



Abstract
Overcoming Autoregressive Bottlenecks in VLM Grounding
Vision-language models (VLMs) commonly formulate visual grounding and detection as a coordinate-token generation problem, serializing each 2D box into multiple 1D tokens that are learned and decoded largely independently. This token-by-token decoding mismatches the coupled structure of box geometry and creates a practical inference bottleneck due to strictly sequential generation.
We introduce LocateAnything, a unified generative grounding and detection framework based on Parallel Box Decoding (PBD). By decoding geometric elements such as bounding boxes and points as atomic units in a single step, LocateAnything preserves intra-box geometric coherence and unlocks substantial parallelism. We show that PBD improves both decoding throughput and localization accuracy.
We further develop a scalable data engine and curate LocateAnything-Data, a large-scale dataset with more than 138 million training samples, substantially increasing data diversity for high-precision localization. Extensive evaluations show that LocateAnything advances the speed–accuracy frontier, achieving significantly higher decoding throughput while improving high-IoU localization quality across diverse benchmarks. The results highlight the complementary benefits of Parallel Box Decoding and large-scale training data in enabling efficient and precise unified visual grounding and detection.
Method
LocateAnything: Parallel Box Decoding
To reconcile high-throughput decoding with reliable localization, we propose LocateAnything, a unified framework for VLM-based visual detection and grounding built upon Parallel Box Decoding (PBD).
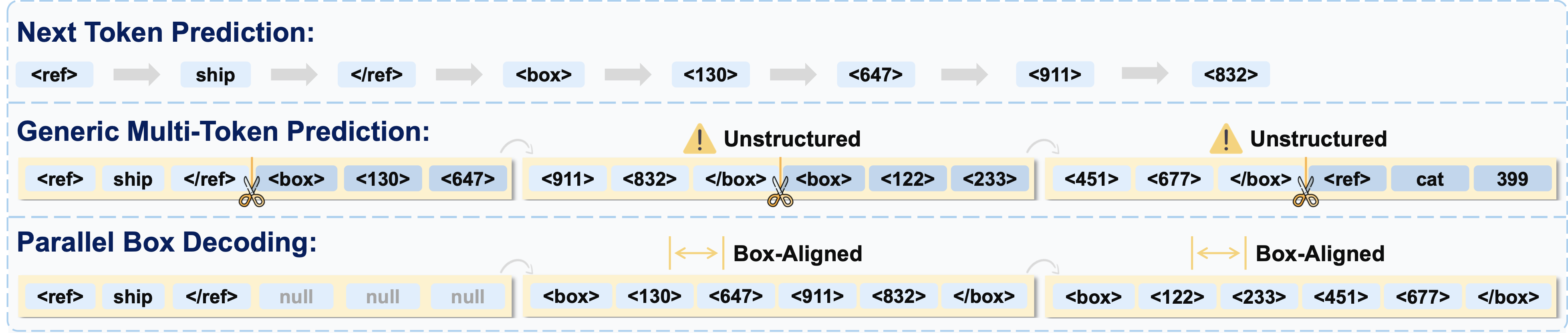 Comparison of standard token decoding methods vs Parallel Box Decoding (PBD).
Comparison of standard token decoding methods vs Parallel Box Decoding (PBD).
Box-Aligned Atomic Units
- Input: An image and a natural language text query. The vision encoder extracts visual tokens at native resolution, preserving fine-grained spatial details for high-precision localization.
- Parallel Decoding: LocateAnything treats each bounding box (or point) as an atomic unit of constant length and predicts the full coordinate set (x1, y1, x2, y2) in one parallel step, avoiding arbitrary chunking of coordinate tokens.
- Architecture: Built upon a Moon-ViT vision encoder and a Qwen2.5 language decoder, bridged by a MLP projector, directly converting visual tokens into a sequence of box-aligned block-level predictions.
Flexible Inference Modes
- Fast Mode (MTP): Predicts full boxes in parallel for maximum throughput, suitable for latency- and compute-constrained settings such as on-device robotics and embodied agents.
- Slow Mode (NTP): Decodes coordinate tokens autoregressively for maximum stability, appropriate for high-precision labeling, dataset curation, and accuracy-oriented offline evaluation.
- Hybrid Mode: Uses Fast Mode by default and falls back to Slow Mode when format irregularity or spatial ambiguity is detected, preserving most speed gains while maintaining robust outputs.
