Images generated by DisCo-Diff with shared discrete latents.
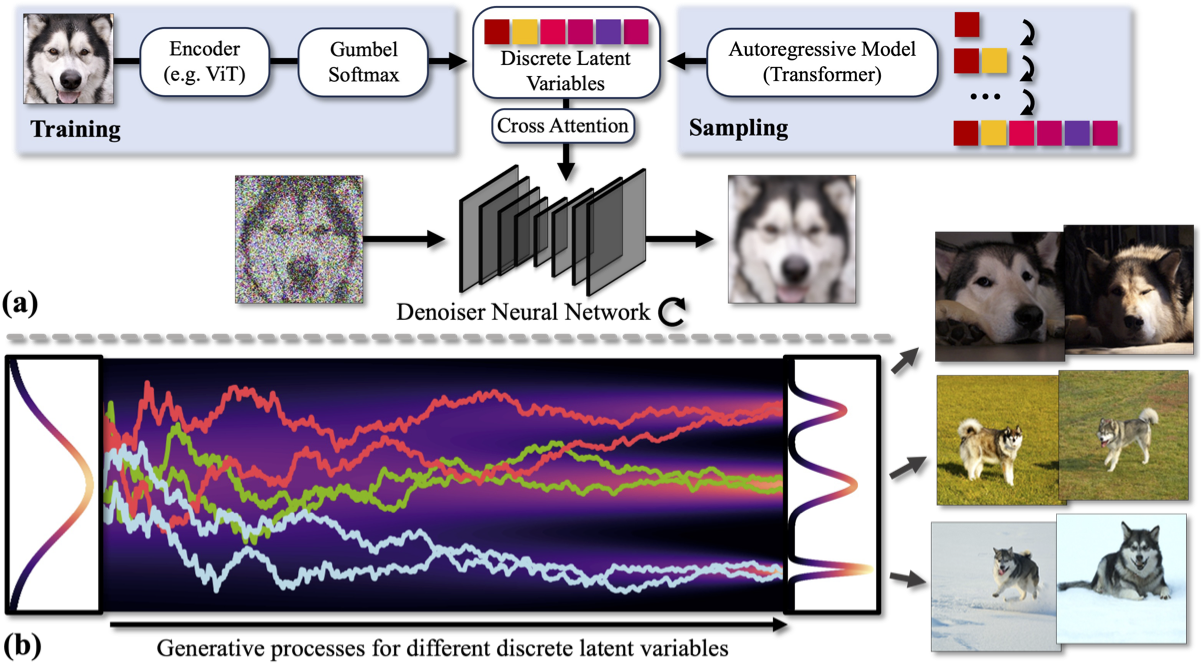
Diffusion models (DMs) have revolutionized generative learning. They utilize a diffusion process to encode data into a simple Gaussian distribution. However, encoding a complex, potentially multimodal data distribution into a single continuous Gaussian distribution arguably represents an unnecessarily challenging learning problem. We propose Discrete-Continuous Latent Variable Diffusion Models (DisCo-Diff) to simplify this task by introducing complementary discrete latent variables. We augment DMs with learnable discrete latents, inferred with an encoder, and train DM and encoder end-to-end. DisCo-Diff does not rely on pre-trained networks, making the framework universally applicable. The discrete latents significantly simplify learning the DM's complex noise-to-data mapping by reducing the curvature of the DM's generative ODE. An additional autoregressive transformer models the distribution of the discrete latents, a simple step because DisCo-Diff requires only few discrete variables with small codebooks. We validate DisCo-Diff on toy data, several image synthesis tasks as well as molecular docking, and find that introducing discrete latents consistently improves model performance. For example, DisCo-Diff achieves state-of-the-art FID scores on class-conditioned ImageNet-64/128 datasets with ODE sampler.
Diffusion models transform the Gaussian prior into the data distribution through a generative ordinary differential equation (ODE). However, realistic data distributions are typically high-dimensional, complex and often multimodal. Directly encoding such data into a single unimodal Gaussian distribution and learning a corresponding reverse noise-to-data mapping is challenging. The mapping, or generative ODE, necessarily needs to be highly complex, with strong curvature (see the middle figure below).
