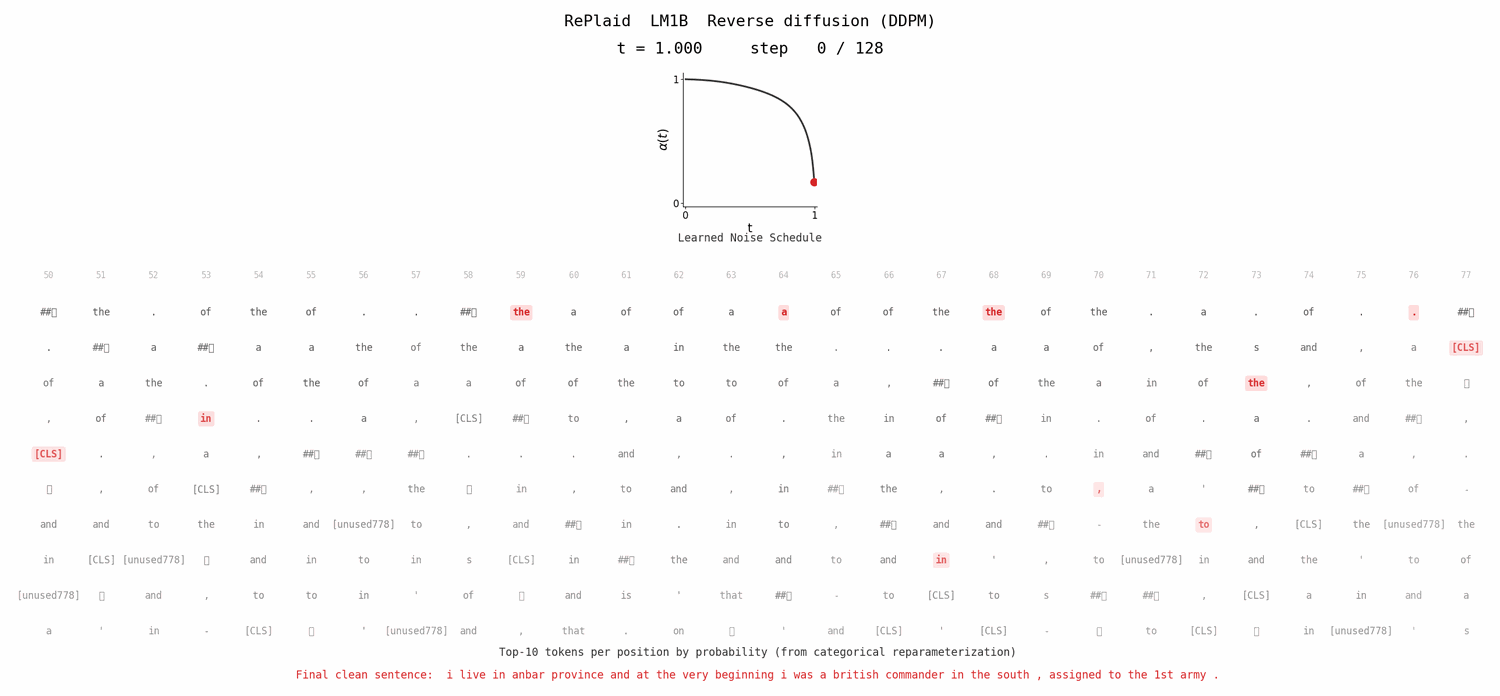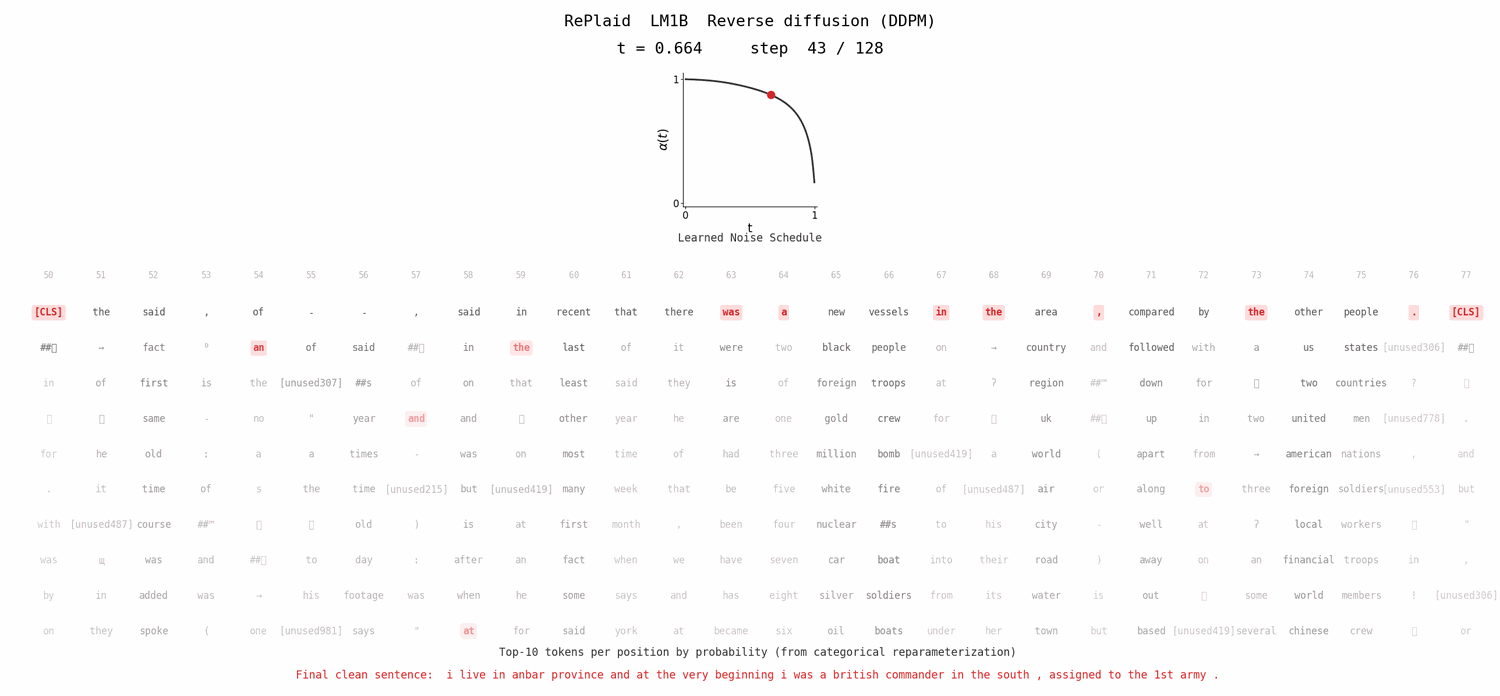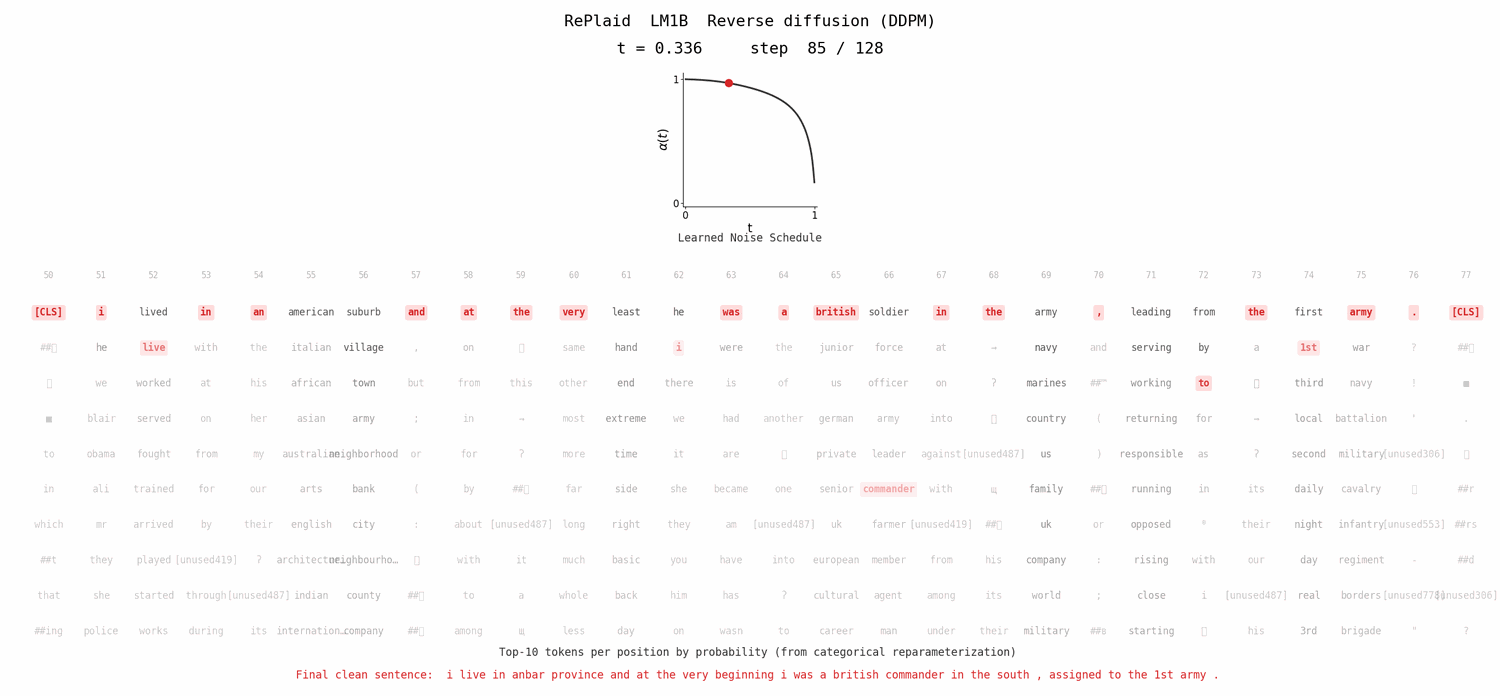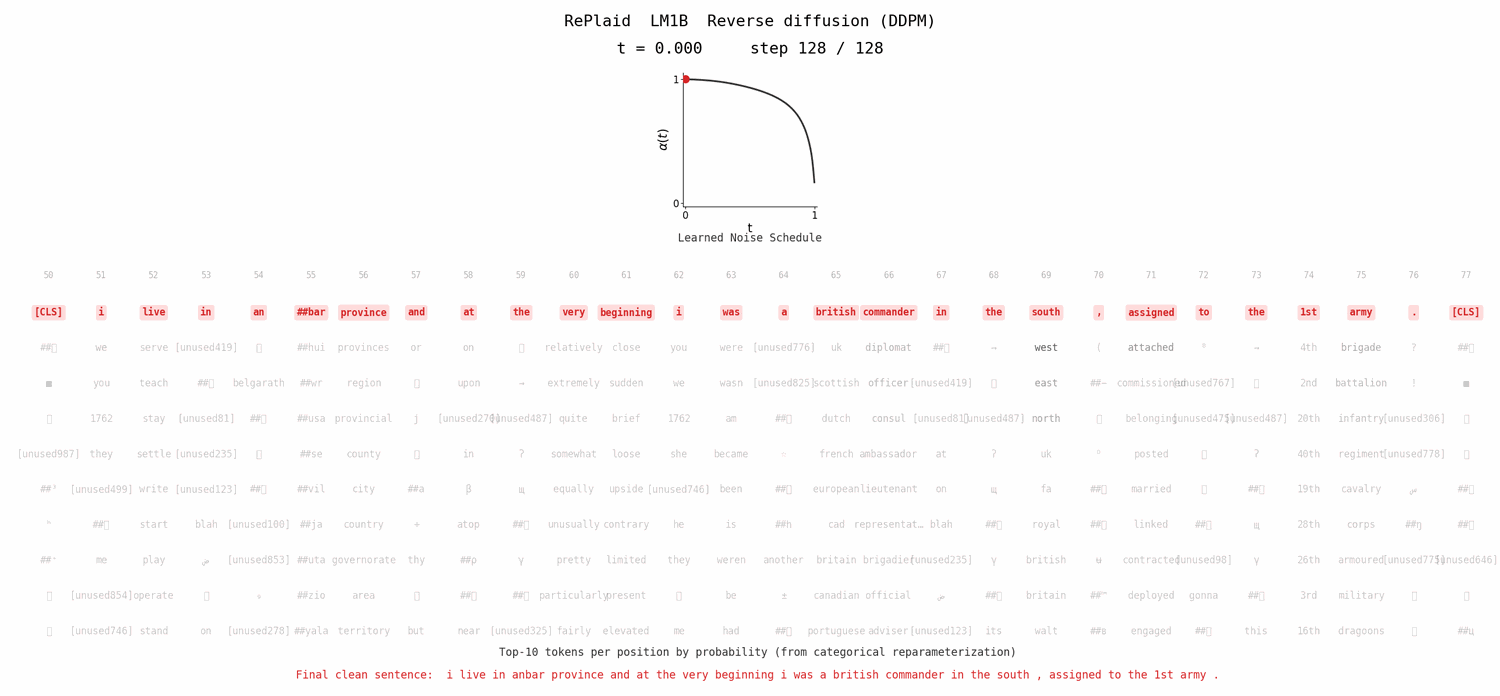
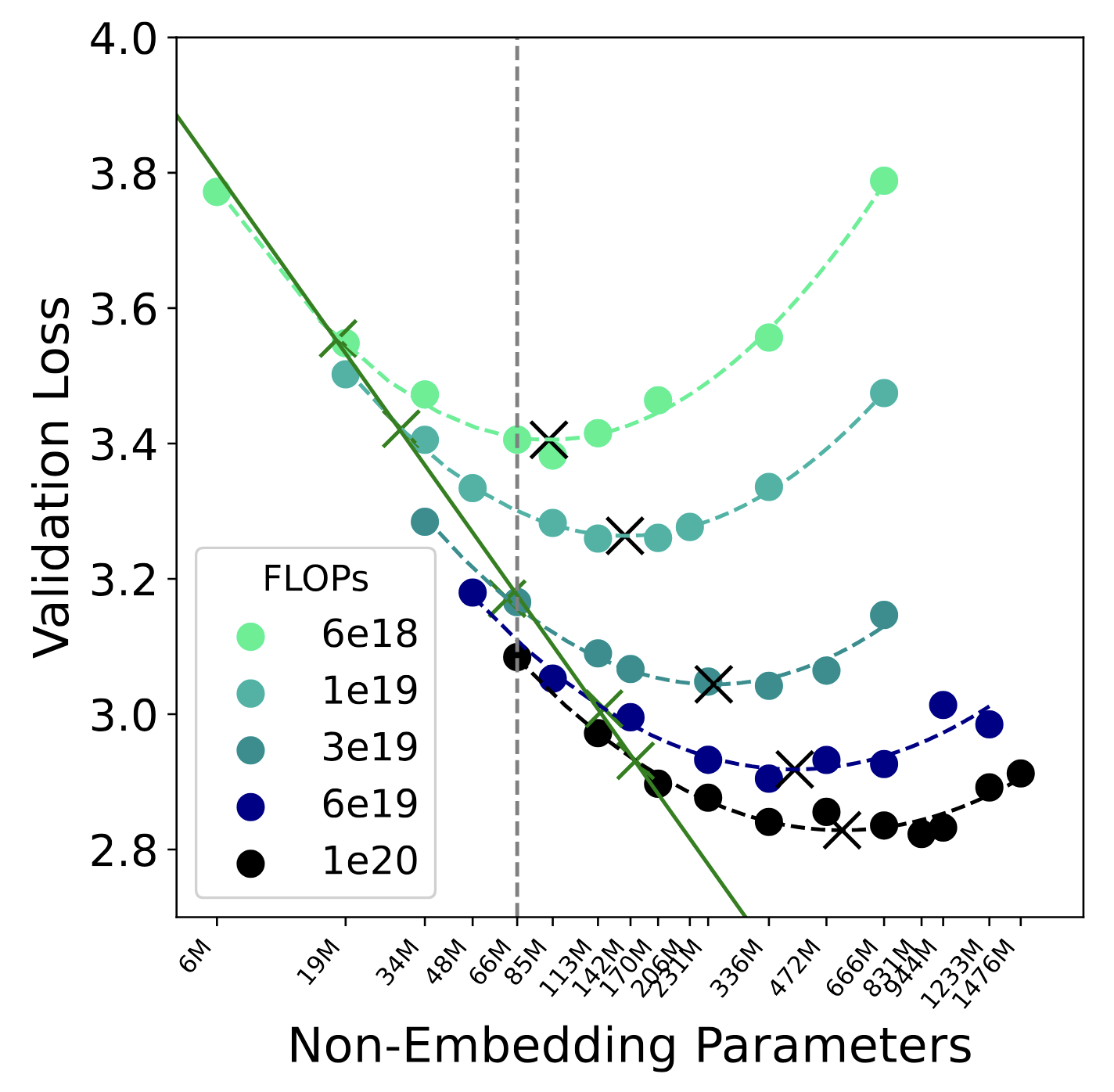