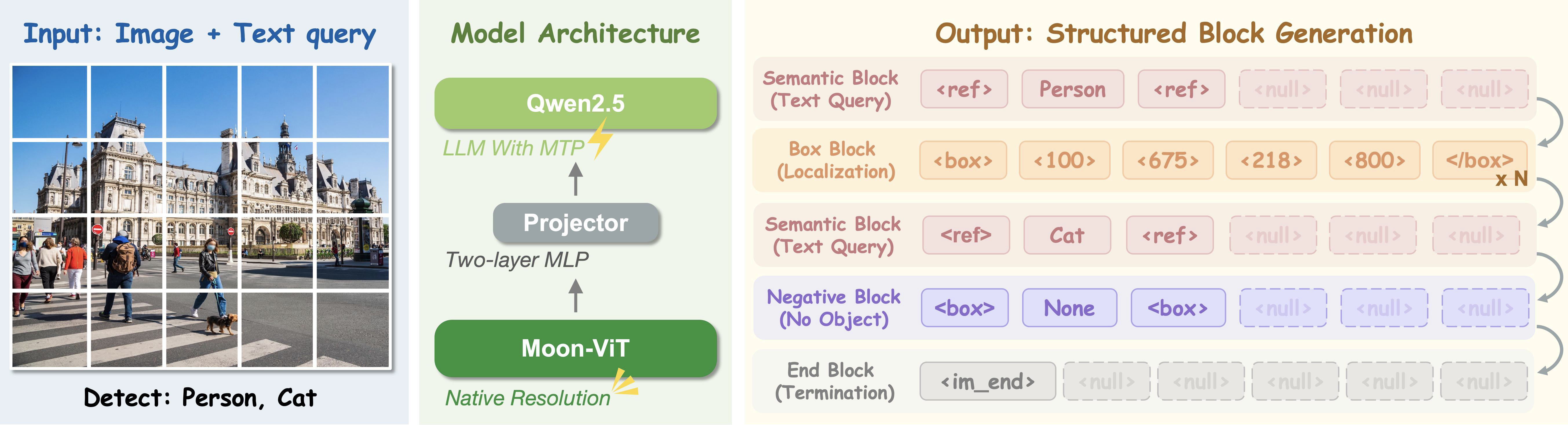 Architecture overview of LocateAnything using Parallel Box Decoding.
Architecture overview of LocateAnything using Parallel Box Decoding.
On-Demand Inference: Corrected NTP Re-decoding
When parallel decoding encounters Format Irregularity (malformed syntax at category boundaries) or Spatial Ambiguity (intermediate coordinates between densely arranged objects), the compromised block is discarded and generation reverts to the last verified prefix. NTP then autoregressively generates tokens for the problematic block before switching back to MTP.
 Corrected NTP Re-decoding: when parallel decoding encounters format irregularity or spatial
ambiguity, the model discards the erroneous block and reverts to standard NTP to ensure robust
predictions.
Corrected NTP Re-decoding: when parallel decoding encounters format irregularity or spatial
ambiguity, the model discards the erroneous block and reverts to standard NTP to ensure robust
predictions.
LocateAnything-Data
138M Diverse Language Queries and 785M Boxes
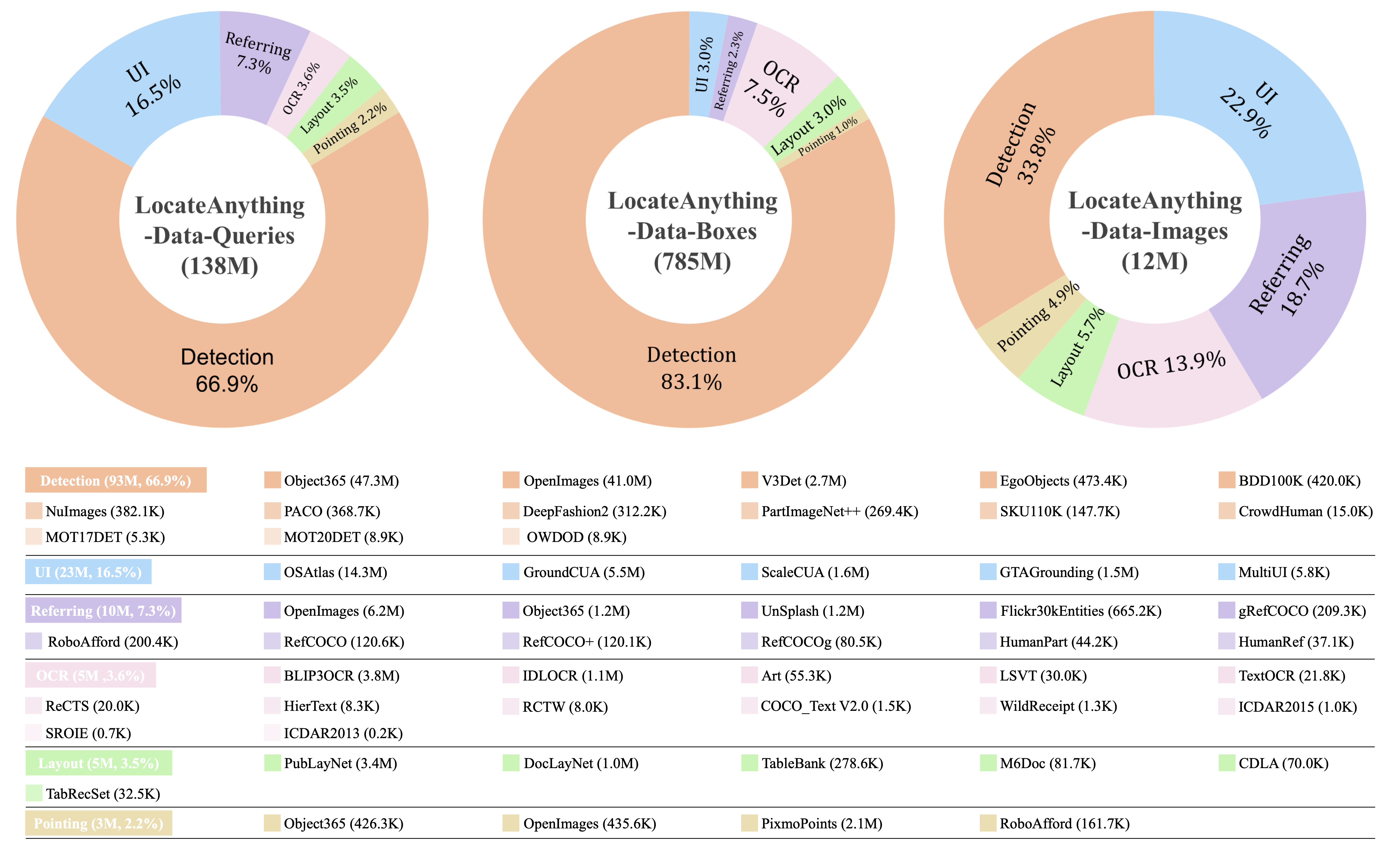 Overview of the diverse query types encompassed within LocateAnything-Data.
