
NVIDIA Nemotron 3 Super
Published:
Models Super Tech Report Nemotron 3 Blog
We are releasing NVIDIA Nemotron 3 Super, a 12B active 120B total parameter Mixture-of-Experts hybrid Mamba-Transformer model. Nemotron 3 Super is part of the Nemotron 3 series of models, and is the first model in the series that:
- Leverages LatentMoE for improved accuracy.
- Includes MTP layers for faster inference through native speculative decoding.
- Is Pretrained in NVFP4.
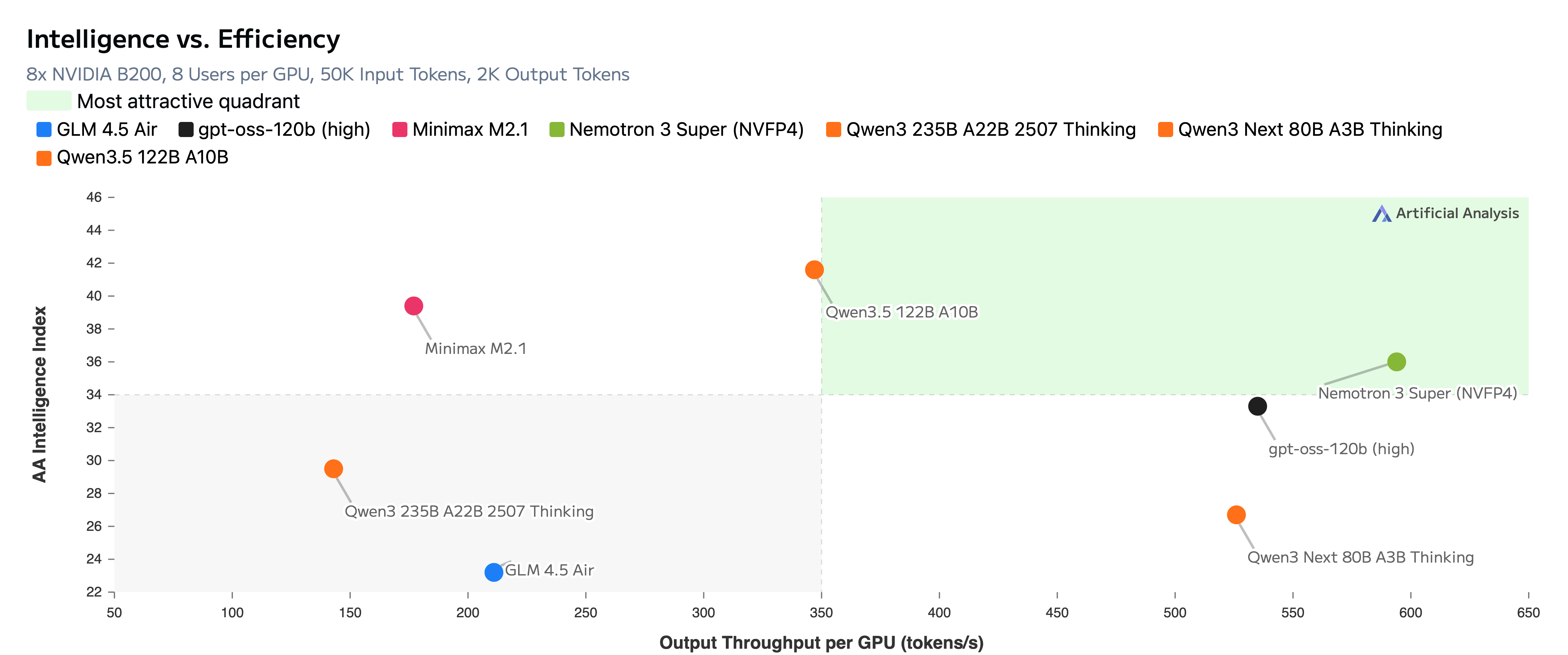
Key Highlights

- Nemotron 3 Super achieves upto 2.2x and 7.5x higher inference throughput than GPT-OSS-120B and Qwen3.5-122B, respectively, on the 8k token input / 16k token output setting.
- Nemotron 3 Super achieves higher or comparable accuracies to GPT-OSS-120B and Qwen3.5-122B across a diverse set of benchmarks.
- Supports context length of up to 1M tokens while outperforming both GPT-OSS-120B and Qwen3.5-122B on RULER at 1M context length.
Open Source
We are releasing the pre-trained, post-trained, and quantized checkpoints along with the datasets used for training.
Checkpoints:
- Nemotron 3 Super 120B-A12B NVFP4: post-trained and NVFP4 quantized model
- Nemotron 3 Super 120B-A12B FP8: post-trained and FP8 quantized model
- Nemotron 3 Super 120B-A12B BF16: post-trained model
- Nemotron 3 Super 120B-A12B Base BF16: base model
- Qwen3-Nemotron-235B-A22B-GenRM-2603: GenRM used for RLHF
Data:
- Nemotron-Pretraining-Specialized-v1.1: a collection of synthetic datasets aimed to improve LLM capabilities in code concepts and algorithms, formal logic, economics, and multiple choice questions.
- Nemotron-Super-Post-Training-Data: a collection of RL environments and SFT datasets targeting a broad range of agentic capabilities.
Model Recipes:
Tech Report
More technical details in the Tech Report