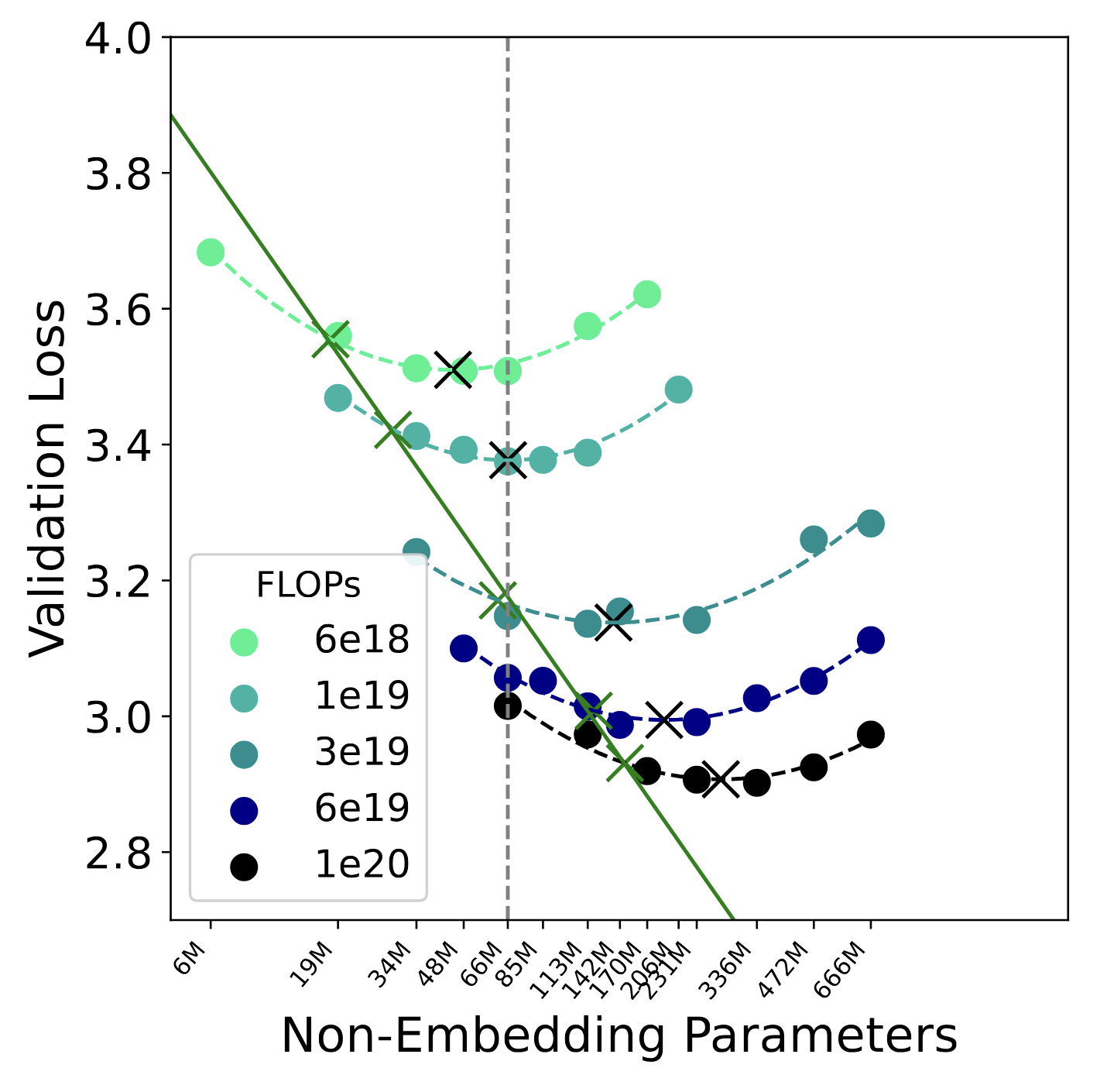
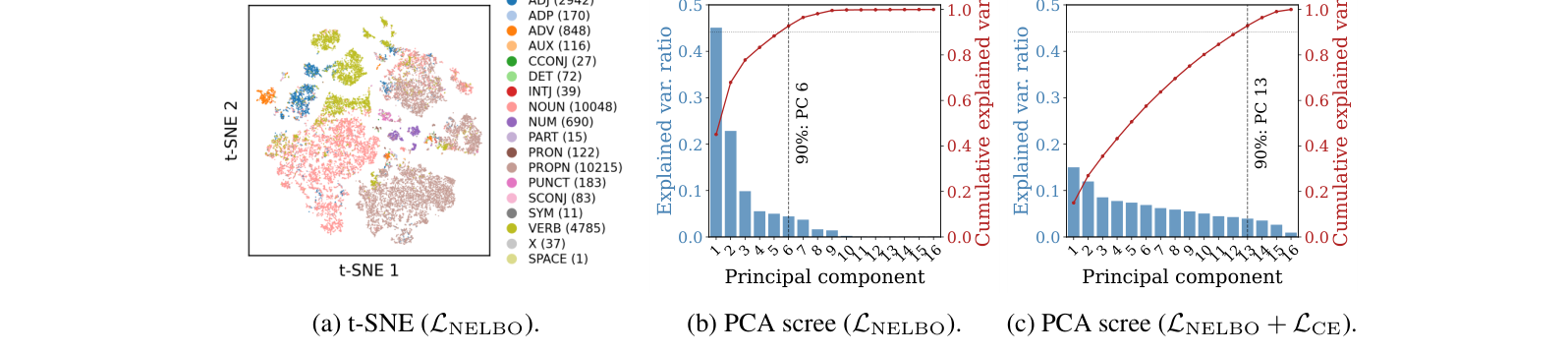
Likelihood Evaluation
Beyond the scaling-law study, we benchmark RePlaid at the 0.1B (100M) parameter scale — the
