
Nemotron-Cascade: Scaling Cascaded Reinforcement Learning for General-Purpose Reasoning Models
Published:
Paper Model Weights 🤗 License
Author: Boxin Wang*, Chankyu Lee*, Nayeon Lee*, Sheng-Chieh Lin*, Wenliang Dai*, Yang Chen*, Yangyi Chen*, Zhuolin Yang*, Zihan Liu*, Mohammad Shoeybi, Bryan Catanzaro, Wei Ping*†
* Equal technical contribution, with author names ordered alphabetically by first name.
† Leads the effort.
Overview
Building general-purpose reasoning models with reinforcement learning (RL) entails substantial cross-domain heterogeneity, including large variation in verification latency and inference-time response lengths. Such variability complicates the RL infrastructure and slows training.
In this work, we scale up cascaded reinforcement learning (Cascade RL) to develop, Nemotron-Cascade, a family of general-purpose reasoning models. Departing from conventional approaches that blend heterogeneous prompts from different domains, Cascade RL orchestrates sequential, domain-wise RL, reducing engineering complexity and delivering state-of-the-art performance across a wide range of benchmarks.
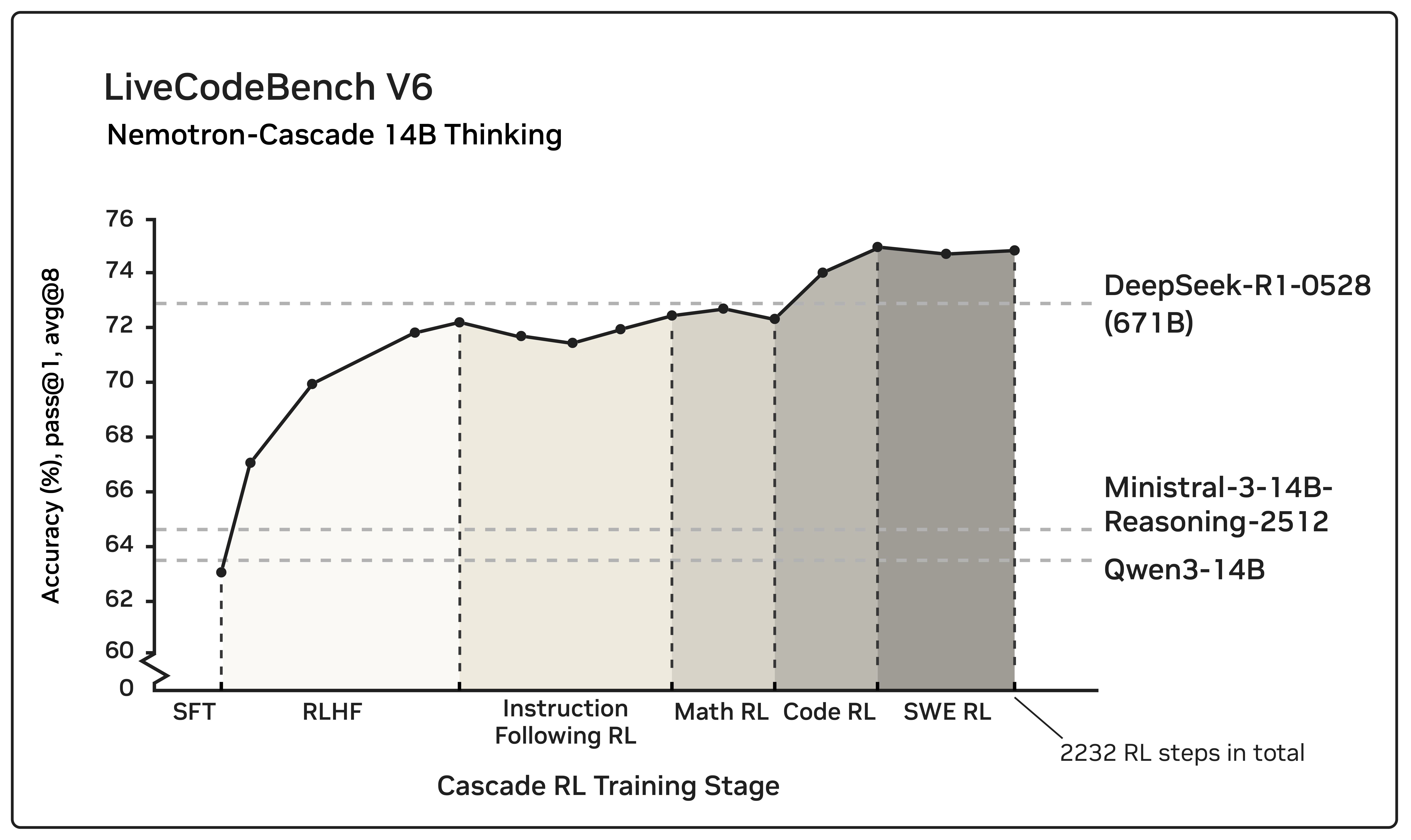
Notably, RLHF for alignment, when used as a pre-step, boosts the model’s complex reasoning ability far beyond mere preference optimization, and subsequent domain-wise RLVR stages rarely degrade the benchmark performance attained in earlier domains and may even improve it. See an illustration of the coding benchmark in the figure above. Our 14B model, after RL, outperforms its SFT teacher, DeepSeek-R1-0528, on LiveCodeBench v5/v6/Pro and achieves silver-medal performance in the 2025 International Olympiad in Informatics (IOI).