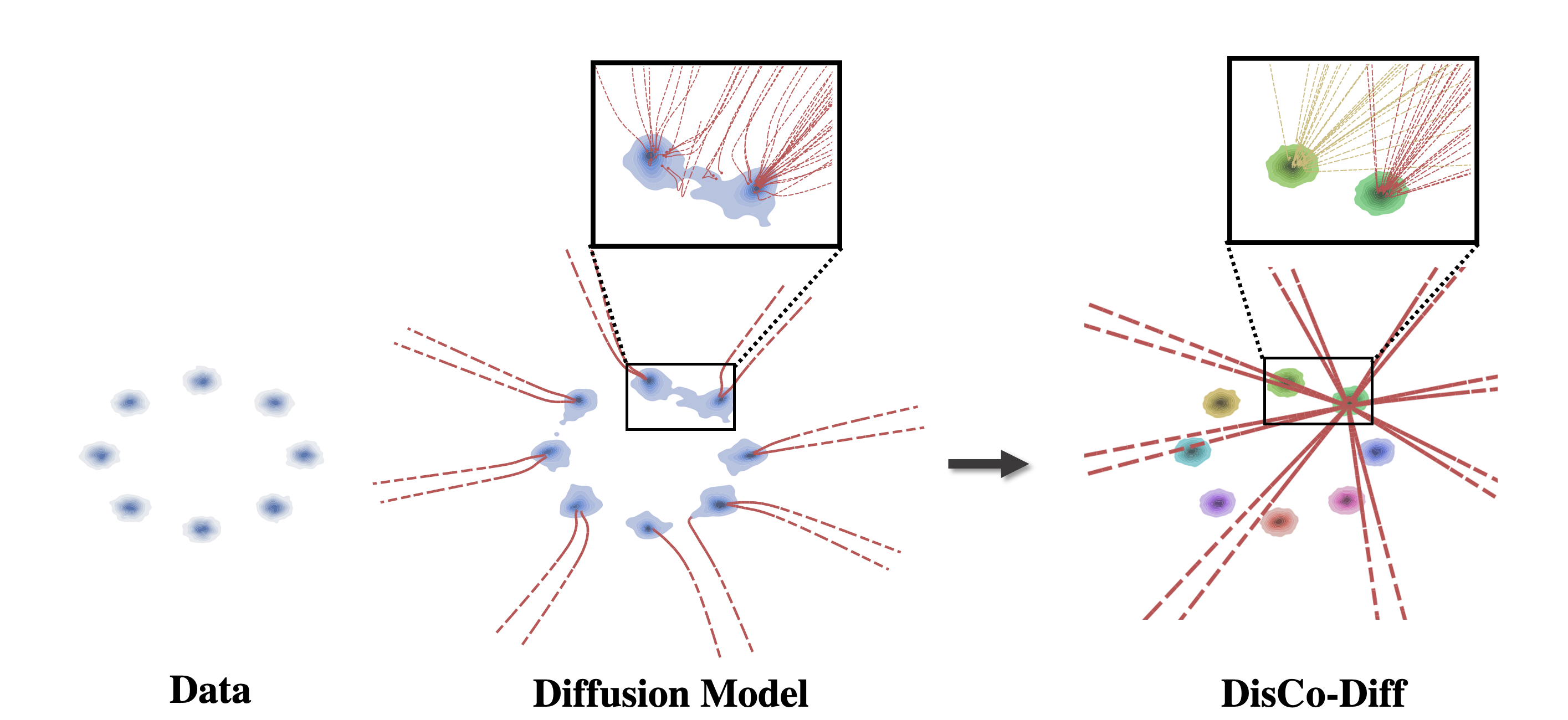
Modeling 2D mixture of Gaussians. Left: Data distribution. Middle: Generated data by regular DM. Right: Generated data by DisCo-Diff, given a discrete latent. We use different colors to distinguish data generated by different discrete latents. We further provide zoom-ins and visualize some ODE trajectories by dotted lines.
