Abstract
Learning generative models of 3D point clouds is one of the fundamental problems in 3D generative learning. One of the key properties of point clouds is their permutation invariance, i.e., changing the order of points in a point cloud does not
change the shape they represent. In this paper, we analyze the recently proposed equivariant OT flows that learn permutation invariant generative models for point-based molecular data and we show that these models scale poorly on large point
clouds. Also, we observe learning (equivariant) OT flows is generally challenging since straightening flow trajectories makes the learned flow model complex at the beginning of the trajectory. To remedy these, we propose not-so-optimal
transport flow models that obtain an approximate OT by an offline OT precomputation, enabling an efficient construction of OT pairs for training. During training, we can additionally construct a hybrid coupling by combining our approximate
OT and independent coupling to make the target flow models easier to learn. In an extensive empirical study, we show that our proposed model outperforms prior diffusion- and flow-based approaches on a wide range of unconditional generation
and shape completion on the ShapeNet benchmark.
Method Overview
Generating 3D point clouds is one of the fundamental problems in 3D modeling with applications in shape generation, 3D reconstruction, 3D design, and perception. However existing generative approaches overlook 3D point cloud permutation invariance, implying the rearrangement of points does not change the shape that they represent. In closely related areas, equivariant optimal transport (OT) flows have been recently developed for 3D molecules that can be considered as sets of 3D atom coordinates. These frameworks learn permutation invariant generative models, i.e., all permutations of the set have the same likelihood under the learned generative distribution. They are trained using optimal transport between data and noise samples, yielding several key advantages including low sampling trajectory curvatures, low-variance training objectives, and fast sample generation. Albeit these theoretical advantages, our examination of these techniques for 3D point cloud generation reveals that they scale poorly for point cloud generation. This is mainly due to the fact that point clouds in practice consist of thousands of points whereas molecules are assumed to have tens of atoms in previous studies. Solving the sample-level OT mapping between a batch of training point clouds and noise samples is computationally expensive. Conversely, ignoring permutation invariance when solving batch-level OT fails to produce high-quality OT due to the excessive possible permutations of point clouds.
In this paper, we propose a simple and scalable generative model for 3D point cloud generation using flow matching, coined as not-so-optimal transport flow matching, as shown in Figure below. We first propose an efficient way to obtain an approximate OT between point cloud and noise samples. Instead of searching for an optimal permutation between point cloud and noise samples online during training, which is computationally expensive, we show that we can precompute an OT between a dense point superset and a dense noise superset offline. Since subsampling a superset preserves the underlying shape, we can simply subsample the point superset and obtain corresponding noise from the precomputed OT to construct a batch of noise-data pairs for training the flow models.
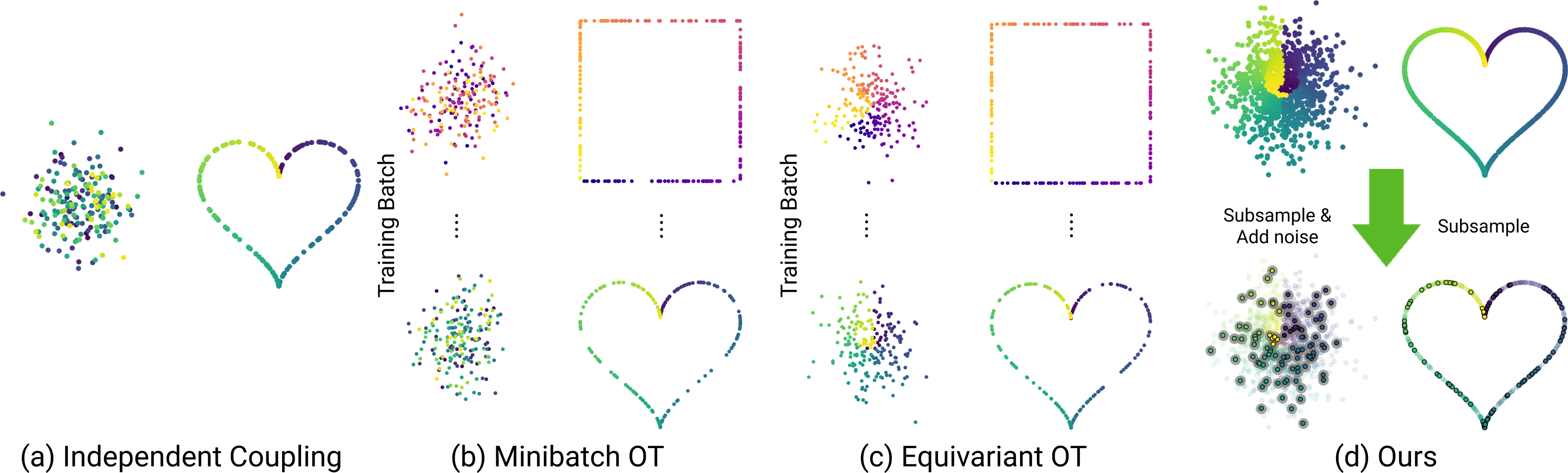
Different coupling types between Gaussian noise (left) and point clouds (right), where coupled noise and surface points share the same color: (a) Independent Coupling randomly maps
noises to point clouds. (b) Minibatch OT computes OT map in batches of noises and point clouds.
