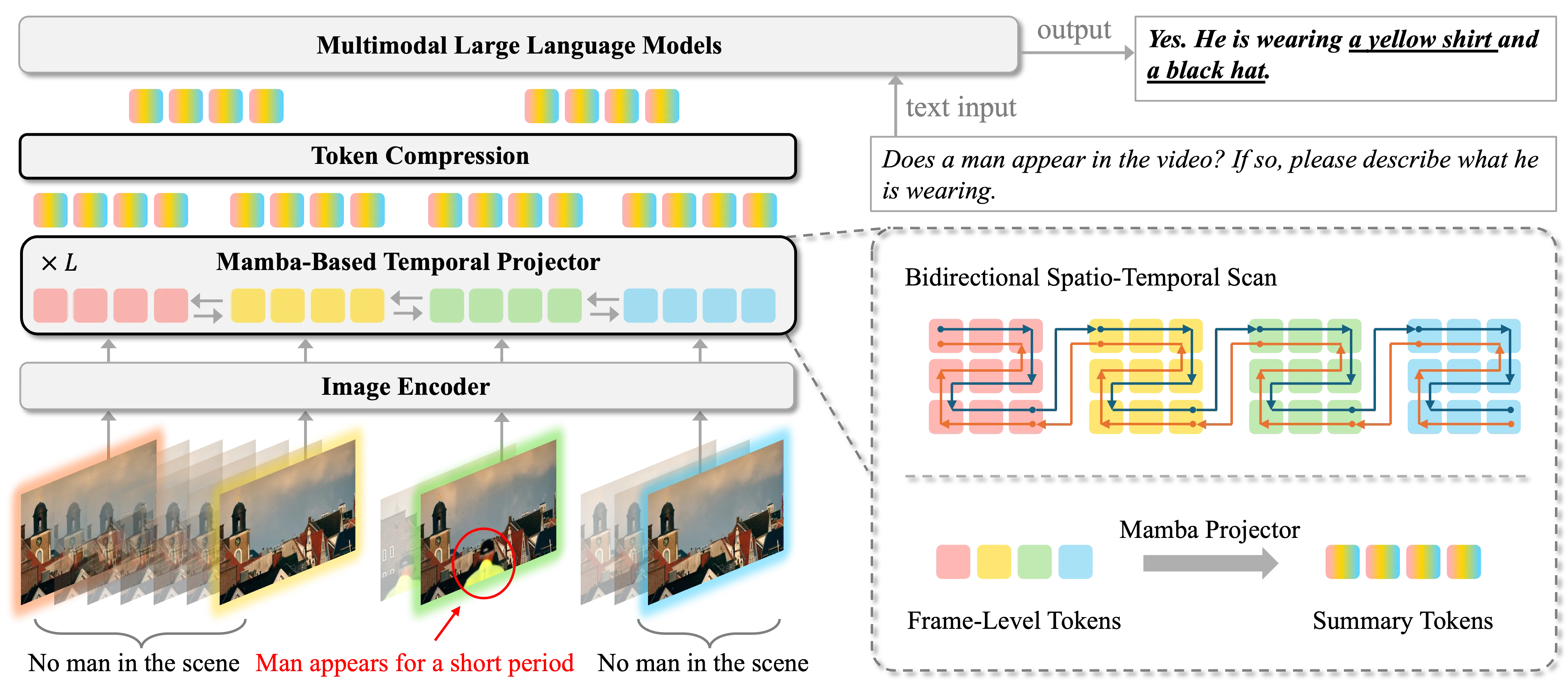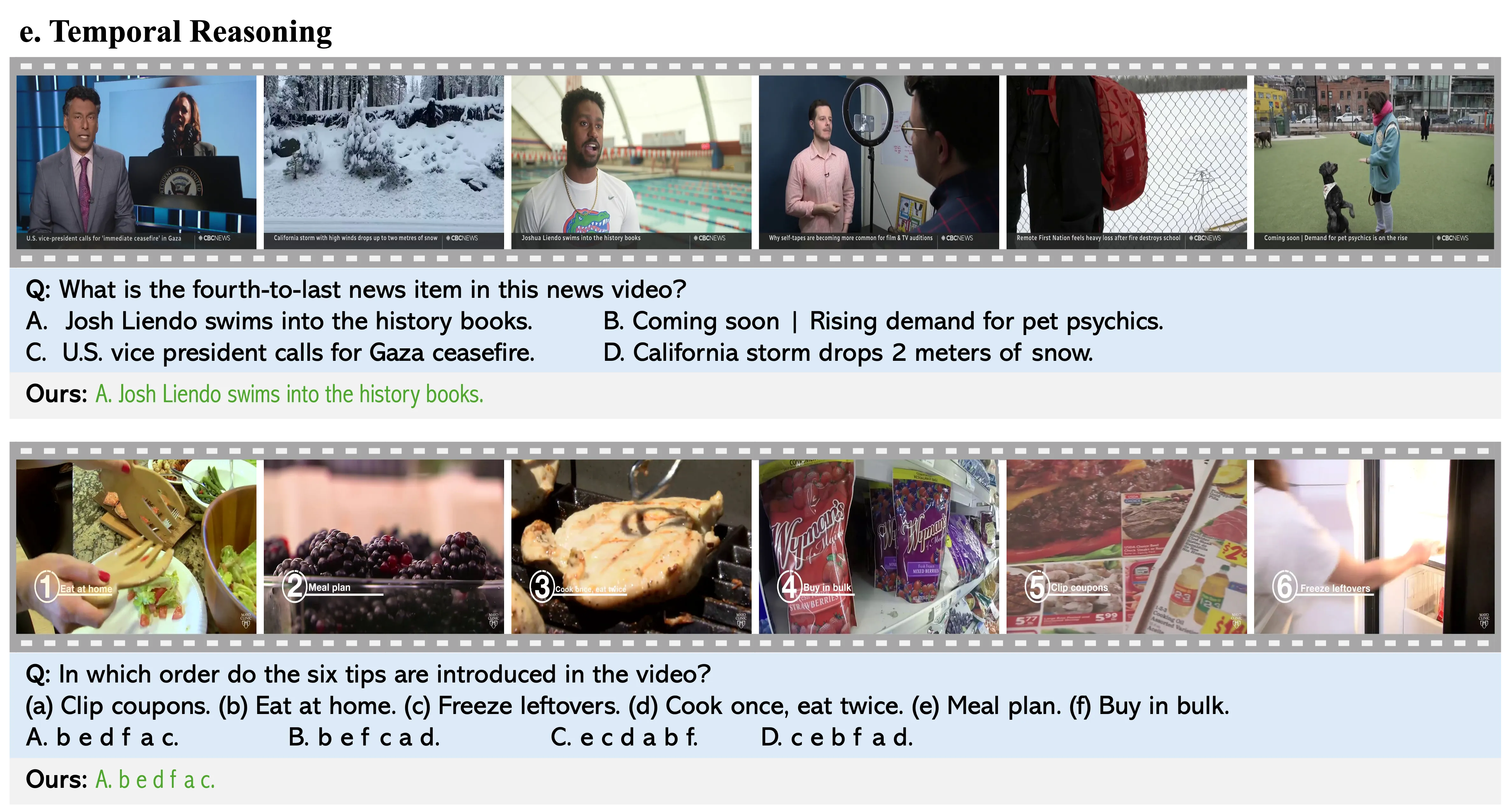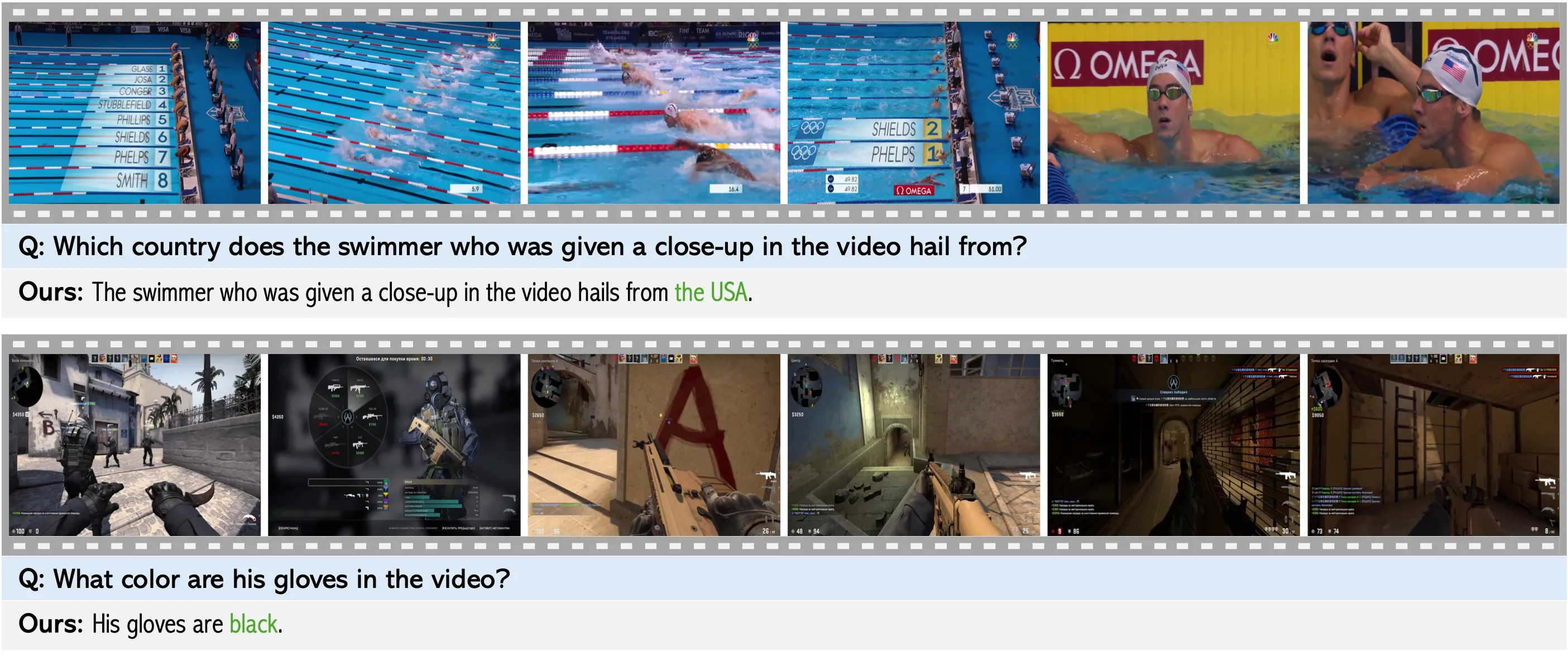