The proposed DisCo-Diff augments DMs with discrete latent variables that encode additional high-level information about the data and can be used by the main DM to simplify its denoising task. These discrete latents are inferred through an encoder network and learnt end-to-end together with the DM. Thereby, the discrete latents directly learn to encode information that is beneficial for reducing the DM's score matching objective and making the DM's hard task of mapping simple noise to complex data easier. DisCo-Diff's discrete latents capture the different modes, and DisCo-Diff's DM component models the individual modes. The DM's ODE trajectories for different latents are now almost perfectly straight (see the right figure above), indicating a simple conditional score function. We do not rely on domain-specific pre-trained encoder networks, making our framework general and universally applicable. To facilitate sampling of discrete latent variables during inference, we learn an autoregressive model over the discrete latents in a second step.
While previous works, such as VQ-VAE, DALL-E 2, or MaskGIT, use fully discrete latent variable-based approaches to model images, this typically requires large sets of spatially arranged latents with large codebooks, which makes learning their distribution challenging. DisCo-Diff, in contrast, carefully combines its discrete latents with the continuous latents (Gaussian prior) of the DM and effectively separates the modeling of discrete and continuous variations within the data. It requires only a few discrete latents. For example, we use just 10 discrete latents with a codebook size of 100 in our main image models.


Samples generated from DisCo-Diff trained on the ImageNet dataset: (a) randomly sampled discrete latents and class labels; (b) samples in each grid sharing the same discrete latent. The class label for the top/bottom row is fixed to bird/crocodile.
In our DisCo-Diff framework, we augment a DM's learning process with an \(m\)-dimensional discrete latent \(\mathbf{z} \in \mathbb{N}^m\), where each dimension is a random variable from a categorical distribution of codebook size \(k\). There are three learnable components: the denoiser neural network \(\mathbf{D}_\theta\), corresponding to DisCo-Diff's DM, which predicts denoised images conditioned on diffusion time \(t\) and discrete latent \(\mathbf{z}\); an encoder \(\mathbf{E}_\phi\), used to infer discrete latents given clean images \(\mathbf{y}\). It outputs a categorical distribution over the \(k\) categories for each discrete latent; and a post-hoc auto-regressive model \(\mathbf{A}_\psi\), which approximates the distribution of the learned discrete latents \(\mathbf{z}\) by \(\prod_{i=1}^m p_\psi(\mathbf{z}_i | \mathbf{z}_{ \lt i})\). DisCo-Diff's training process is divided into two stages, as summarized in the figure above.
Stage I: We follow the EDM framework to incorporate the discrete latents into the diffusion models. The denoiser \(\mathbf{D}_\theta\) and the encoder \(\mathbf{E}_\phi\) are co-optimized in an end-to-end fashion. This is achieved by extending the denoising score matching objective in EDM to include learnable discrete latents \(\mathbf{z}\) associated with each data \(\mathbf{y}\).:
\(\mathbb{E}_{\mathbf{y}} \mathbb{E}_{\mathbf{z} \sim \mathbf{E}_\phi(\mathbf{y})} \mathbb{E}_{t,\mathbf{n}}\left[\lambda(t)||\mathbf{D}_\theta(\mathbf{y}+\mathbf{n}, \sigma(t), \mathbf{z})-\mathbf{y}||^2\right]\)
where the clean image \(\mathbf{y}\sim p_{\textrm{data}}(\mathbf{y})\). The denoiser network \(\mathbf{D}_\theta\) can better capture the time-dependent score (i.e., achieving a reduced loss) if the score for each sub-distribution \(p(\mathbf{x}|\mathbf{z}; \sigma(t))\) is simplified. Therefore, the encoder \(\mathbf{E}_\phi\), which has access to clean input data, is encouraged to encode useful information into the discrete latents and help the denoiser to more accurately reconstruct the data. During training we rely on a continuous relaxation based on the Gumbel-Softmax distribution. We can interpret DisCo-Diff as a variational autoencoder (VAE) with discrete latents and a DM as decoder. VAEs often employ regularization on their latents. We did not find this to be necessary, as we use only very low-dimensional latent variables, e.g., 10 in our ImageNet experiments, with a codebook size of 100.