(c) Equivariant OT follows the similar minibatch OT but aligns points via permutation. (d) Our
approach precomputes dense OT on data and noise supersets, then subsamples it to couple point
clouds with slightly perturbed noise. Note that only (c) and (d) can produce high-quality OT.
OT Approximation Method Comparisons.
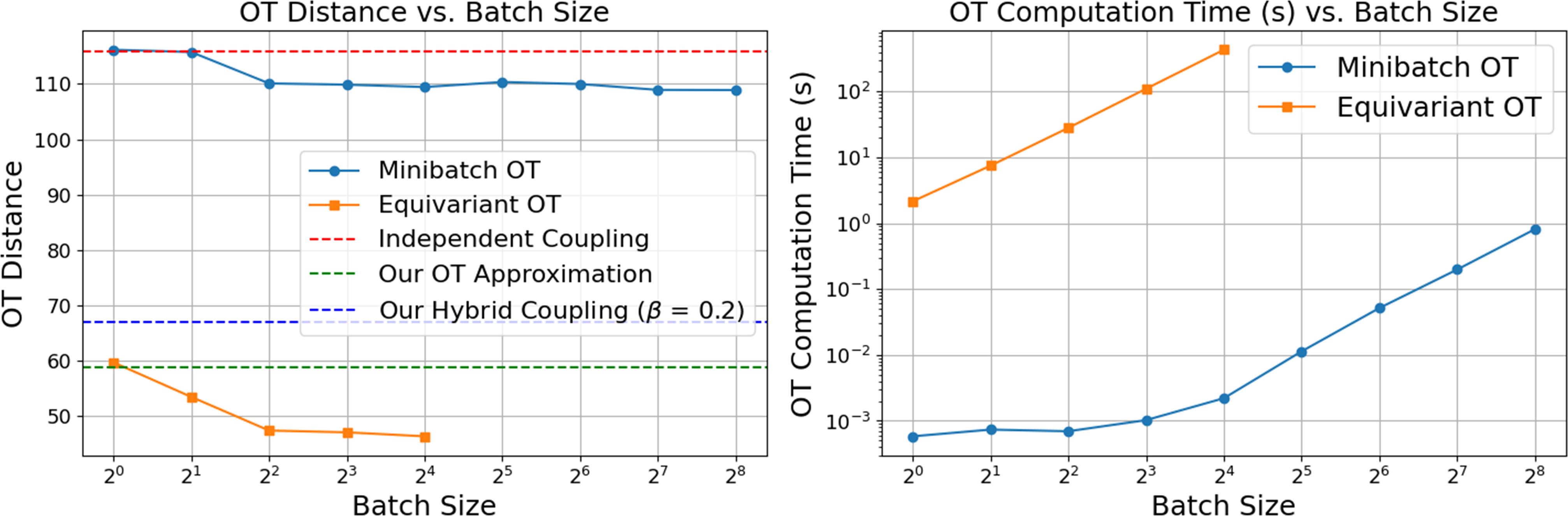
Below, we examine the minibatch OT and equivariant OT against our approach in terms of optimal transport cost minimization (left) and their computational cost (right). The minibatch OT minimizes the OT cost by shuffling examples in each batch. The equivariant OT does the same while permuting points in point clouds and aligning them with noise when minimizing the OT cost. As expected, the minibatch OT is faster (right) but has a hard time reducing the OT cost (left) compared to the equivariant OT. Our offline OT computation and its hybrid variant achieve a similar OT cost to that of equivariant OT, and they are run once before training.
