-Image-Score
2D Image Captioning (COCO)
| Captioning Method | CLIP-Score (%) ↑ | CLIP-Image-Score (%) ↑ |
|---|---|---|
| Human Label (COCO GT) | 30.36 (-2.54) | 71.21 (-2.40) |
| BLIP2 | 30.11 (-2.79) | 70.79 (-2.82) |
| InstructBLIP | 31.45 (-1.45) | 72.95 (-0.66) |
| LLaVA-1.5 | 32.08 (-0.82) | 73.24 (-0.37) |
| Kosmos-2 | 32.32 (-0.58) | 73.28 (-0.33) |
| VisualFactChecker (Ours) | 32.90 | 73.61 |
3D Object Captioning (Objaverse)
| Captioning Method | CLIP-Score (%) ↑ | CLIP-Image-Score (%) ↑ |
|---|---|---|
| Cap3D | 33.44 (-0.57) | 79.88 (-0.44) |
| VisualFactChecker (Ours) | 34.01 | 80.32 |
Pairwise CLIP-score and CLIP-Image-Score

Human and GPT-4V Evaluation

Citation
@inproceedings{ge2024visual,
title={Visual Fact Checker: Enabling High-Fidelity Detailed Caption Generation},
author={Ge, Yunhao and Zeng, Xiaohui and Huffman, Jacob Samuel and Lin, Tsung-Yi and Liu, Ming-Yu and Cui, Yin},
booktitle={IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2024}
}