Overview of the diverse query types encompassed within LocateAnything-Data.
To train a highly capable model for general-purpose visual detection and grounding, we curate LocateAnything-Data, a multi-domain dataset encompassing 12M unique images and massive, dense supervisory spatial signals.
General Object Detection
66.9% of queries and 83.1% of boxes. Provides essential bounding box supervision for precise and dense coordinate alignments.
GUI Element Grounding
16.5% of queries. Enables the model to support embodied agents and graphical user interface navigation tasks.
Referring Comprehension
7.3% of queries. Links complex natural language intents to specific spatial regions within images.
Text Localization (OCR)
3.6% of queries. Perceives and tightly grounds textual information within images.
Layout Grounding
3.5% of queries. Enriches the structural reasoning capabilities for document and scene layout understanding.
Point-Based Localization
2.2% of queries. Refines spatial precision for fine-grained coordinate predictions.
Main Results
State-of-the-Art Visual Grounding & Detection
We report accuracy metrics and throughput (BPS, measured on a single NVIDIA H100 GPU) of LocateAnything under the default Hybrid Mode. LocateAnything achieves 12.7 BPS, over 10× faster than textual-based Qwen3-VL (1.1 BPS) and 2.5× faster than quantized-based Rex-Omni (5.0 BPS).
High-Quality Multi-Object Detection
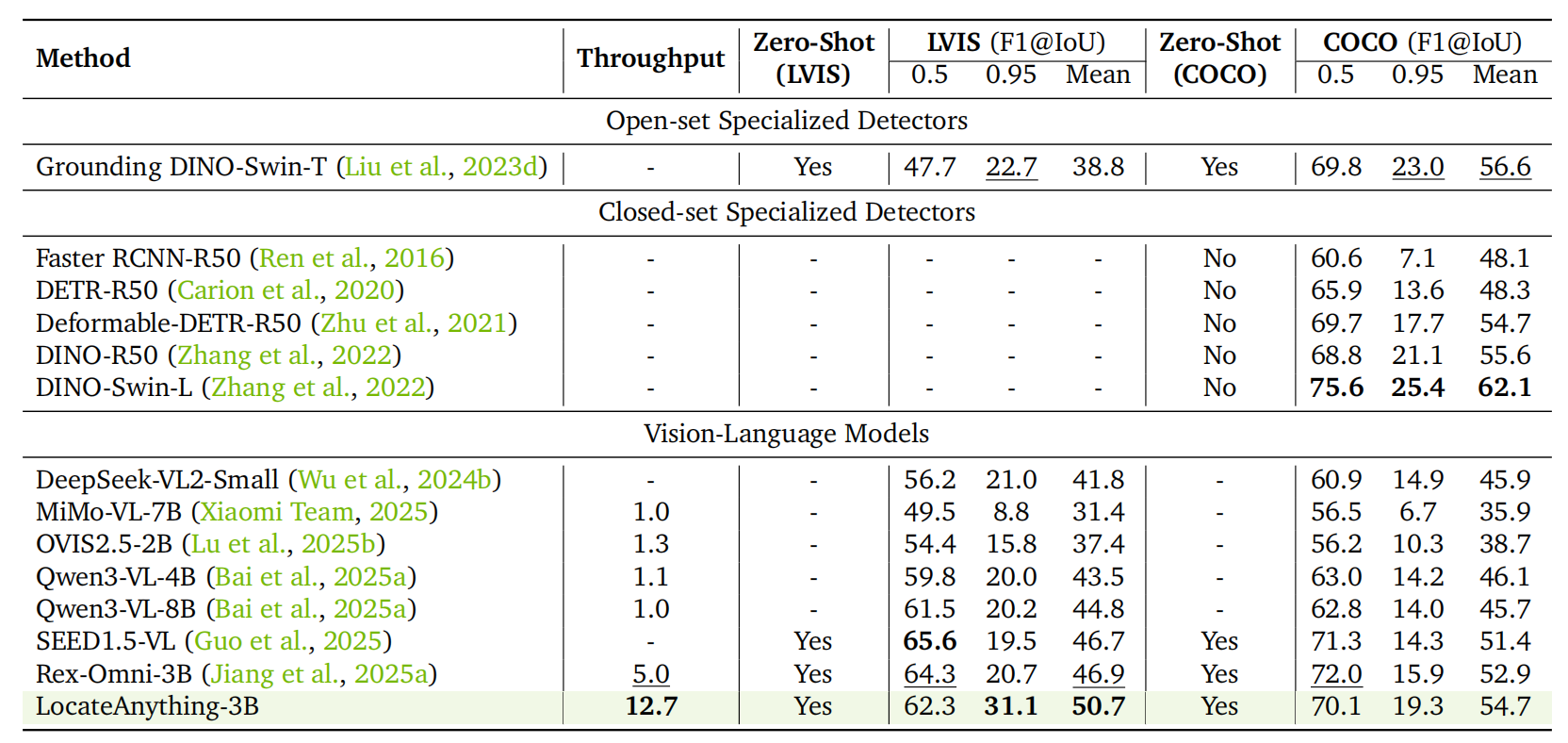 Results on LVIS and COCO.