Left: Average OT distance across batch sizes. Minibatch OT (blue) fails to reduce distances much compared to independent coupling (red
dash). Equivariant OT (orange) significantly reduces distance values. Our OT approximation is on
par with Equivariant OT. Right: Computational time for OT across batch sizes. Minibatch OT (blue)
maintains a reasonable computational time (∼1 second) with batch size B = 256. Equivariant OT
(orange) grows quadratically starting from 2.2 seconds with B = 1.
Difficulty of Training OT Flows
Though training flows with OT couplings comes with appealing theoretical justifications (e.g., straight sampling trajectories), we identify a key training challenge with them that is often overlooked in the OT flows literature. Our experiments indicate that flows trained with equivariant OT maps are often outperformed by those with independent coupling in terms of sample quality. We hypothesize this is due to the increasing complexity of target vector fields for OT couplings that makes their approximation harder with neural networks.
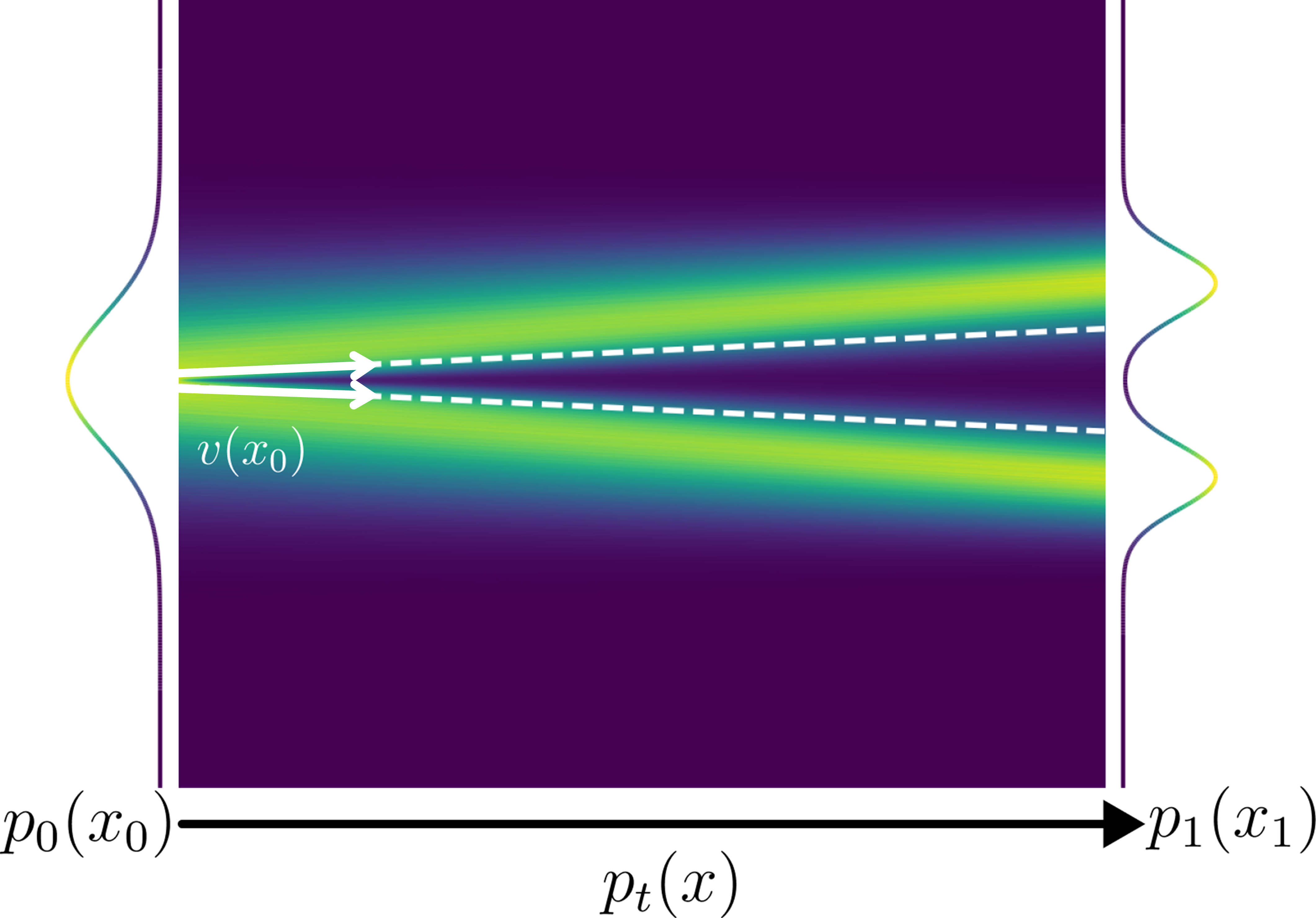
Intuitively, as we make target sampling trajectories straighter using more accurate OT couplings, the complexity of generation shifts toward smaller time steps. As we show below, in the limit of straight trajectories, the learned vector field should be able to switch between different target point clouds with a small variation in x0, forcing the vector field to be complex at t=0 (i.e., high Lipchitz). This problem is further exacerbated in the equivariant OT flows with a large number of points where permuting Gaussian noise cloud in the input makes it virtually the same for all target point clouds.