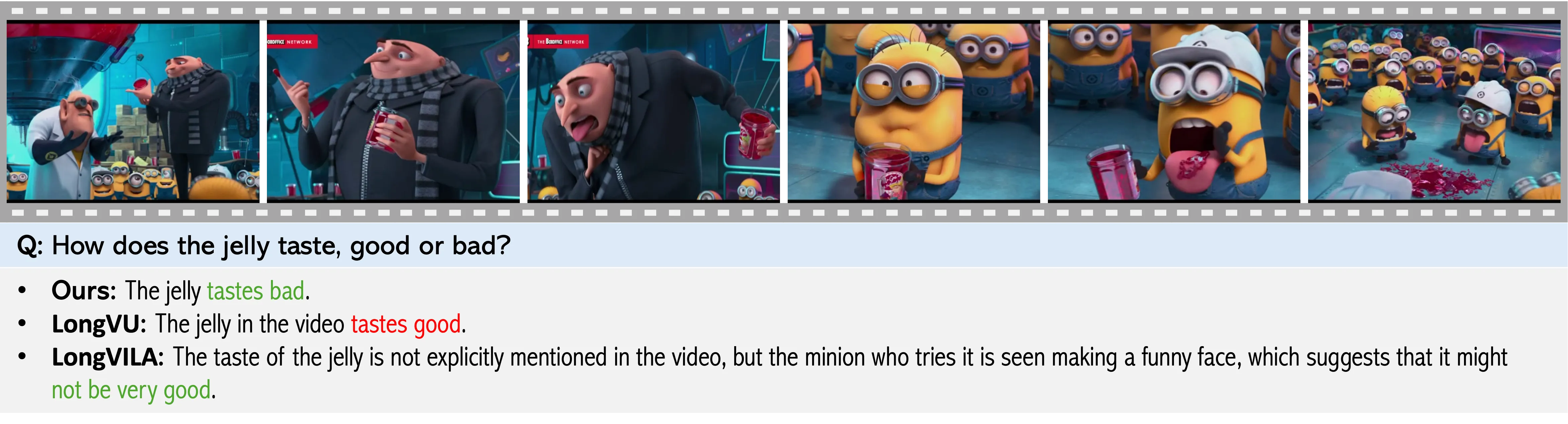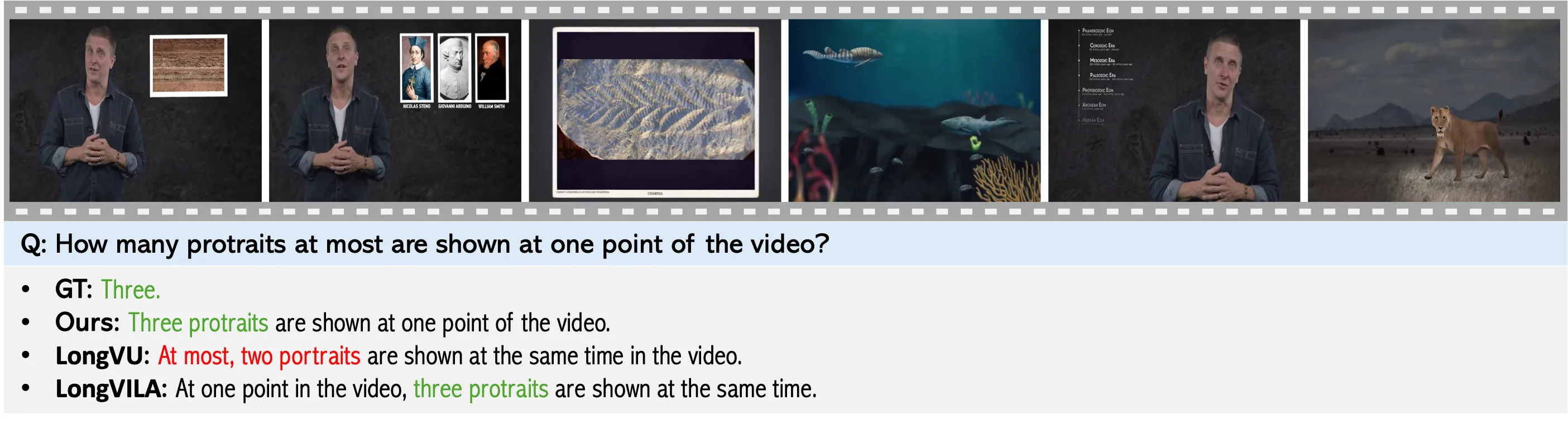
Problem: Existing Video-LLMs often rely on frame-level representations without explicit temporal encoding, leading to inefficiencies in handling long video sequences and challenges in capturing temporal dynamics.