canonical testbed at which the recent wave of continuous DLMs is exclusively evaluated, making it the
natural setting for a head-to-head comparison. Having established that RePlaid scales on par with
discrete DLMs, we compare at this standard scale against the strongest discrete (MDLM, Duo) and
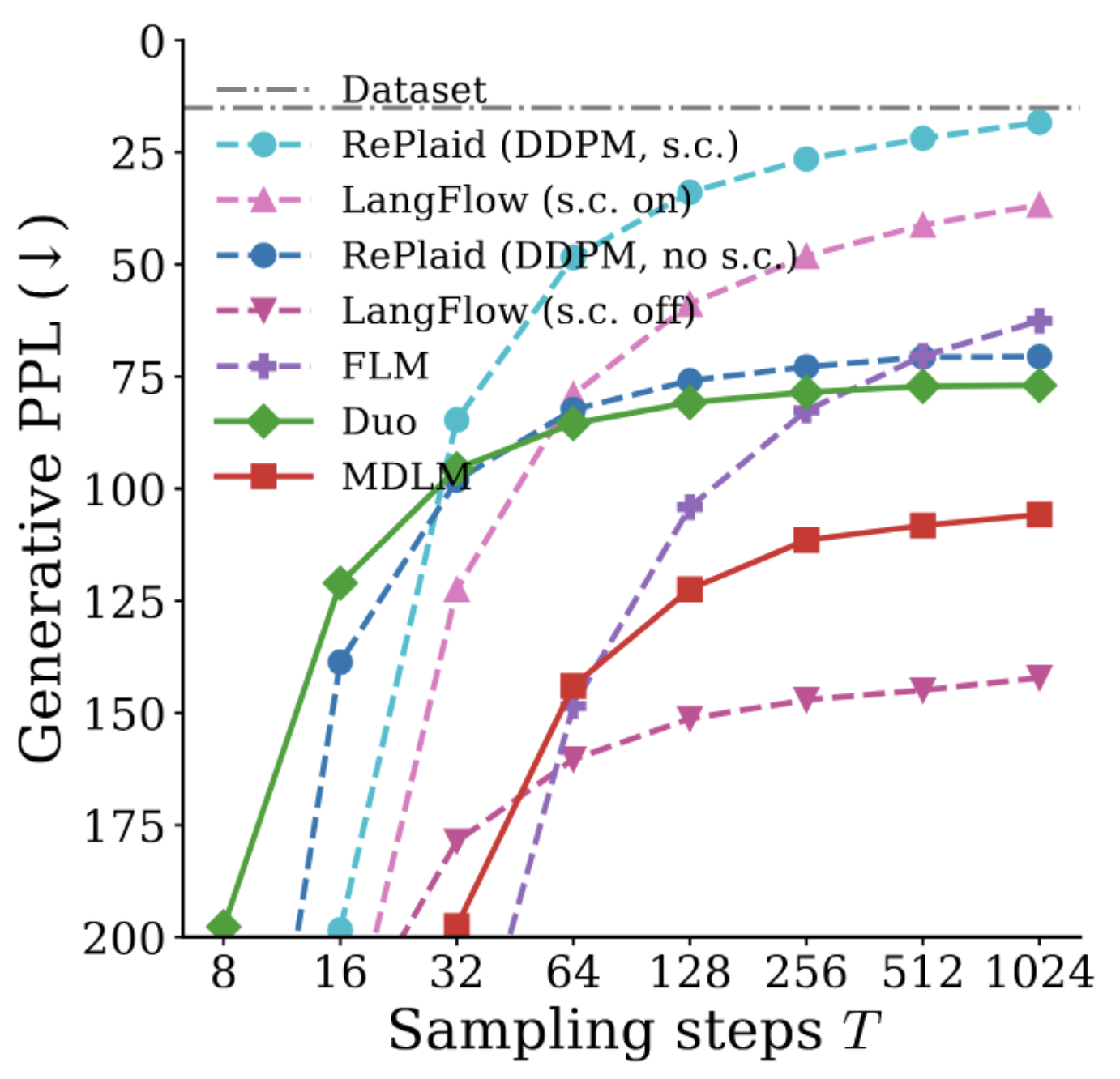
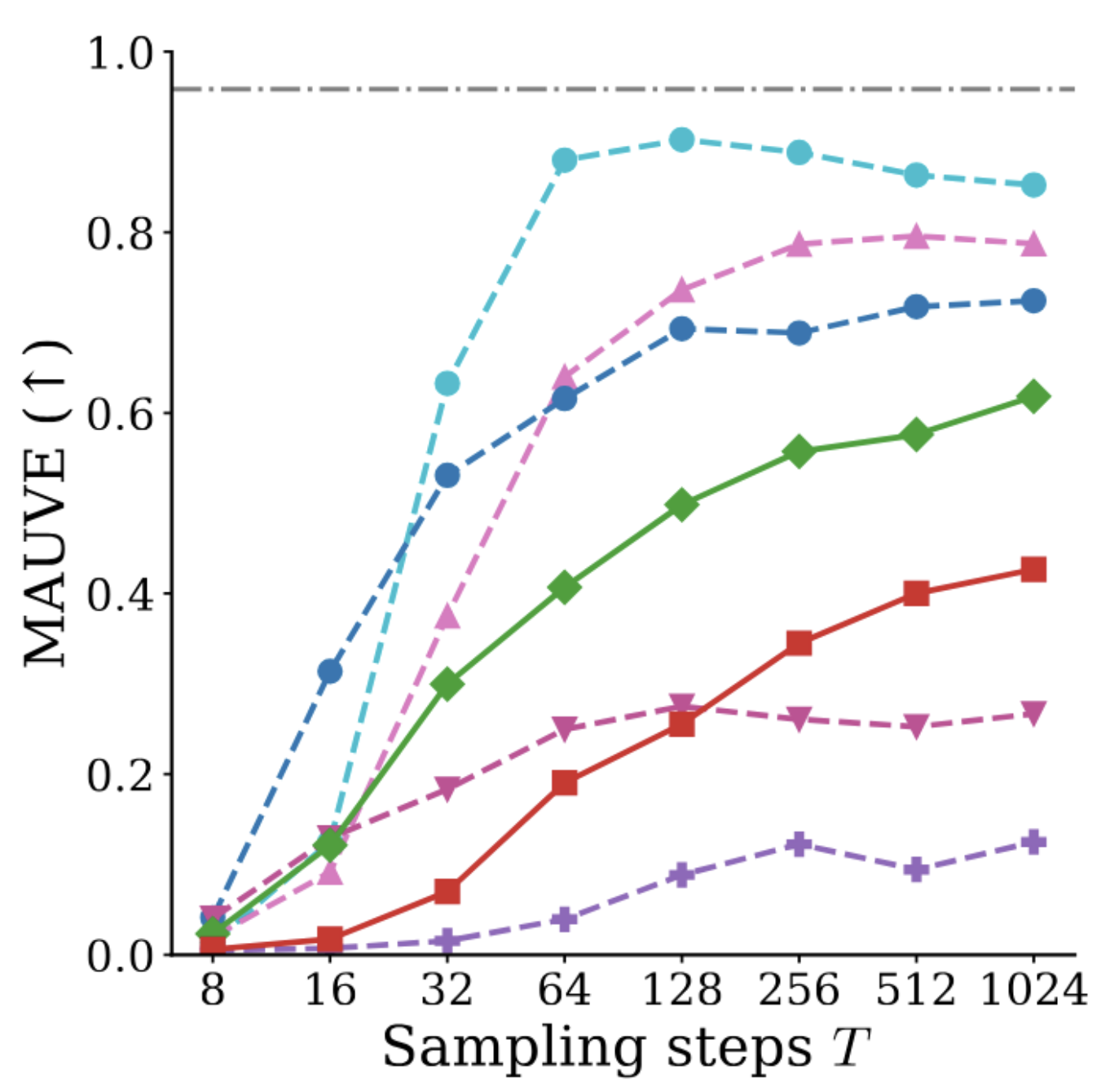
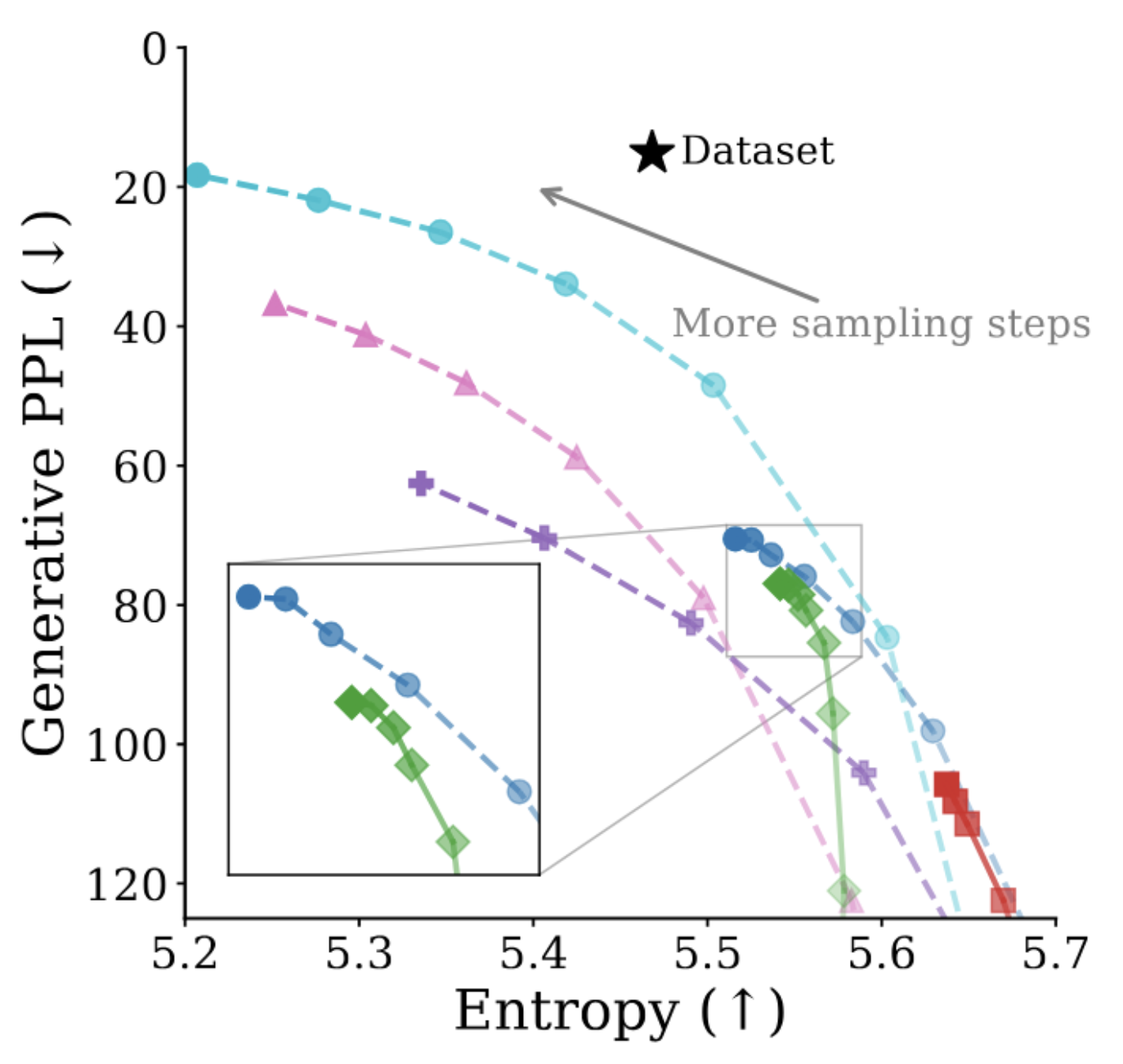
continuous (FLM, LangFlow) baselines along both likelihood and sample quality. Both axes matter: methods like
FLM does not propose likelihood bounds, and prior work has shown that a better likelihood does
not always translate into better sample quality. Every method shares the same transformer architecture
and a comparable optimization setup, trained for 1M steps on OpenWebText.