LocateAnything improves the mean F1 by +3.8% on LVIS and +1.8% on COCO compared to
Rex-Omni at identical model size, with particularly strong gains at high IoU thresholds
(31.1 vs. 20.7 at IoU=0.95 on LVIS).
Results on LVIS and COCO.
LocateAnything improves the mean F1 by +3.8% on LVIS and +1.8% on COCO compared to
Rex-Omni at identical model size, with particularly strong gains at high IoU thresholds
(31.1 vs. 20.7 at IoU=0.95 on LVIS).
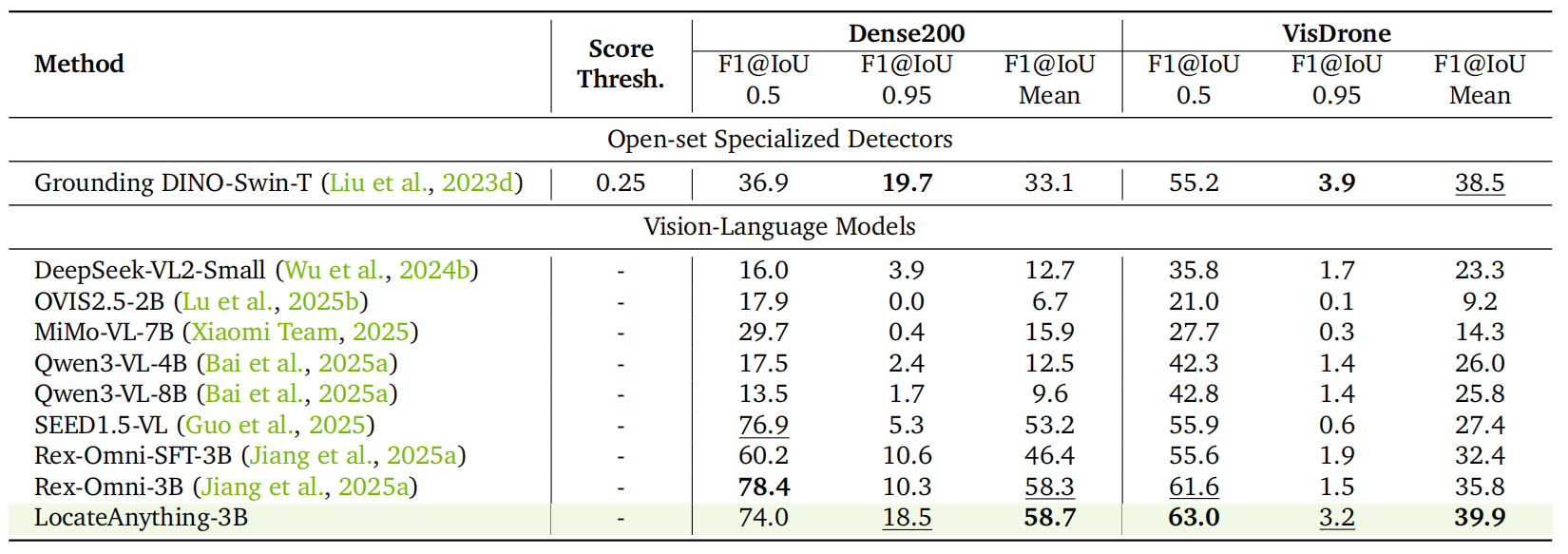 Dense Object Detection.
On dense detection benchmarks Dense200 and VisDrone, LocateAnything achieves 58.7 and 39.9
mean F1 respectively, substantially outperforming Rex-Omni (58.3 / 35.8), demonstrating
superior boundary delineation in heavily overlapping environments.
Dense Object Detection.
On dense detection benchmarks Dense200 and VisDrone, LocateAnything achieves 58.7 and 39.9
mean F1 respectively, substantially outperforming Rex-Omni (58.3 / 35.8), demonstrating
superior boundary delineation in heavily overlapping environments.
