We introduce Cosmos-Predict2.5, the latest version of the Cosmos World Foundation Models (WFMs)
family, specialized for simulating and predicting the future state of the world in the form of video.
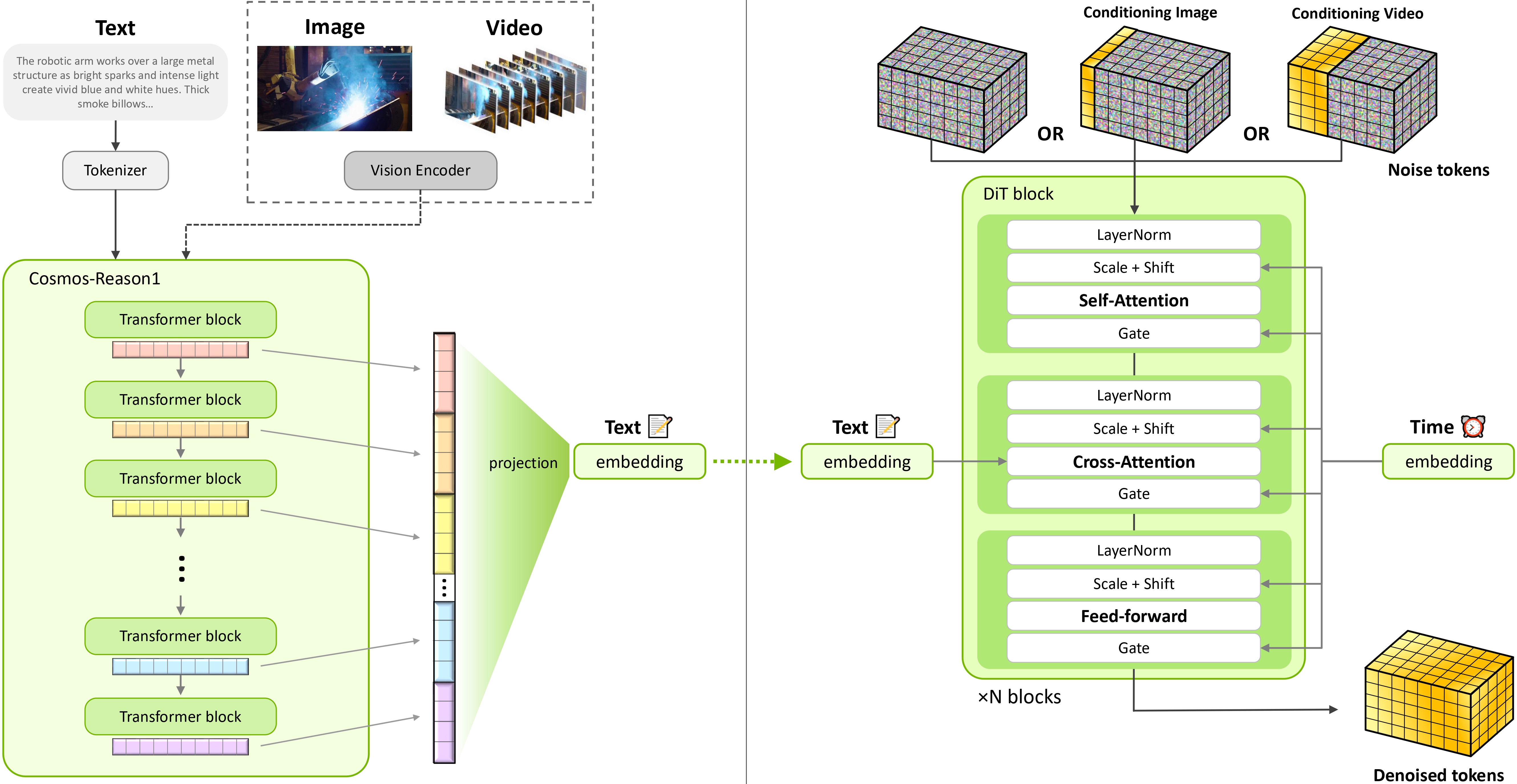
Cosmos-Predict2.5 is a flow based model that unifies Text2World, Image2World, and Video2World into a
single model and utilizes Cosmos-Reason1, a Physical AI reasoning vision language model (VLM), as
the text encoder.
With an improved data pipeline, we curated 200 million high-quality pre-training
video clips and post-training data covering various physical AI domains. We further leverage model merging and a
new reinforcement learning algorithm to post-train Cosmos-Predict2.5 for model quality
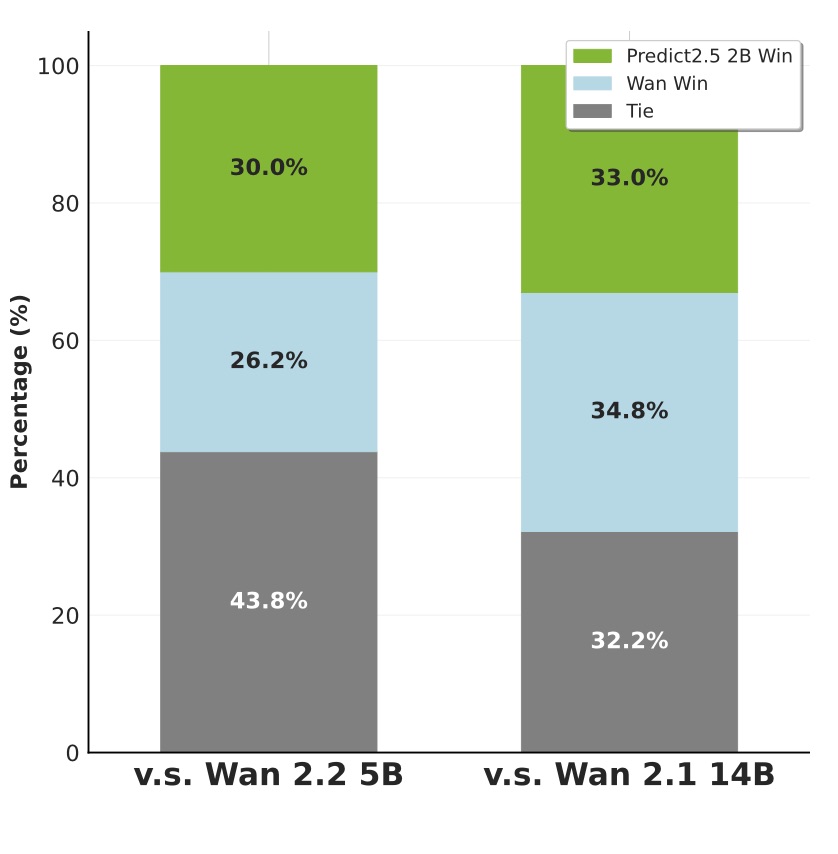
boost. Experimental results on various benchmark datasets show Cosmos-Predict2.5 significantly
improves upon Cosmos-Predict1 in both quality and prompt alignment. Cosmos-Predict2.5 comes
with
two model sizes: 2B and 14B. We show how they can be used for various robotics and autonomous
vehicle tasks through post-training. We further extend Cosmos-Predict2.5 into a broader family with
Cosmos-Transfer2.5
control-net models for various sim2real and real2real applications. To facilitate the
development of world models for Physical AI, we make our code, model weights, and benchmarks available under the
NVIDIA Open Model License at Cosmos-Predict2.5 and Cosmos-Transfer2.5.