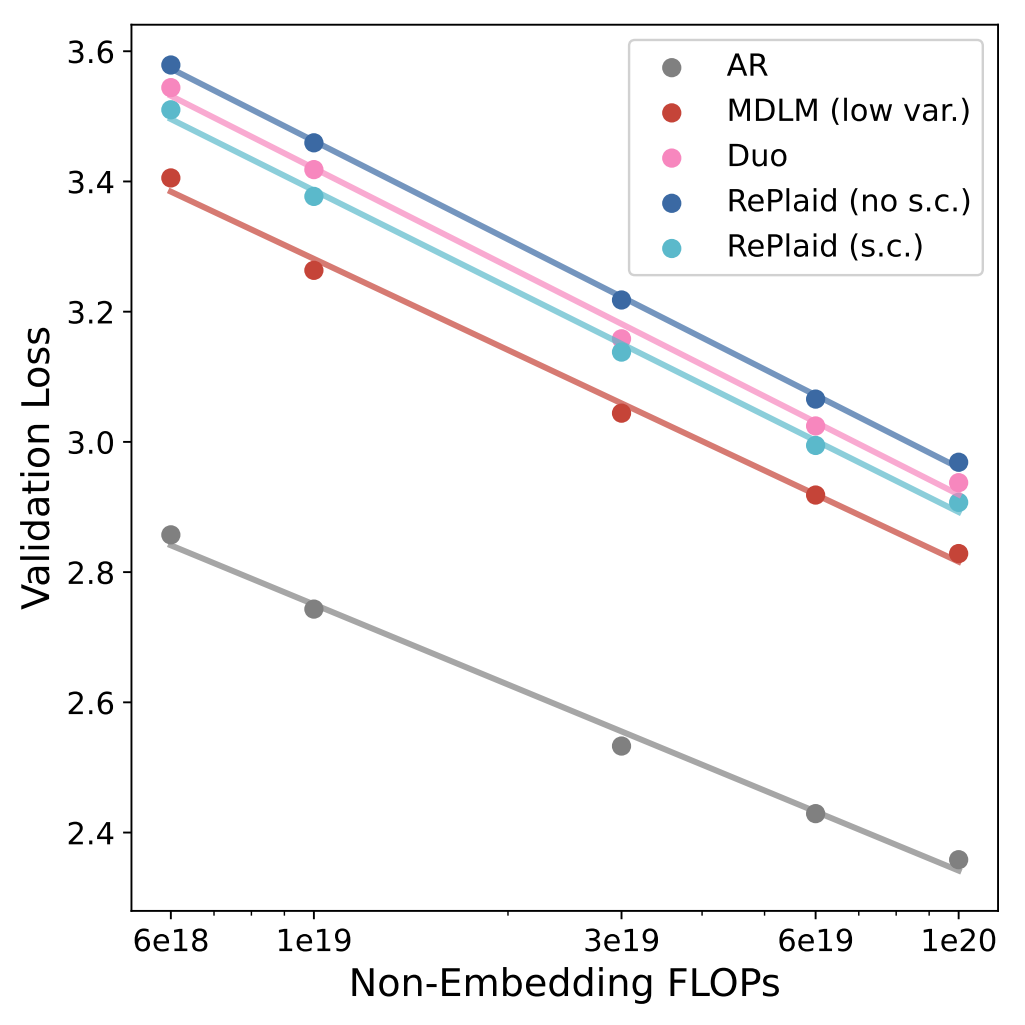
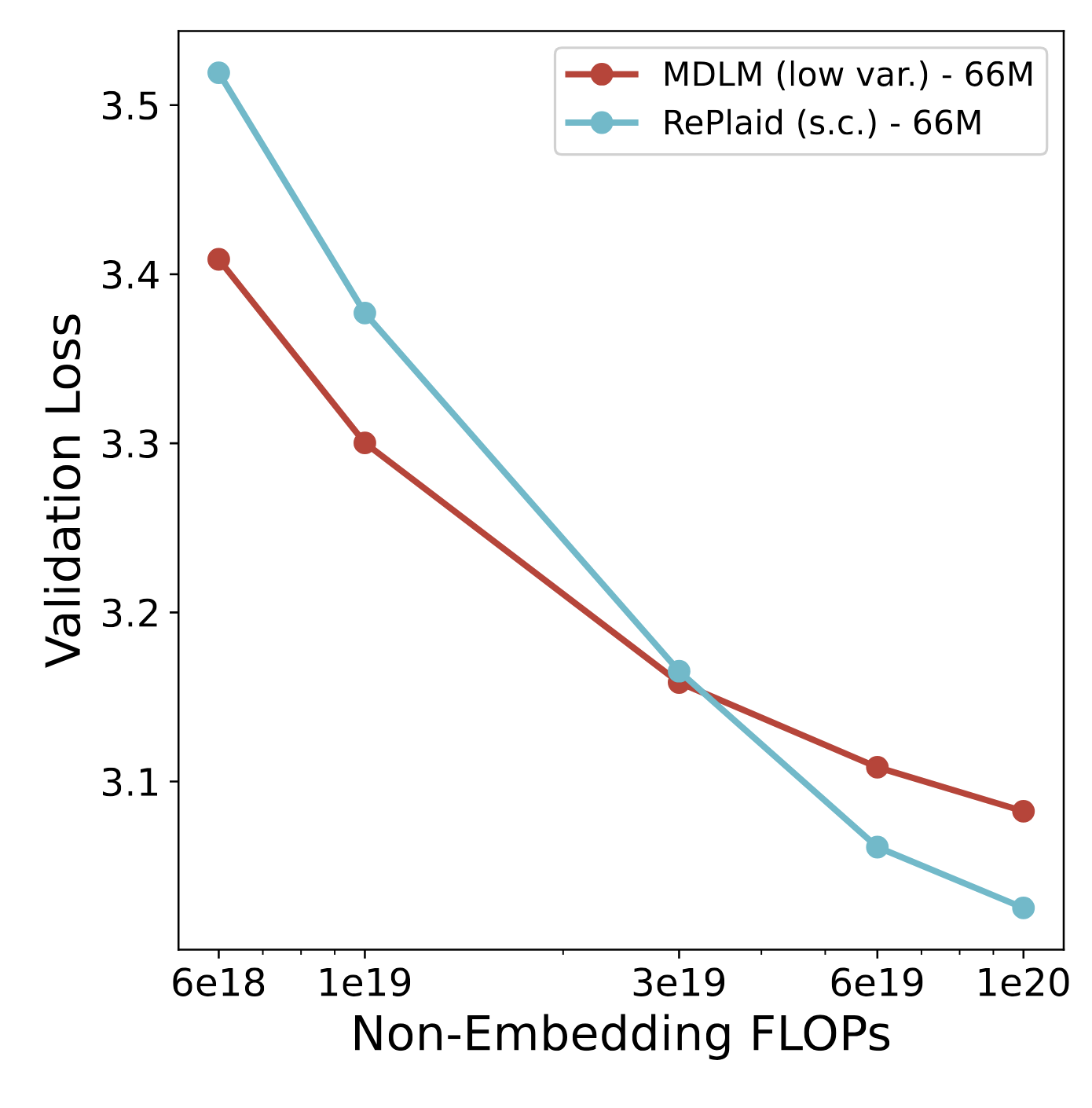
On OWT, RePlaid (s.c.) attains the best perplexity bound of 22.1 among all
considered DLMs — improving over the strongest discrete baseline MDLM (low var., 23.1), and
outperforming Duo (25.2), the original Plaid (24.4), and the concurrent LangFlow
(32.2). Even without self-conditioning, RePlaid reaches 23.6 — already below Duo's
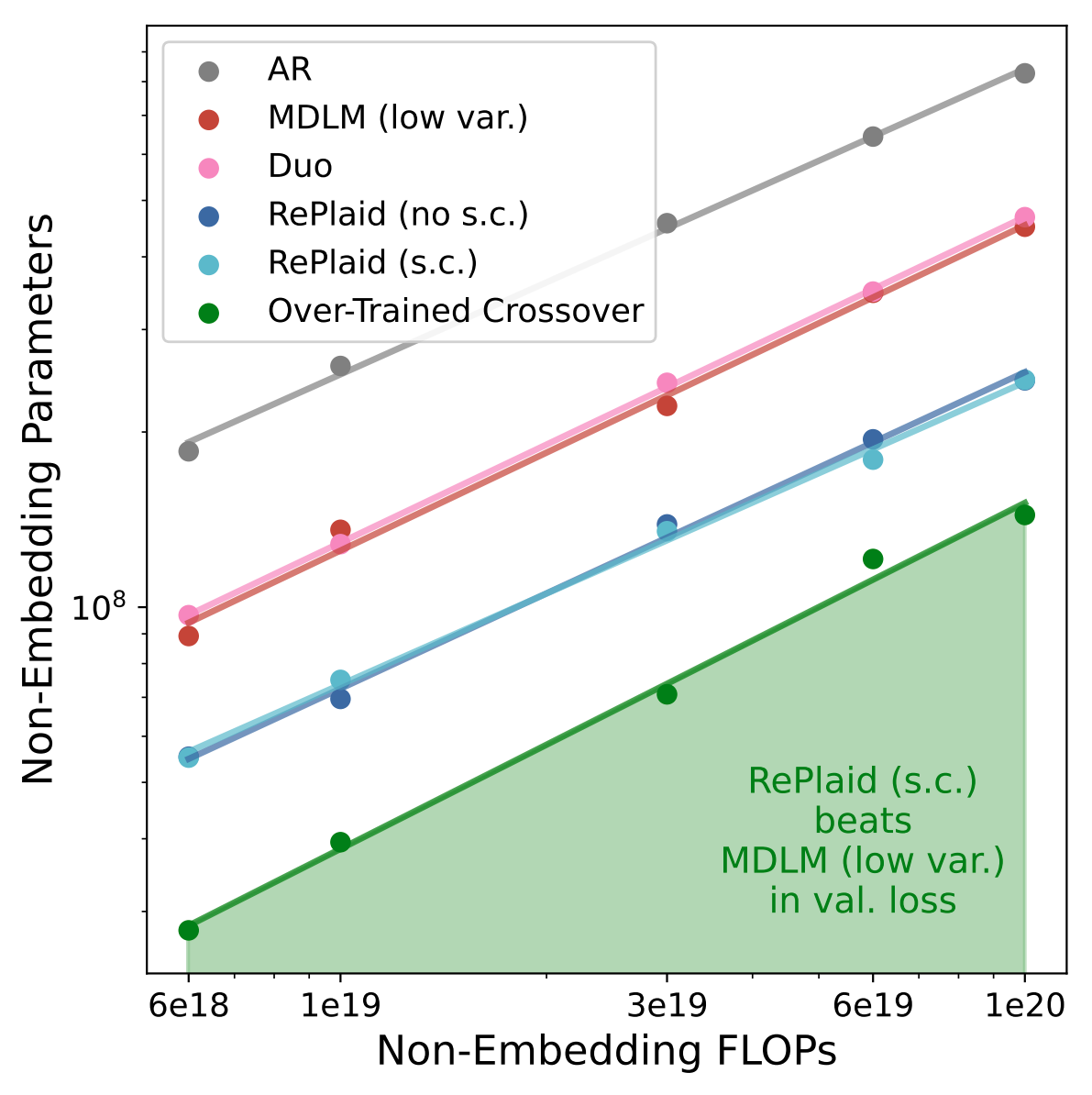
25.2 and far ahead of LangFlow's 38.4. The gap to MDLM shrinks further at 250K steps, consistent with
the over-training crossover seen in the scaling study.
| Model | Category | OWT PPL (↓) |
|---|
| LangFlow (no s.c.) | Continuous diffusion | 38.4 |
| LangFlow (s.c.) | Continuous diffusion | 32.2 |
| Plaid (no s.c.) | Continuous diffusion | 25.7 |
| Duo | Discrete diffusion (uniform) | 25.2 |
| Plaid (s.c.) | Continuous diffusion | 24.4 |
| RePlaid (no s.c.) | Continuous diffusion | 23.6 |
| MDLM | Discrete diffusion (mask) | 23.2 |
| MDLM (low var.) | Discrete diffusion (mask) | 23.1 |
| RePlaid (s.c.) | Continuous diffusion | 22.1 |
| AR Transformer | Autoregressive | 17.5 |
Test perplexity bounds on OWT (L = 1024, 1M steps), computed from the NELBO as in prior work.
RePlaid (s.c.) sets a new state of the art among continuous DLMs and beats all considered discrete baselines.