Precise Open-World Localization
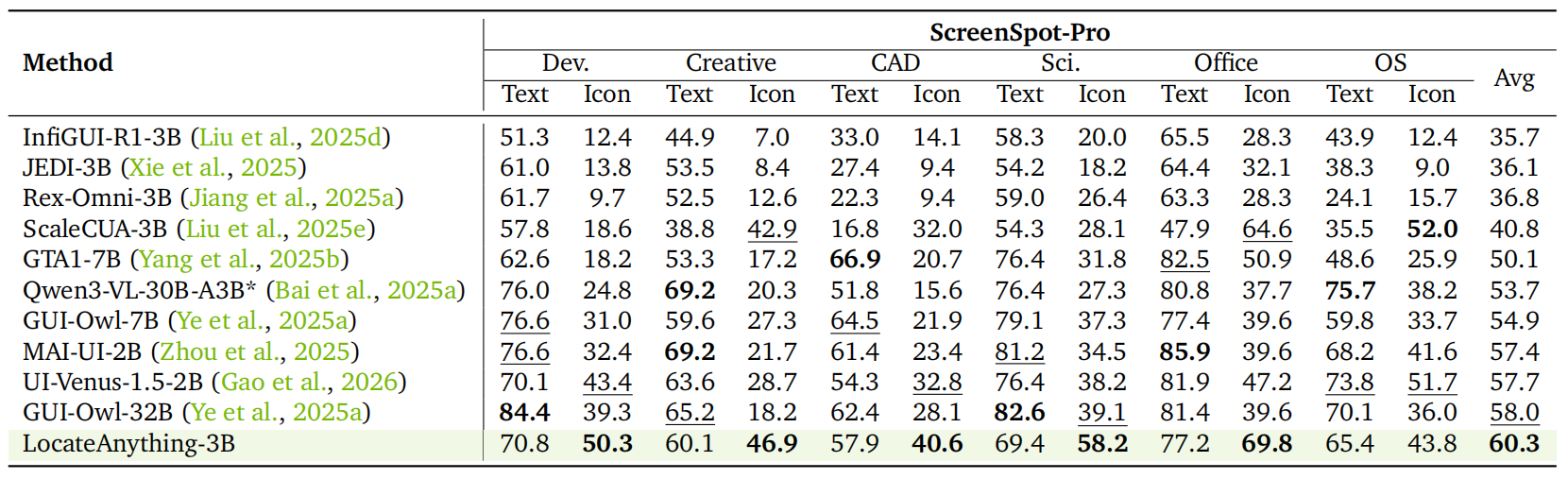 GUI Grounding (ScreenSpot-Pro).
LocateAnything achieves a SOTA mean F1 of 60.3, surpassing generalist VLMs like
Qwen3-VL-30B-A3B and specialized models such as GUI-Owl-32B, with particularly strong
performance on icon-based queries.
GUI Grounding (ScreenSpot-Pro).
LocateAnything achieves a SOTA mean F1 of 60.3, surpassing generalist VLMs like
Qwen3-VL-30B-A3B and specialized models such as GUI-Owl-32B, with particularly strong
performance on icon-based queries.
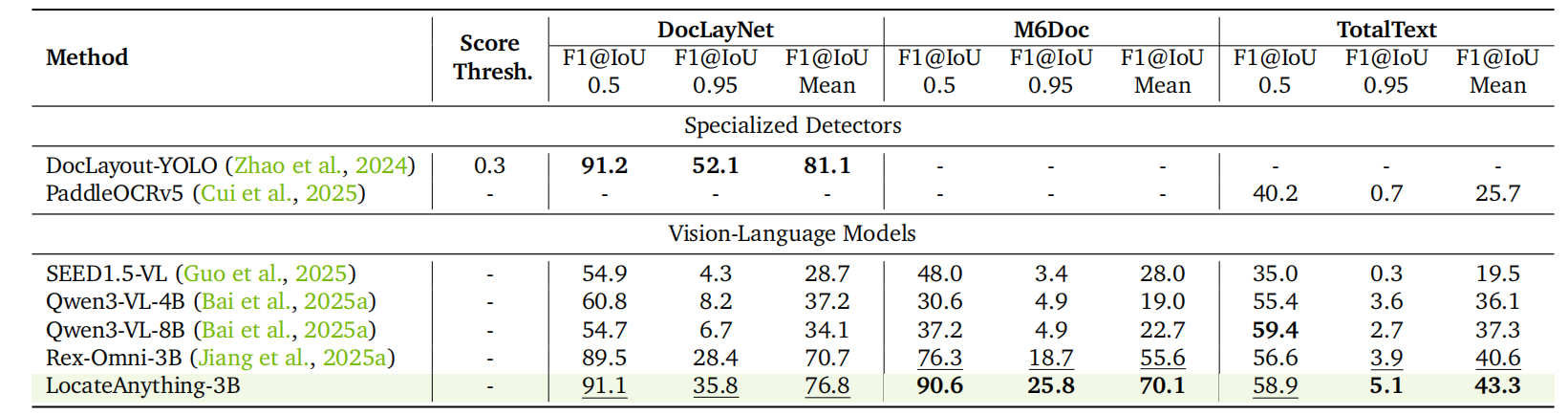 Layout Grounding & OCR.
LocateAnything establishes new standards on document understanding: 76.8 and 70.1 mean F1
on DocLayNet and M6Doc respectively, outperforming Rex-Omni by substantial margins (+6.1 / +14.5).
On TotalText OCR, it achieves 43.3 mean F1, surpassing all compared methods.
Layout Grounding & OCR.
LocateAnything establishes new standards on document understanding: 76.8 and 70.1 mean F1
on DocLayNet and M6Doc respectively, outperforming Rex-Omni by substantial margins (+6.1 / +14.5).
On TotalText OCR, it achieves 43.3 mean F1, surpassing all compared methods.