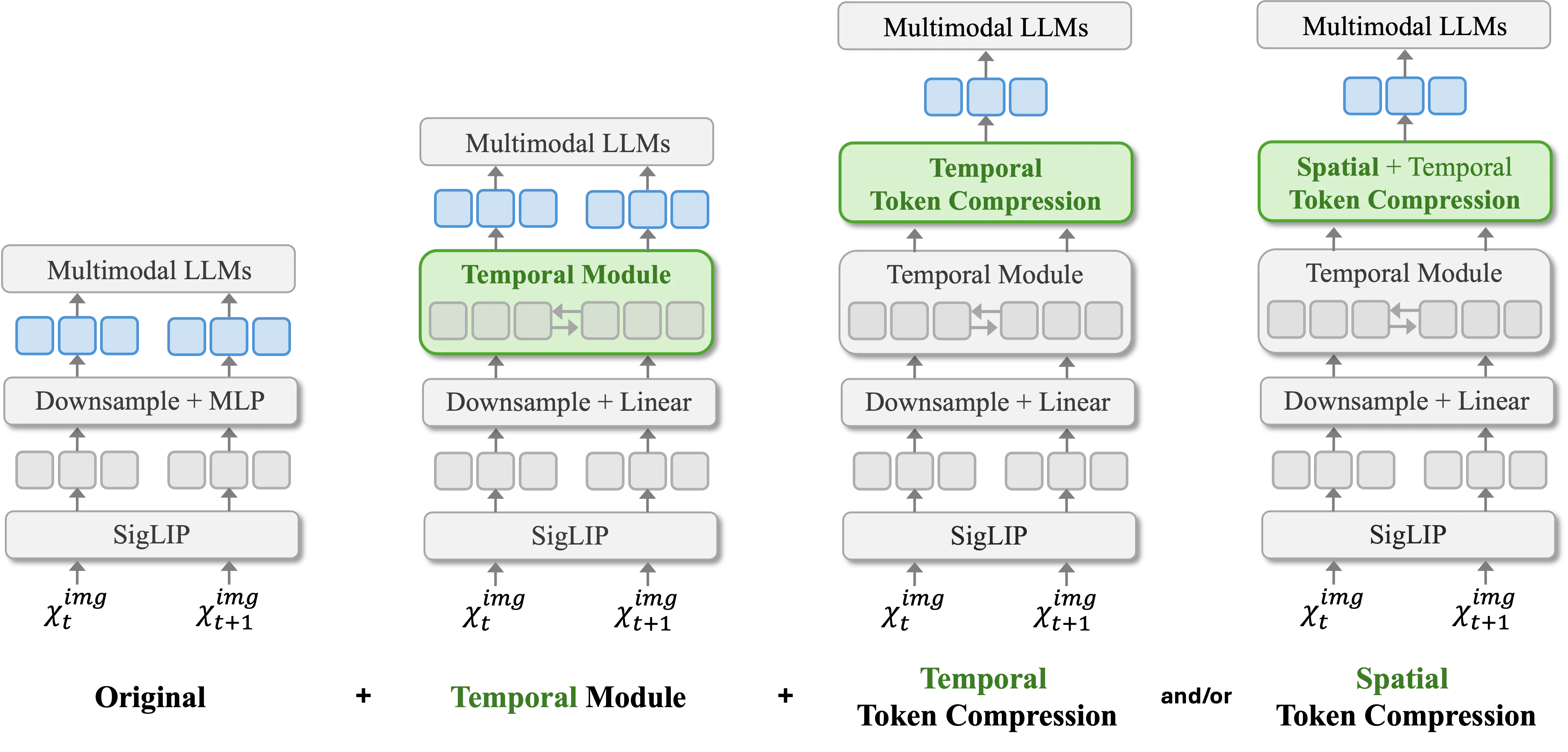
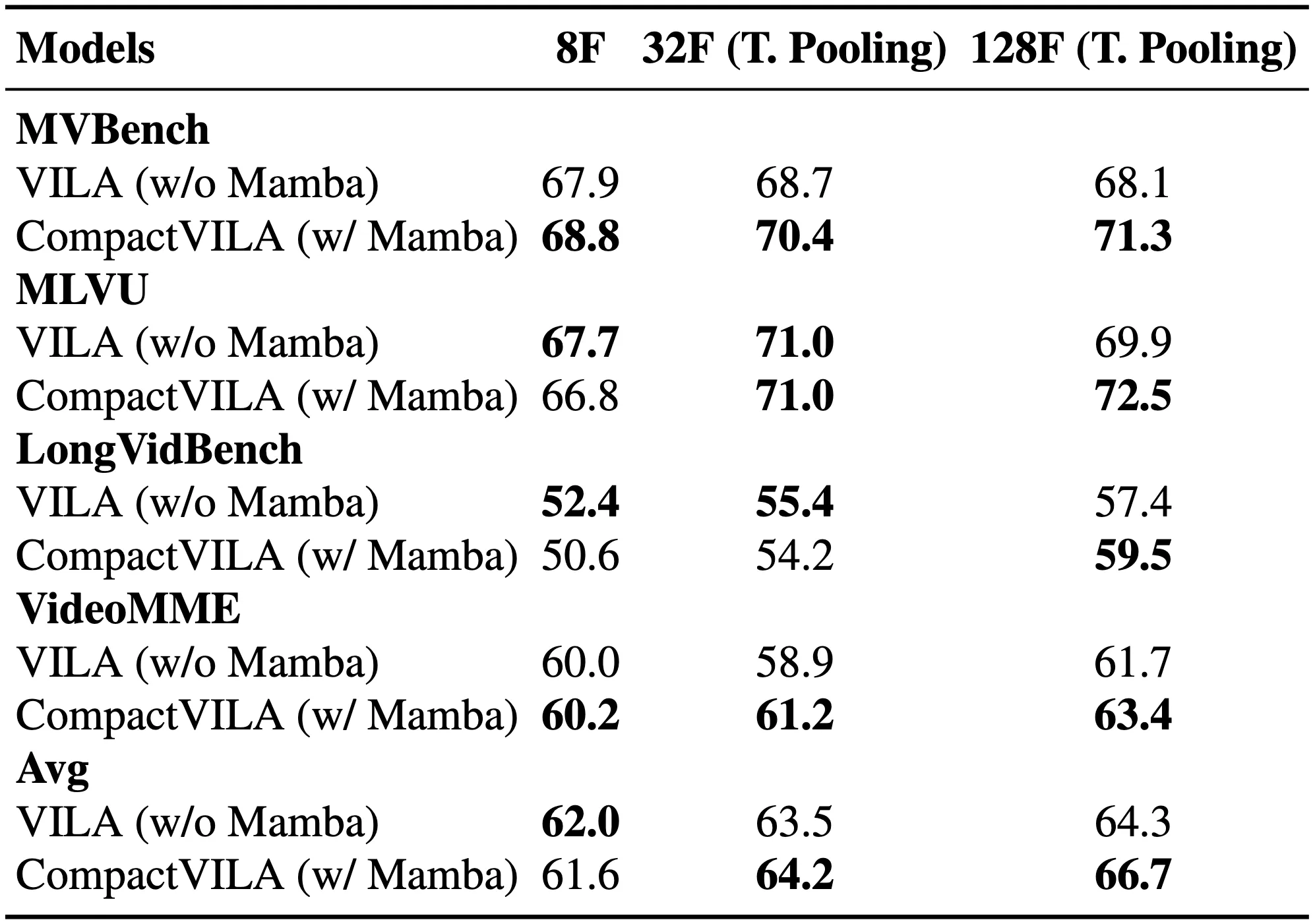
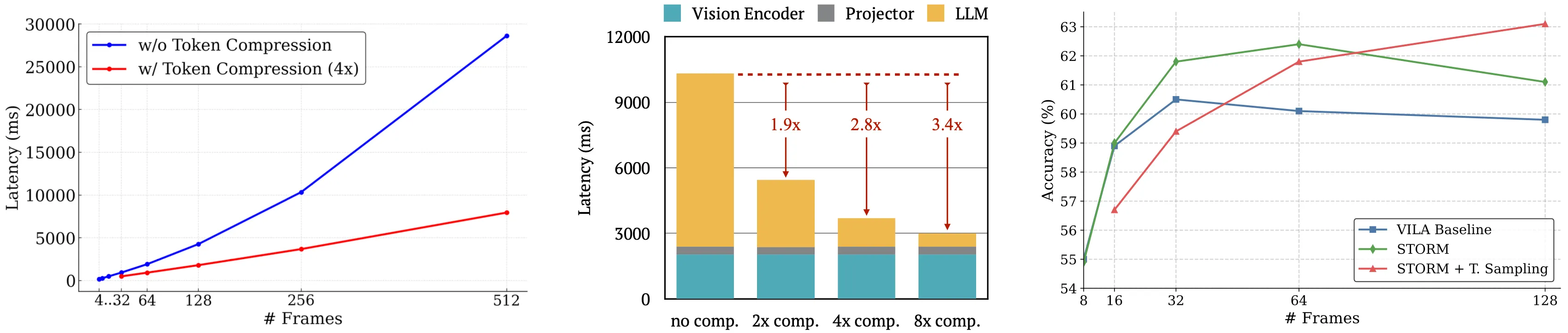
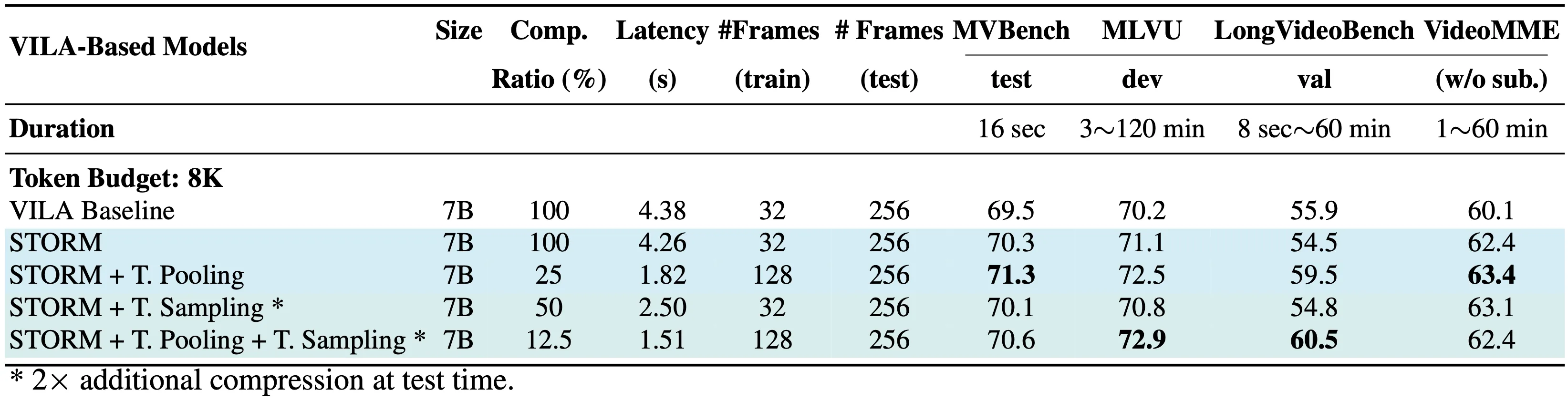
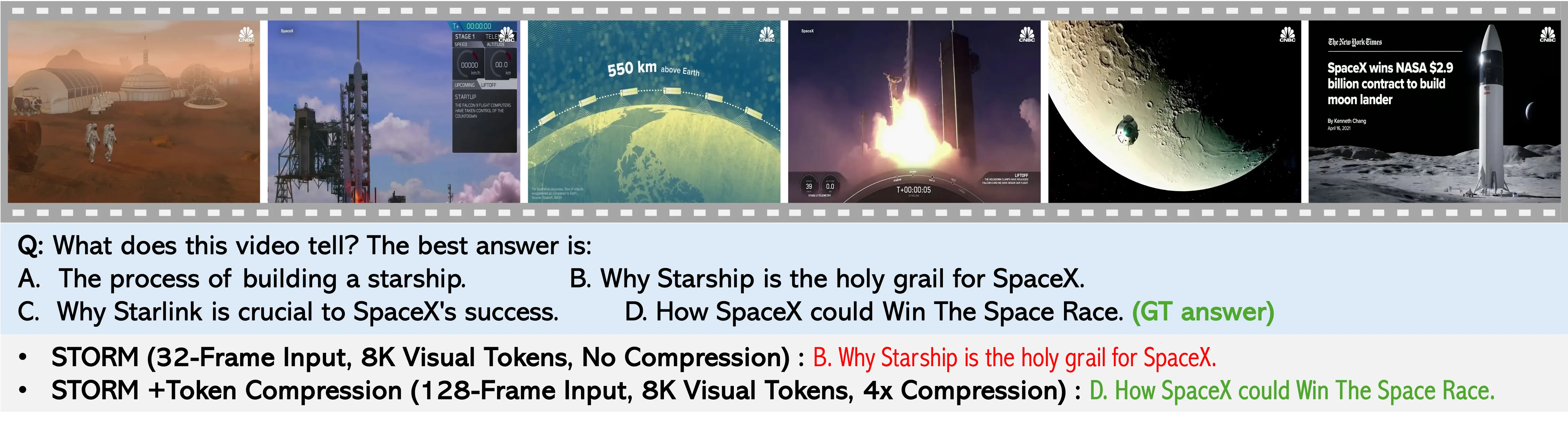
