LIBERO Simulation Benchmark Results
Cosmos Policy achieves state-of-the-art performance on the LIBERO simulation benchmark, with an average success rate of 98.5% across four task suites.
| Model | Spatial SR (%) |
Object SR (%) |
Goal SR (%) |
Long SR (%) |
Average SR (%) |
|---|---|---|---|---|---|
| Diffusion Policy | 78.3 | 92.5 | 68.3 | 50.5 | 72.4 |
| Dita | 97.4 | 94.8 | 93.2 | 83.6 | 92.3 |
| π0 | 96.8 | 98.8 | 95.8 | 85.2 | 94.2 |
| UVA | -- | -- | -- | 90.0 | -- |
| UniVLA | 96.5 | 96.8 | 95.6 | 92.0 | 95.2 |
| π0.5 | 98.8 | 98.2 | 98.0 | 92.4 | 96.9 |
| Video Policy | -- | -- | -- | 94.0 | -- |
| OpenVLA-OFT | 97.6 | 98.4 | 97.9 | 94.5 | 97.1 |
| CogVLA | 98.6 | 98.8 | 96.6 | 95.4 | 97.4 |
| Cosmos Policy (ours) | 98.1 | 100.0 | 98.2 | 97.6 | 98.5 |
RoboCasa Simulation Benchmark Results
Cosmos Policy also achieves state-of-the-art performance in the RoboCasa simulation benchmark (24 Kitchen manipulation tasks), achieving an average success rate of 67.1% while requiring significantly fewer training demonstrations than prior SOTA methods (50 demos versus 300).
| Model | # Training Demos per Task | Average SR (%) |
|---|---|---|
| GR00T-N1 | 300 | 49.6 |
| UVA | 50 | 50.0 |
| DP-VLA | 3000 | 57.3 |
| GR00T-N1 + DreamGen | 300 (+ 10000 synthetic) | 57.6 |
| GR00T-N1 + DUST | 300 | 58.5 |
| UWM | 1000 | 60.8 |
| π0 | 300 | 62.5 |
| GR00T-N1.5 | 300 | 64.1 |
| Video Policy | 300 | 66.0 |
| FLARE | 300 | 66.4 |
| GR00T-N1.5 + HAMLET | 300 | 66.4 |
| Cosmos Policy (ours) | 50 | 67.1 |
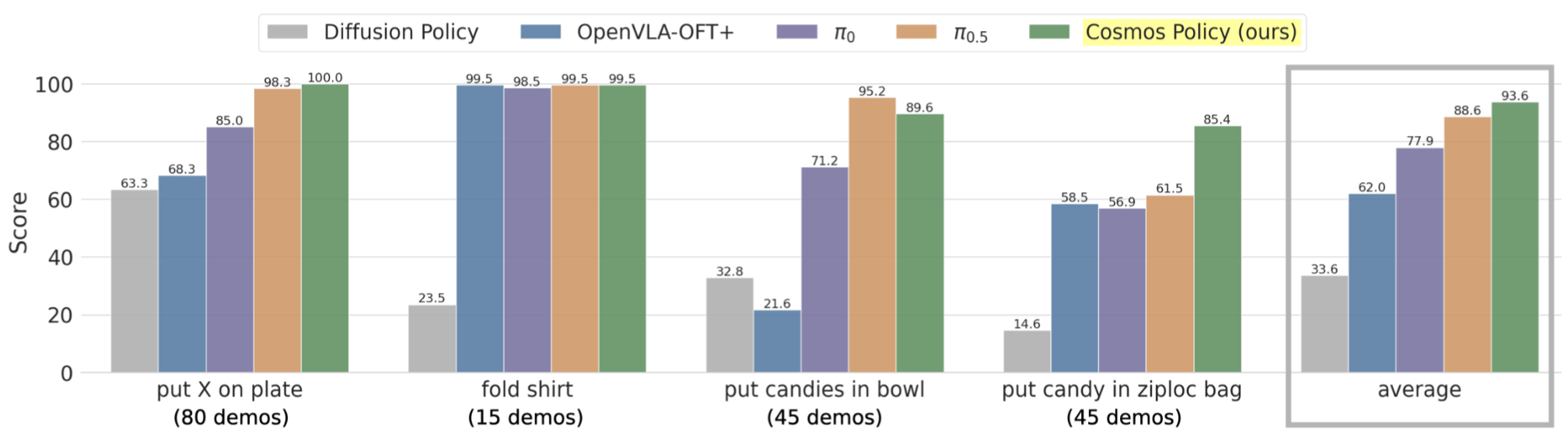
Real-World ALOHA Robot Results
Further, Cosmos Policy outperforms state-of-the-art methods in real-world ALOHA robot manipulation tasks, including fine-tuned vision-language-action models (VLAs).
Sample Rollouts & Future Image Predictions
Below we show sample rollout videos with Cosmos Policy, along with its future image predictions. For LIBERO and ALOHA, the prediction and execution horizon are equal (i.e., we predict an action chunk and execute it fully before generating the next one); for RoboCasa, the execution horizon is half the prediction horizon (i.e., we execute the first half of each action chunk).
LIBERO
RoboCasa
ALOHA
Citation
Please use the following BibTeX to cite our work:
@article{kim2025cosmospolicy,
title={Cosmos Policy: Fine-Tuning Video Models for Visuomotor Control and Planning},
author={Kim, Moo Jin and Gao, Yihuai and Lin, Tsung-Yi and Lin, Yen-Chen and Ge, Yunhao and Lam, Grace and Liang, Percy and Song, Shuran and Liu, Ming-Yu and Finn, Chelsea and Gu, Jinwei},
journal={arXiv preprint arXiv:2601.16163},
year={2025},
url={https://arxiv.org/abs/2601.16163}
}