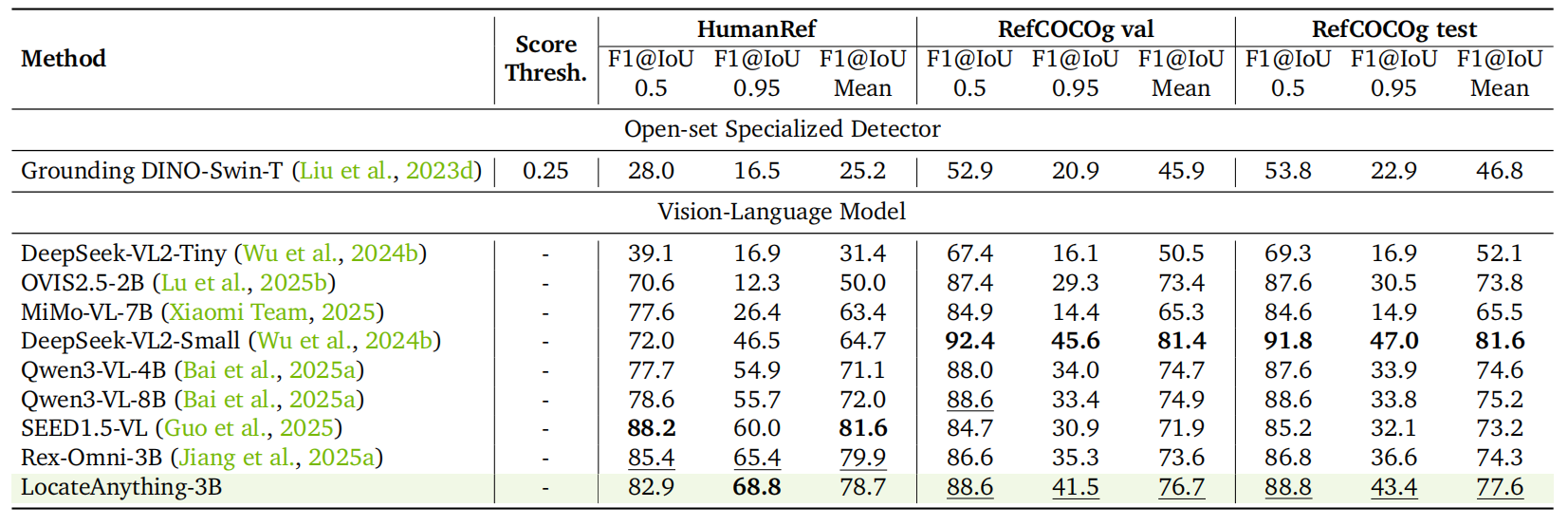 Referring Expression Comprehension.
LocateAnything seamlessly aligns nuanced human intents with visual regions, achieving
78.7 mean F1 on HumanRef and remaining highly competitive on RefCOCOg against
top-tier models.
Referring Expression Comprehension.
LocateAnything seamlessly aligns nuanced human intents with visual regions, achieving
78.7 mean F1 on HumanRef and remaining highly competitive on RefCOCOg against
top-tier models.
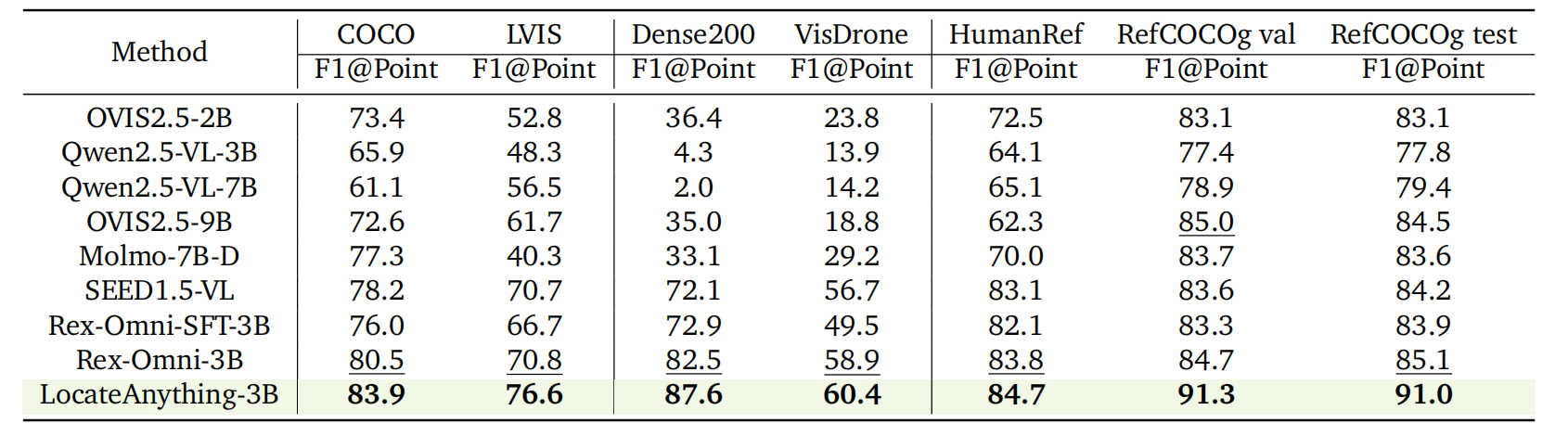 Point-Based Localization.
