Pick-up from table
The humanoid approaches, grasps, and lifts everyday household objects from tabletop surfaces.
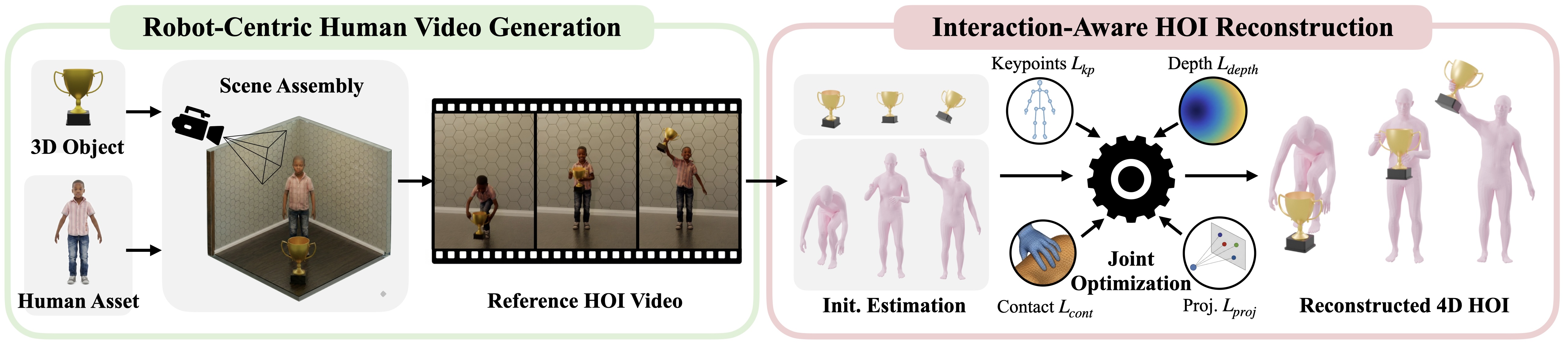
Scaling humanoid loco-manipulation requires robot-compatible demonstrations across diverse objects, whole-body motions, and scene geometries, but teleoperation and motion capture are difficult to scale because each collection depends on physical setups, instrumented actors, and robot operation. We present GRAIL, a digital generation pipeline that remains fully virtual until deployment: it composes 3D assets, simulator-ready scenes, and priors from video foundation models to synthesize interactions without rebuilding physical environments or teleoperating the robot.
Rather than reconstructing unconstrained in-the-wild videos, GRAIL starts from fully specified 3D configurations in which object geometry, camera parameters, metric scale, environment depth, and a robot-proportioned character are known before video generation and reused during reconstruction. We retarget the recovered motions to a humanoid robot and train complementary task-general trackers for manipulation and locomotion. GRAIL produces over 20,000 sequences spanning pick-up, whole-body manipulation, sitting, and terrain traversal, and transfers to real Unitree G1 deployment for object pick-up and stair-climbing.
GRAIL covers both object-centric interactions and scene-centric whole-body motion. The gallery below shows object manipulation and scene-aware locomotion as two complementary capability blocks.
Object-centric motions couple navigation, grasp geometry, and contact-rich whole-body control.
The humanoid approaches, grasps, and lifts everyday household objects from tabletop surfaces.
Ground-level pick-up requires squatting, reaching, grasping, and returning to a stable standing posture.
Larger and constrained objects require coordinated approach, grasp, carry, push, and repositioning motions.
Scene-centric motions stress body alignment, foot placement, and terrain-conditioned balance.
Chair interactions require approach, body alignment, and settling into a seated posture.
Curbs exercise adaptive stepping and balance recovery over raised platforms.
Slope traversal tests balance and gait adaptation over inclined terrain.
Staircases require precise foot placement, sustained balance, and scene-conditioned whole-body control.
We deploy policies trained with GRAIL-generated data on a real Unitree G1, covering egocentric RGB-based pick-up and stair-climbing as well as GR00T fine-tuning with a small teleoperation data mixture.
GRAIL renders egocentric RGB videos from generated grasping demonstrations, providing visual-policy training data before transferring the policy to real-world deployment.
We train egocentric RGB policies on GRAIL-generated data and deploy them on a Unitree G1 for real-world object pick-up and stair-climbing.
We also evaluate GRAIL as data for GR00T fine-tuning. Early co-training experiments use a 95% GRAIL and 5% teleoperation data mixture, improving grasping success over teleoperation-only training and reducing the chance that the policy gets stuck before reaching the target.
Given a 3D object asset, GRAIL produces humanoid loco-manipulation demonstrations comprising humanoid motion, object motion, and robot actions. The pipeline proceeds in three stages: it assembles a fully specified 3D configuration with a character prefitted to the target robot and synthesizes a reference human-object interaction video with a video foundation model; it reconstructs coherent metric 4D HOI trajectories using the known scene context; and it retargets the recovered motions to the Unitree G1 to train task-general tracking policies, followed by egocentric RGB policies for sim-to-real deployment.