In the paper, we empirically verify the complexity of the learned vector fields by measuring their Jacobian Frobenius norm. We observe that the Jacobian norm is indeed high near t=0 for OT flows, confirming our hypothesis. To remedy this, we propose a simple solution termed as hybrid coupling where we mix OT couplings with independently generated noise. Please refer to the paper for additional information.
In the OT flow model, the vector field v admits a large change in its output with a small perturbation of x0 at t=0.
Unconditional Generation Results
Training Paradigm Comparisons
For unconditional generation, we first evaluate our framework against alternative training paradigms, including diffusion models and flow matching models with different couplings
Our OT flows are on par with or better than existing diffusion and flow models at large sampling steps and are significantly better when the number of inference steps is small (5-10 steps).
Quantitative Comparisons:
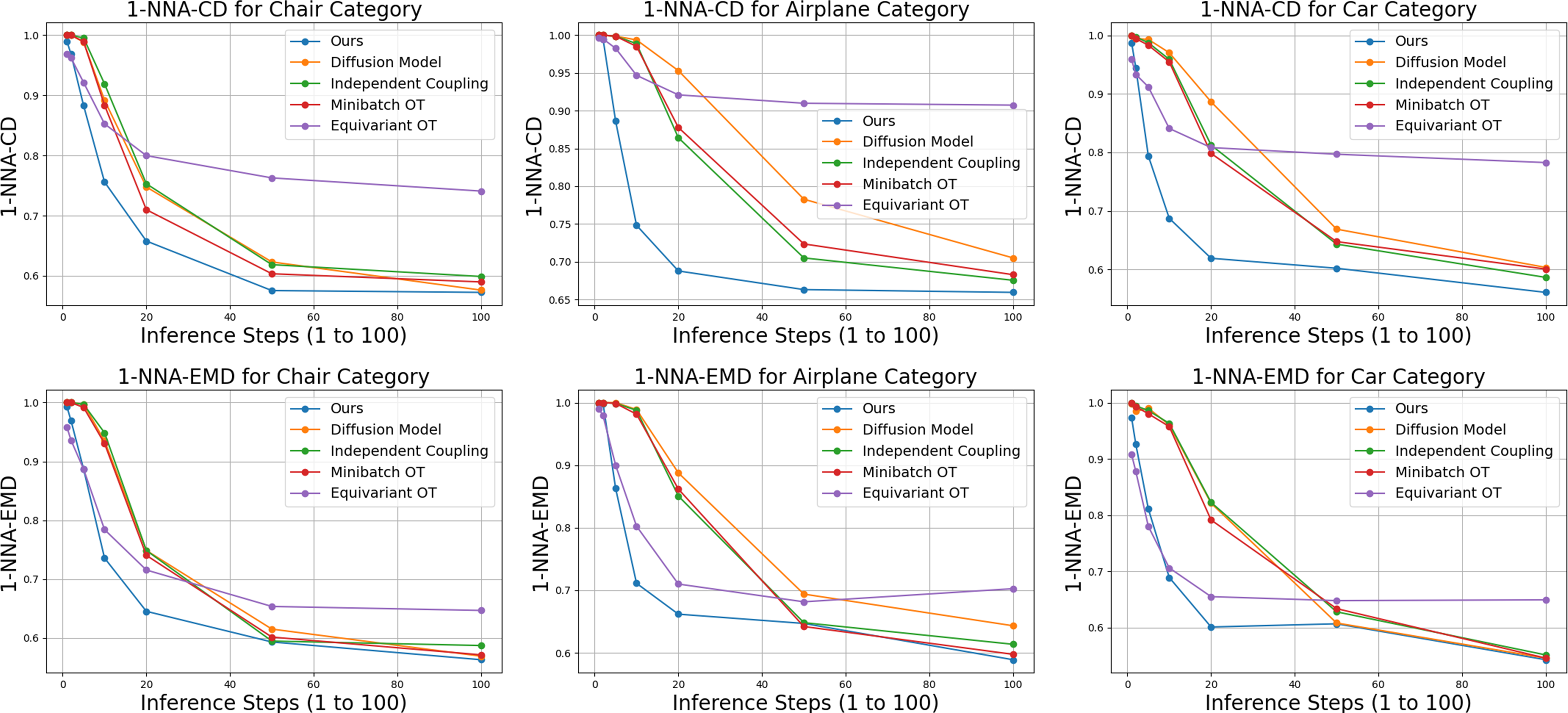
Quantitative comparisons of generation quality for different training paradigms using
1-NNA-CD (top) and 1-NNA-EMD (bottom) for Chair (left), Airplane (middle), and Car (right).