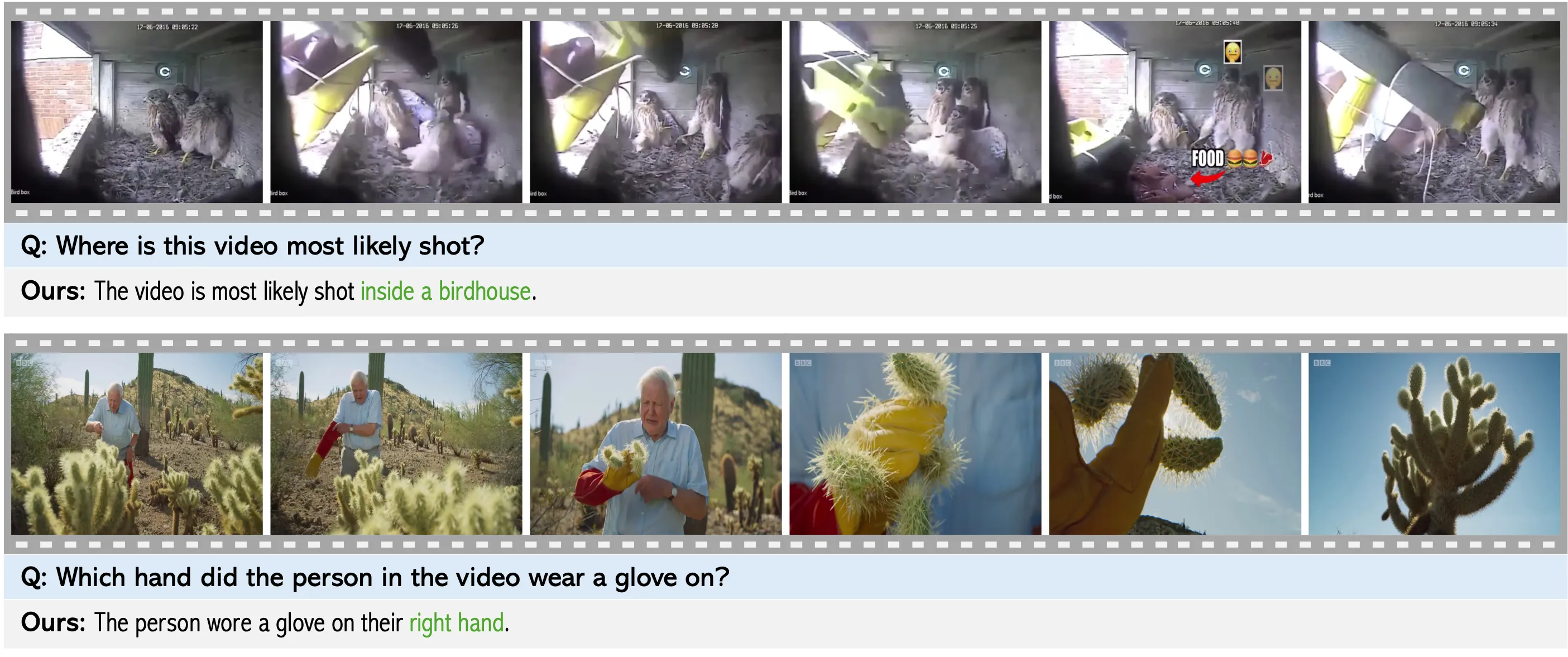
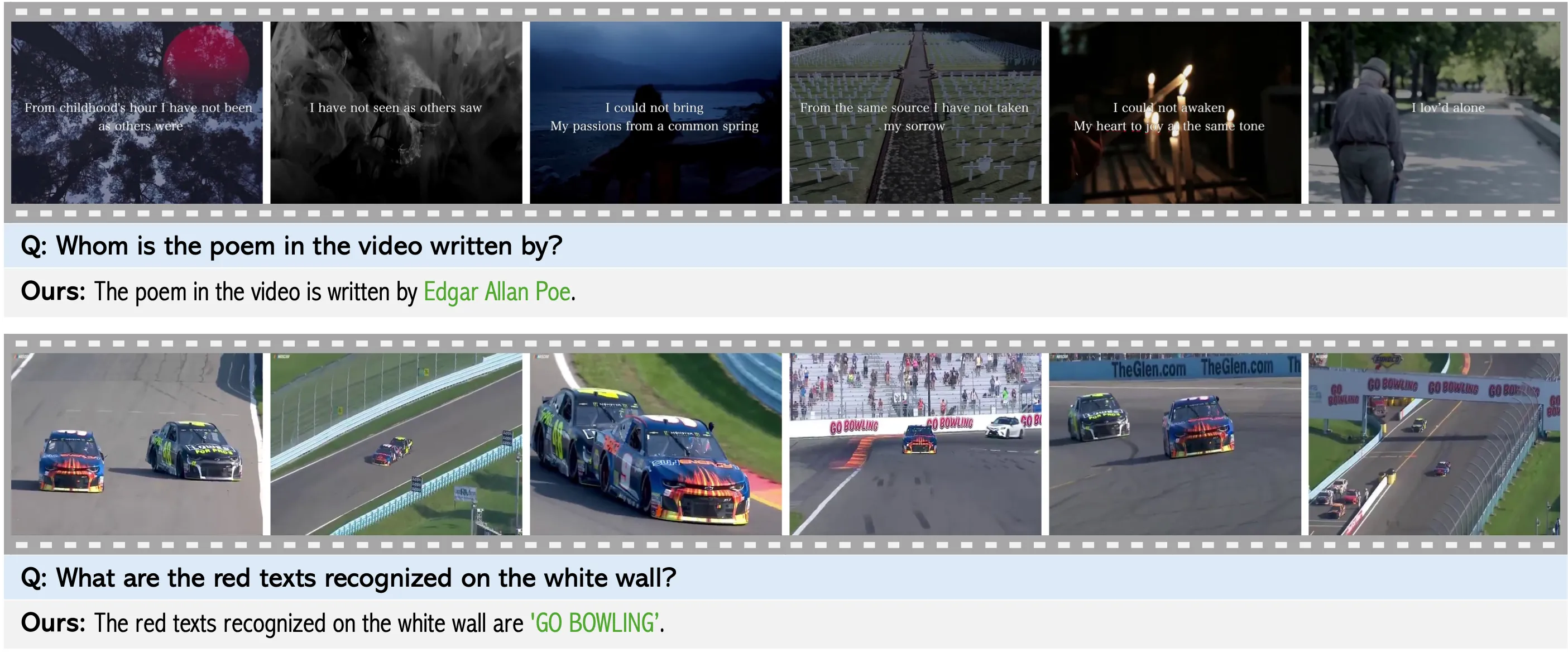
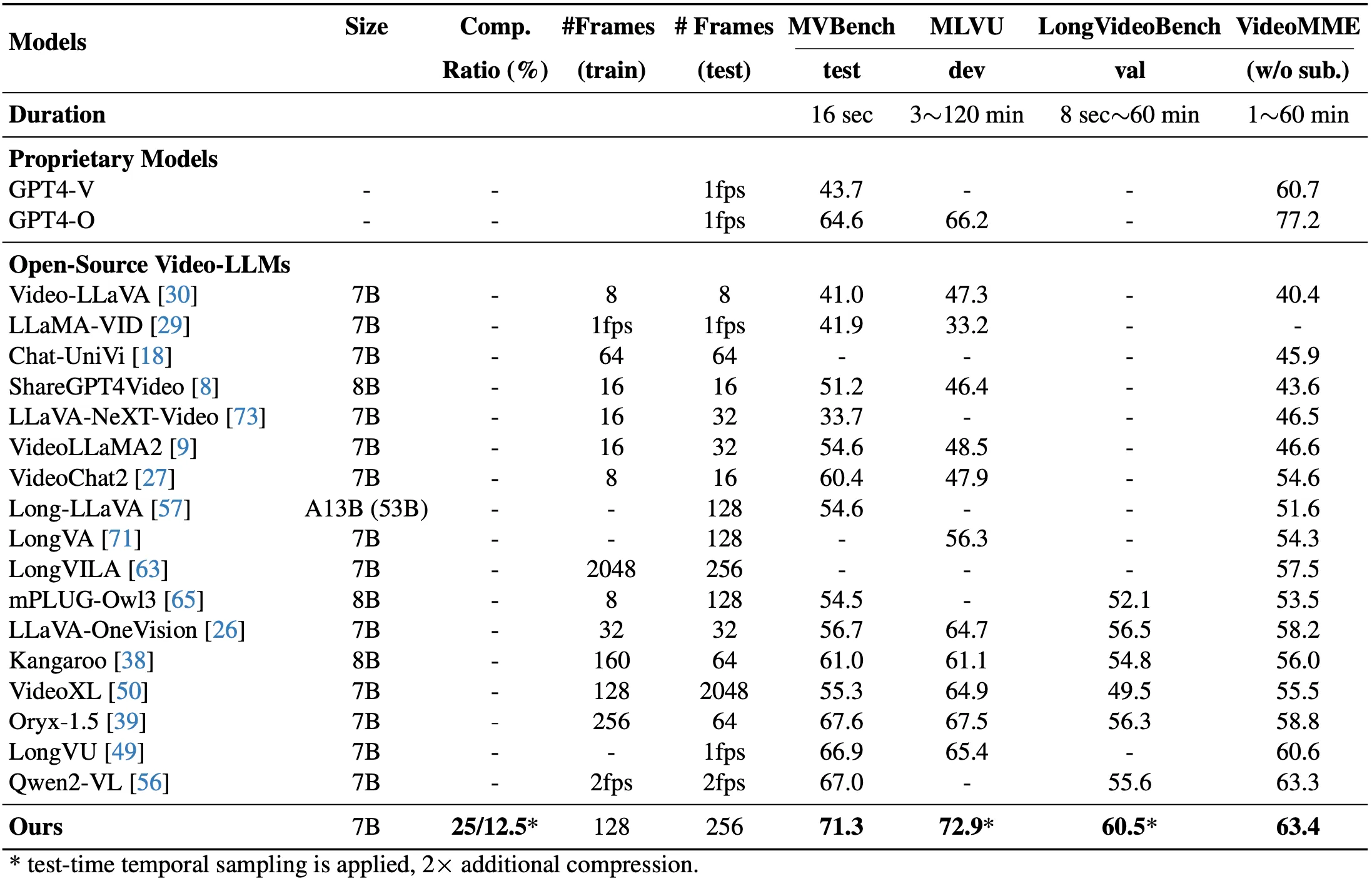
Solution: We STORM (Spatiotemporal TOken Reduction for Multimodal LLMs), which integrates a Mamba-Based Temporal Projector between the image encoder and the LLM to enrich the visual tokens with temporal dynamics. This enriched encoding brings two benefits: (1) It improves the model’s video reasoning capabilities by capturing temporal dynamics, and (2) By preserving critical dynamics across tokens, it inherently allows for efficient downstream token reduction, such as test-time sampling and training-based temporal and spatial pooling. Extensive experiments demonstrate that our approach enhances long-context reasoning and achieves state-of-the-art performance, reducing computational costs by up to for visual inputs.