Stage II: We train a post-hoc autoregressive model \(\mathbf{A}_\psi\) to capture the distribution of the discrete latent variables \(p_\psi(\mathbf{z})\) defined by pushing the clean data through the trained encoder, using a standard maximum likelihood objective. Since we set \(m\) to a relatively small number (e.g., 10), it becomes very easy for the model to handle such short discrete vectors, which makes this second-stage training efficient. Also the additional sampling overhead due to this autoregressive component on top of the DM becomes negligible (only around 0.5% in our main image experiments). At inference time, when using DisCo-Diff to generate novel samples, we first sample a discrete latent variable from the autoregressive model, and then sample the DM with an ODE or SDE solver.
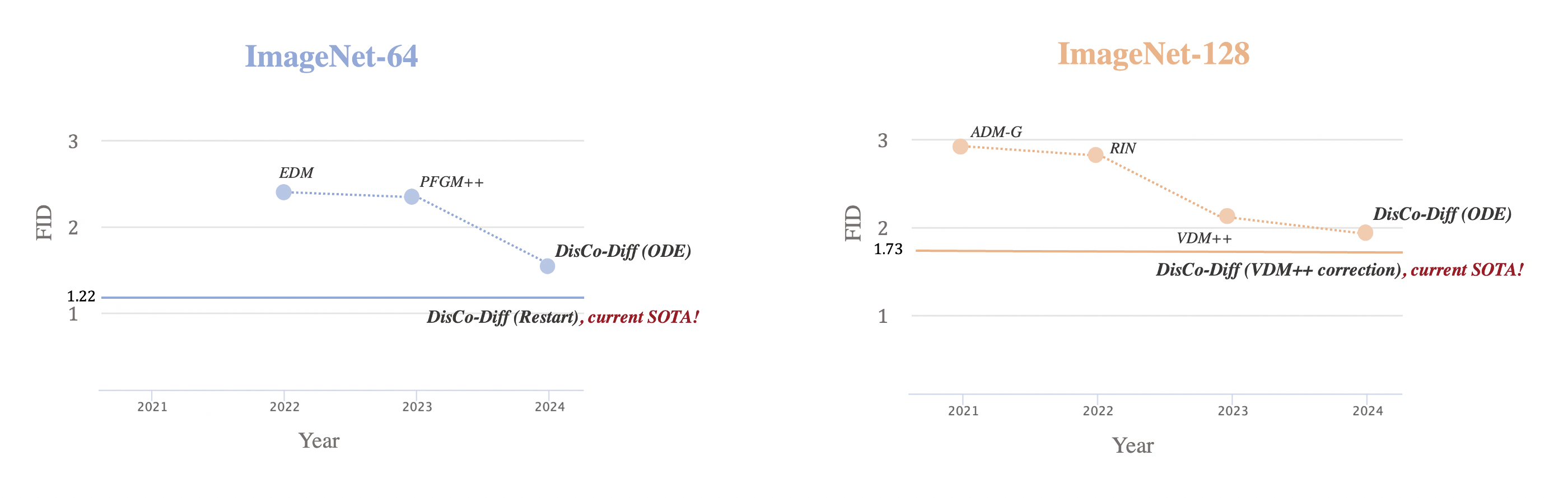
Image Synthesis: We extensively validate DisCo-Diff on class-conditioned ImageNet (\(64 \times 64\) and \(128 \times 128\)). In practice, we integrate discrete latents into EDM on ImageNet-64, and VDM++ on ImageNet-128 to build DisCo-Diff. We demonstrate that DisCo-Diff achieves the new state-of-the-art on class-conditioned ImageNet-64/ImageNet-128 when using ODE sampler, improving the FID score of EDM from 2.36 to 1.66, and the FID score of VDM++ from 2.29 to 1.98. When using stochastic samplers, DisCo-Diff further sets the current record FID scores of 1.22 on ImageNet-64 and 1.73 on ImageNet-128.