We present evaluation metrics across various inference steps, i.e., from 1 steps to 100 steps, for five
methods: (i) ours, (ii) diffusion model with v-prediction (Salimans & Ho, 2022), and three flow
matching models with different coupling methods: (iii) independent coupling (Lipman et al., 2022),
(iv) Minibatch OT (Tong et al., 2023; Pooladian et al., 2023), and (v) Equivariant OT (Song et al.,
2024; Klein et al., 2024). Note that values closer to 50% indicate better performance.
Quantitative Comparisons:
Qualitative comparisons of different training paradigms for Chair (top) and Airplane (bottom)
categories. We present inference results with 10 steps (left) and 100 steps (right).
Baseline Comparisons
In addition, we also compare our approach with other point cloud generation methods that require multi-steps generation, showing our approach
can achieve significantly better generation quality when the inference is reduced to around 10-20 steps, without relying on
additional expensive straightening procedures, e.g., rectified flow.
Quantitative Comparisons:
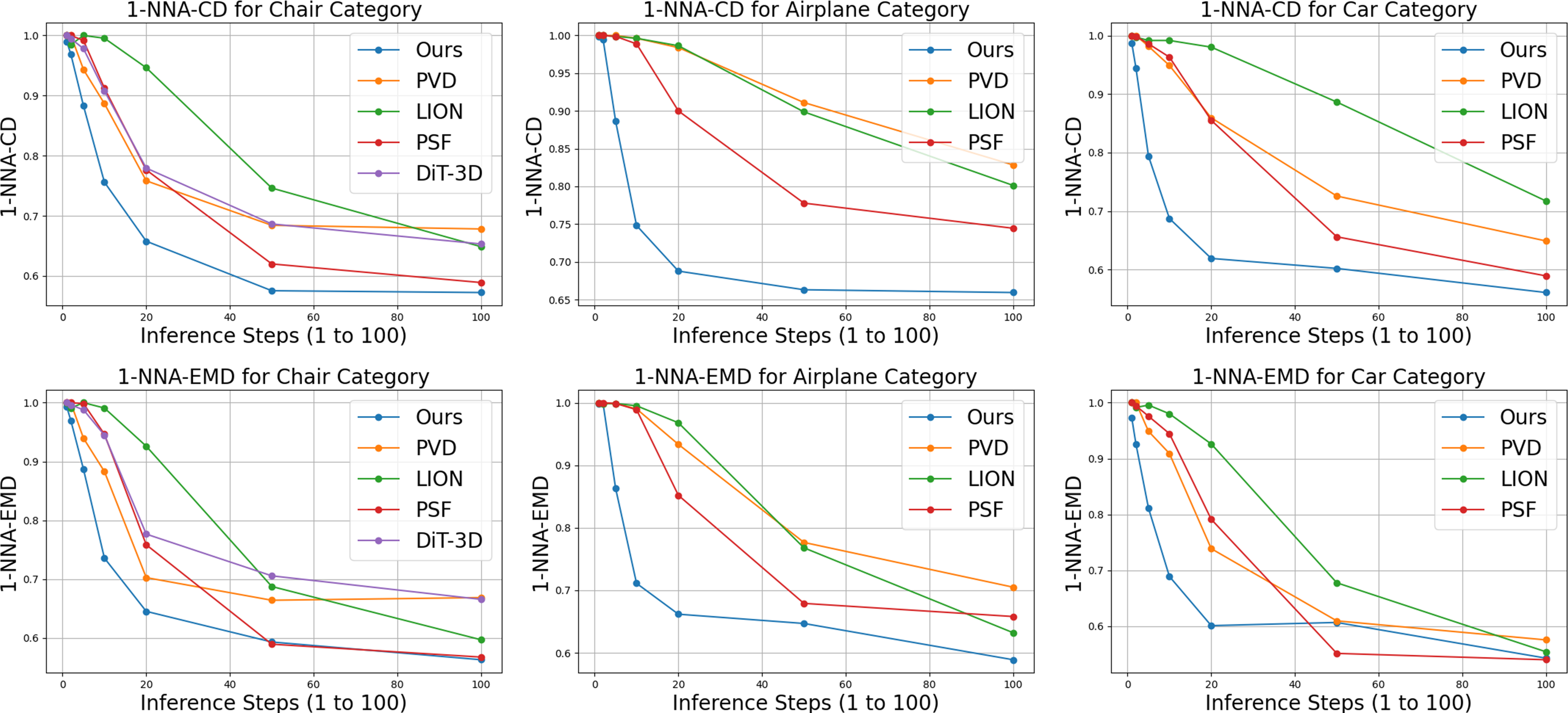
Quantitative comparisons with other point cloud generation methods using 1-NNA-CD
(top) and 1-NNA-EMD metrics (bottom) for Chair (left), Airplane (middle), and Car (right). We
present evaluation metrics across various inference steps, i.e., from 1 step to 100 steps, for five