Evaluation on point-based grounding across COCO, LVIS, Dense200, VisDrone, HumanRef, and
RefCOCOg benchmarks.
Point-Based Localization.
Evaluation on point-based grounding across COCO, LVIS, Dense200, VisDrone, HumanRef, and
RefCOCOg benchmarks.
Ablation Study
Analyzing Design Choices and Decoding Efficiency
We conduct ablation studies on the COCO dataset to validate our core designs across coordinate representation, MTP formulation, decoding mode, box output order, and throughput scaling.
 Coordinate Representation, MTP Formulation & Decoding Modes.
(a) PBD (Slow Mode) achieves the highest F1 of 52.1, proving box-aligned formulation
provides stronger supervision than 1D serialization. (b) PBD dramatically outpaces
structure-agnostic MTP methods (16.9 BPS vs. 5.5 BPS for SDLM-B6) while improving F1.
(c) Joint training pushes Slow Mode to 52.1 F1; Hybrid Mode preserves most speed gains
(13.2 BPS) at 51.6 F1.
Coordinate Representation, MTP Formulation & Decoding Modes.
(a) PBD (Slow Mode) achieves the highest F1 of 52.1, proving box-aligned formulation
provides stronger supervision than 1D serialization. (b) PBD dramatically outpaces
structure-agnostic MTP methods (16.9 BPS vs. 5.5 BPS for SDLM-B6) while improving F1.
(c) Joint training pushes Slow Mode to 52.1 F1; Hybrid Mode preserves most speed gains
(13.2 BPS) at 51.6 F1.
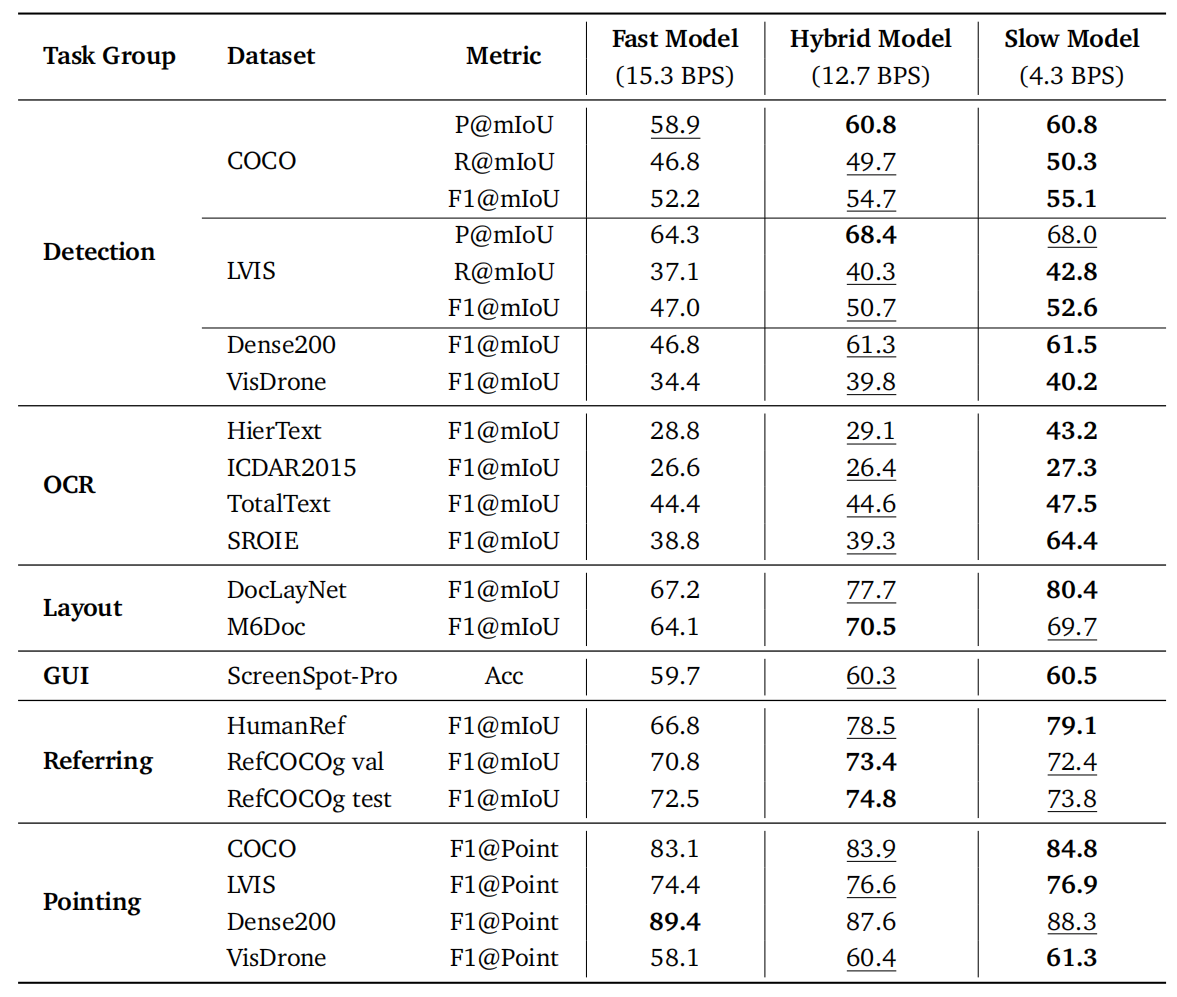 Decoding Mode Comparison.