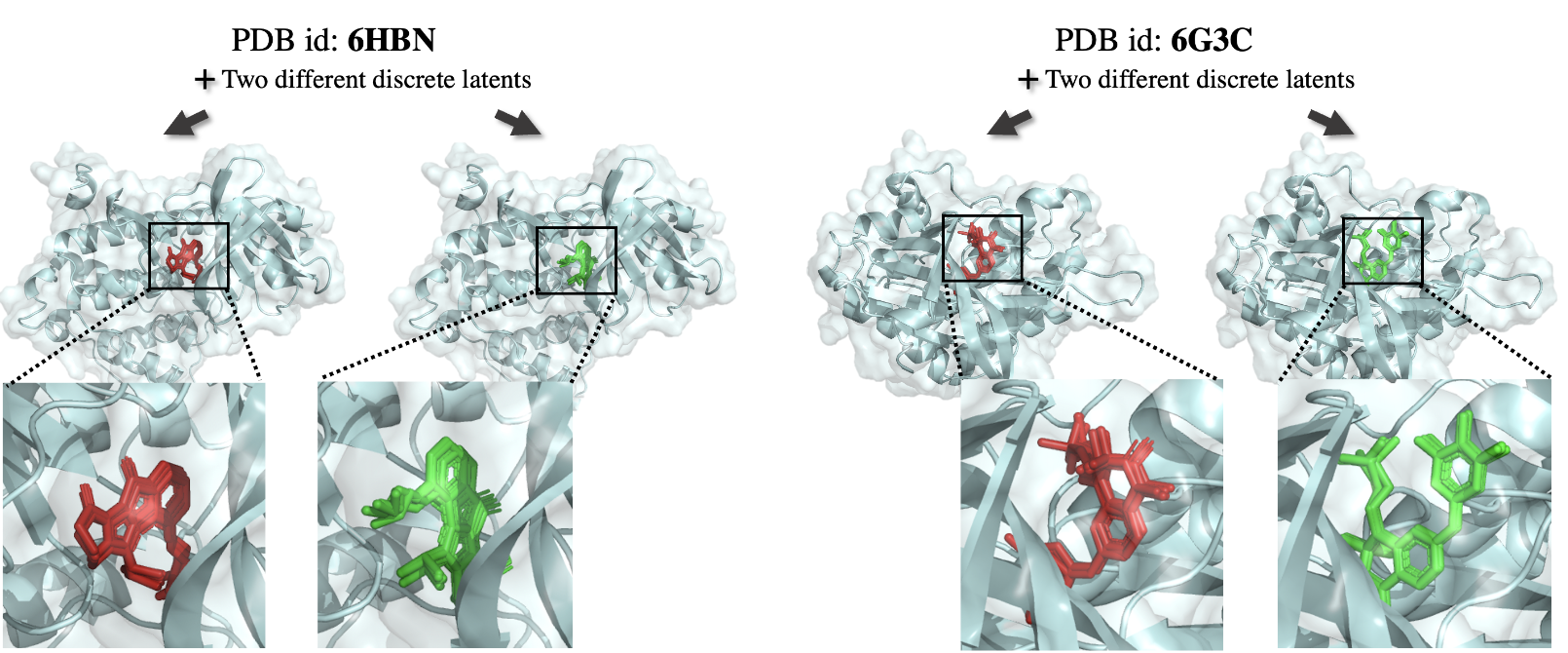
Molecular Docking: We test DisCo-Diff also on molecular docking, building upon the DiffDock framework. We see that also in this domain discrete latents provide improvements, with the success rate on the full dataset increasing from 32.9% to 35.4% and from 13.9% to 18.5% when considering only test complexes with unseen proteins. Below, we visualize two examples from the test set which highlight how the model learns to associate distinct sets of poses with different latents
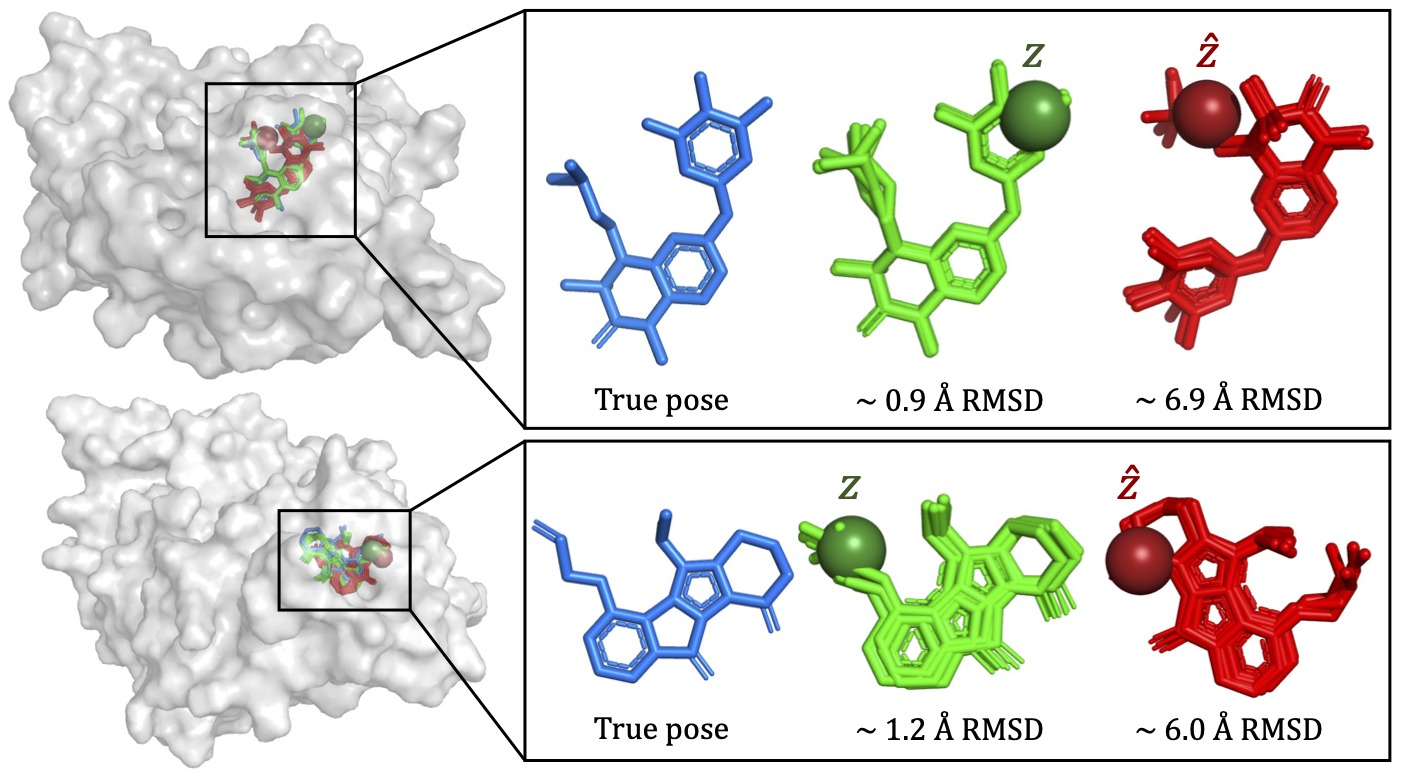
Examples of alternative docking poses modeled when conditioning on different discrete latents, the “correct” \(z\) (i.e., same as the encoder) and an incorrect \(\hat{z}\). The DM maps them to two distinct sets of orientations with which the ligand could fit in the pocket.
DisCo-Diff: Enhancing Continuous Diffusion Models with Discrete Latents Yilun Xu, Gabriele Corso, Tommi Jaakkola, Arash Vahdat, Karsten Kreis International Conference on Machine Learning, 2024Paper

@inproceedings{xu2024discodiff,
title={DisCo-Diff: Enhancing Continuous Diffusion Models with Discrete Latents},
author={Xu, Yilun and Corso, Gabriele and Jaakkola, Tommi and Vahdat, Arash and Kreis, Karsten},
booktitle={International Conference on Machine Learning},
year={2024}
}