Efficient AI
Efficient AI
News
Publications
Light
Dark
Automatic
Quantization
Pushing Intelligence to 4-bit
Four-bit floating point is moving from a storage-only compression trick to a primitive for training and inference across LLMs, diffusion, video generation, KV cache, and attention.
Wei Huang
,
Yukang Chen
,
Weian Mao
,
Luozhou Wang
,
Shuai Yang
,
Song Han
Jun 16, 2026
Pushing Intelligence to 4-bit
Four-bit floating point is moving from a storage-only compression trick to a primitive for training and inference across LLMs, diffusion, video generation, KV cache, and attention.
Wei Huang
,
Yukang Chen
,
Weian Mao
,
Luozhou Wang
,
Shuai Yang
,
Song Han
Jun 16, 2026
1 min read
SVDQuant: Absorbing Outliers by Low-Rank Components for 4-Bit Diffusion Models
Diffusion models have been proven highly effective at generating high-quality images. However, as these models grow larger, they …
Muyang Li
,
Yujun Lin
,
Zhekai Zhang
,
Tianle Cai
,
Xiuyu Li
,
Junxian Guo
,
Enze Xie
,
Chenlin Meng
,
Jun-Yan Zhu
,
Song Han
PDF
Cite
Code
Project
Video
Demo
Blog
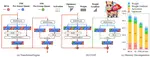
COAT: Compressing Optimizer states and Activation for Memory-Efficient FP8 Training
FP8 training has emerged as a promising method for improving training efficiency. Existing frameworks accelerate training by applying …
Haocheng Xi
,
Han Cai
,
Ligeng Zhu
,
Yao (Jason) Lu
,
Kurt Keutzer
,
Jianfei Chen
,
Song Han
PDF
Cite
Code
Project
Demo
Cite
×