Joint dual-formulation training successfully pushes the Slow Mode upper bound from 50.1 to
52.1 F1. Hybrid Mode seamlessly resolves the speed-accuracy trade-off, achieving robust
high-precision localization while preserving most speed gains.
Decoding Mode Comparison.
Joint dual-formulation training successfully pushes the Slow Mode upper bound from 50.1 to
52.1 F1. Hybrid Mode seamlessly resolves the speed-accuracy trade-off, achieving robust
high-precision localization while preserving most speed gains.
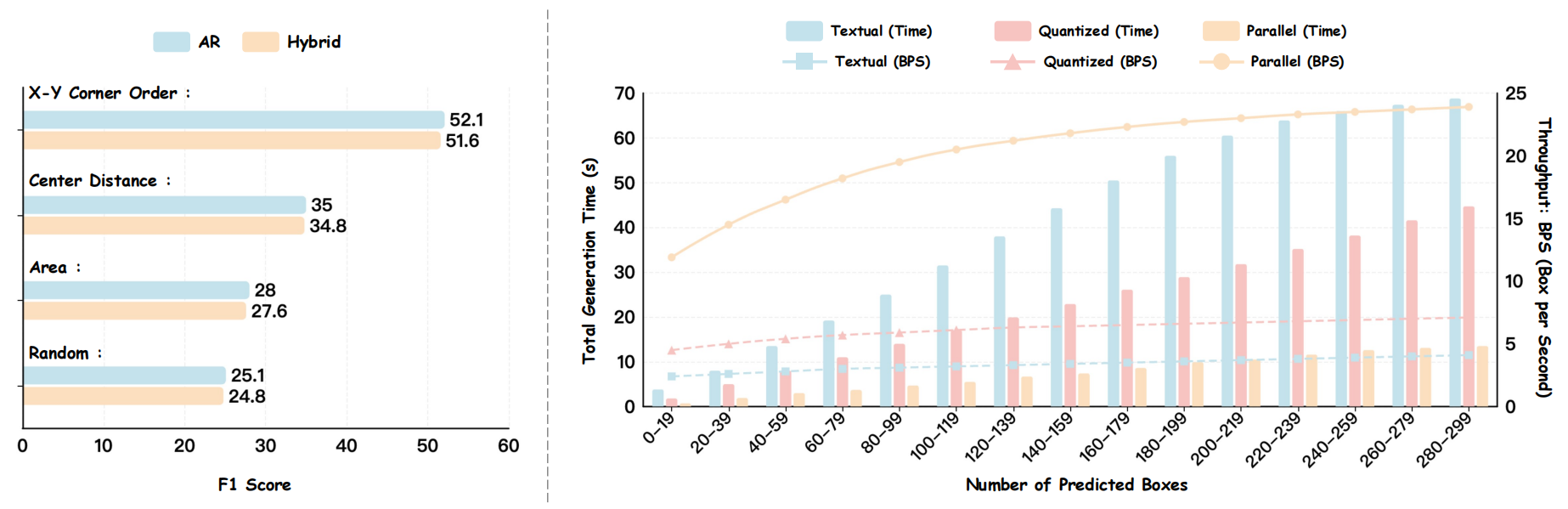 Box Ordering & Decoding Throughput.
Left: X-Y Corner Order sorting yields the highest F1-score among four spatial
ordering strategies. Right: As target boxes increase from 20 to 300, NTP methods
suffer from severe latency bottleneck, while Parallel Box Decoding achieves a 2× to 6× speedup,
scaling throughput from 12 BPS to ~25 BPS in dense scenes.
Box Ordering & Decoding Throughput.
Left: X-Y Corner Order sorting yields the highest F1-score among four spatial
ordering strategies. Right: As target boxes increase from 20 to 300, NTP methods
suffer from severe latency bottleneck, while Parallel Box Decoding achieves a 2× to 6× speedup,
scaling throughput from 12 BPS to ~25 BPS in dense scenes.
Qualitative Results
High-Quality Grounding In The Wild
LocateAnything achieves precise visual grounding across document understanding, GUI interaction, and object detection tasks.
 Qualitative visualizations of dense and high-precision box predictions across diverse
resolutions and categories.
Qualitative visualizations of dense and high-precision box predictions across diverse
resolutions and categories.
 Dense Object Detection
Dense Object Detection
 High-precision OCR
High-precision OCR
 Referring Expression Comprehension
Referring Expression Comprehension
Citation
LocateAnything
If you find LocateAnything's parallel box decoding useful for your research, please consider citing our work.
@article{wang2025locateanything,
title = {LocateAnything: Fast and High-Quality Vision-Language Grounding with Parallel Box Decoding},
author = {Shihao Wang and Shilong Liu and Yuanguo Kuang and Xinyu Wei and Yangzhou Liu and Zhiqi Li and Yunze Man and Guo Chen and Andrew Tao and Guilin Liu and Jan Kautz and Lei Zhang and Zhiding Yu},
journal = {arXiv preprint arXiv:2605.27365},
year = {2026},
}