methods: (i) ours, (ii) PVD (Zhou et al., 2021), (iii) LION (Zeng et al., 2022), (iv) PSF (Wu et al.,
2023) without rectified flow, and (v) DiT-3D (Mo et al., 2023).
Quantitative Comparisons:
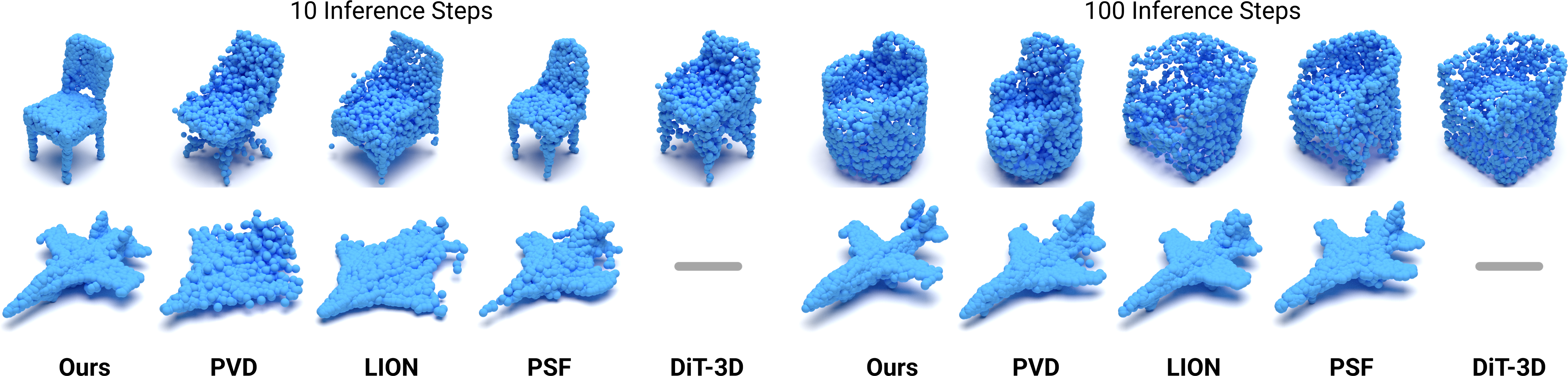
Qualitative comparisons of different training paradigms for Chair (top) and Airplane (bottom)
categories. We present inference results with 10 steps (left) and 100 steps (right).
Shape Completion Results
We also evaluate the proposed training paradigms for a conditional generation task, i.e., shape completion. Our approach produces a reasonable-looking shape with only five inference
steps, while other methods still generate noisy shapes. Furthermore, Minibatch OT generates a shape
that does not correspond to the input due to violating the training assumption. Equivariant OT fails
to produce shapes of similar visual quality even with increased inference steps
Comparisons with other training paradigms on the shape completion task. Left: Quantitative comparisons with other alternatives using different inference steps. Right: Qualitative comparisons with other methods show the completion generated by 2, 5, and 100 steps, respectively.
BibTex:
@article{hui2025NotSoOT,
title={Not-So-Optimal Transport Flows for 3D Point Cloud Generation},
author={Ka-Hei Hui and Chao Liu and Xiaohui Zeng and Chi-Wing Fu and Arash Vahdat},
booktitle={International Conference on Learning Representations (ICLR)},
year={2025},
}