Highlights
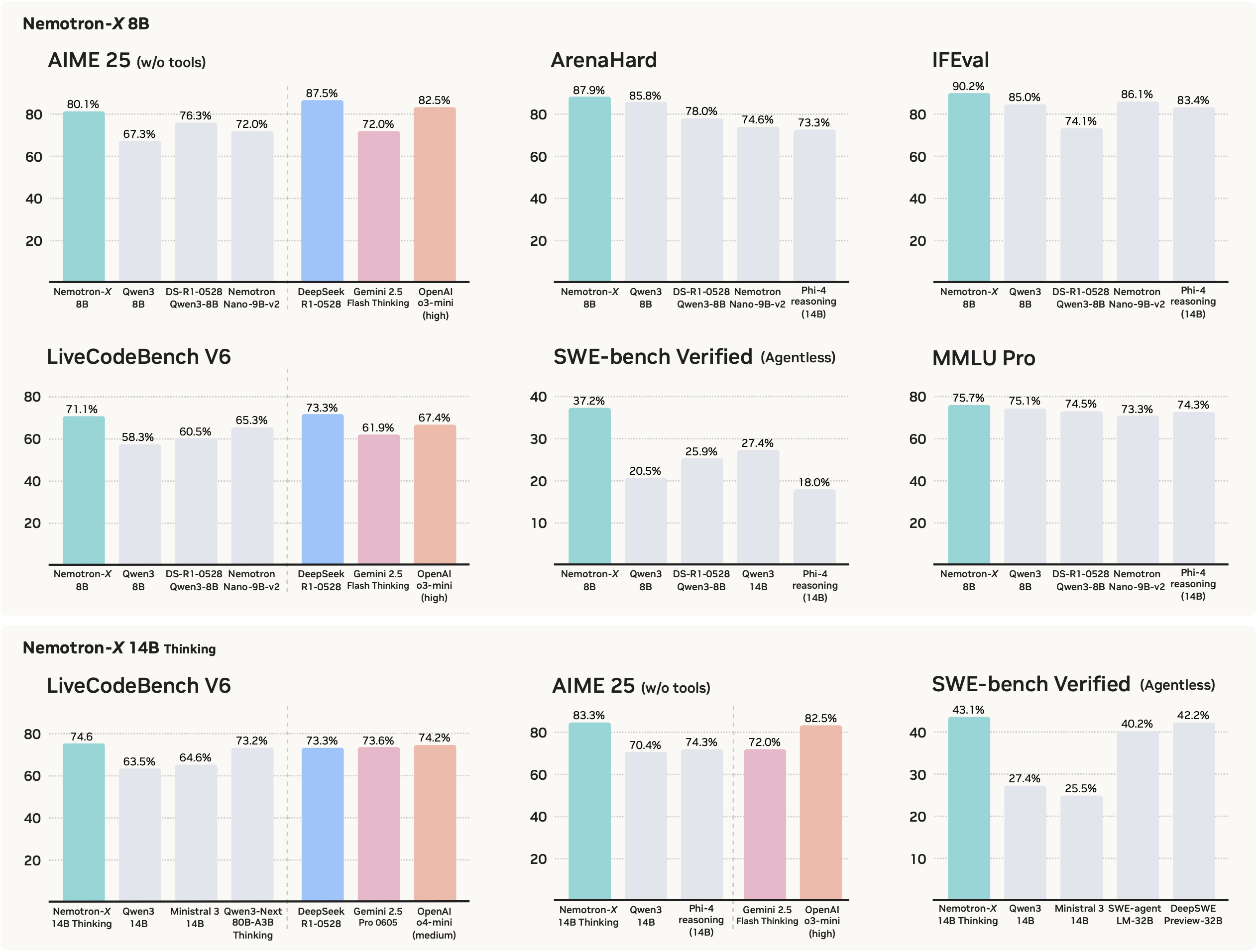
Main Results
-
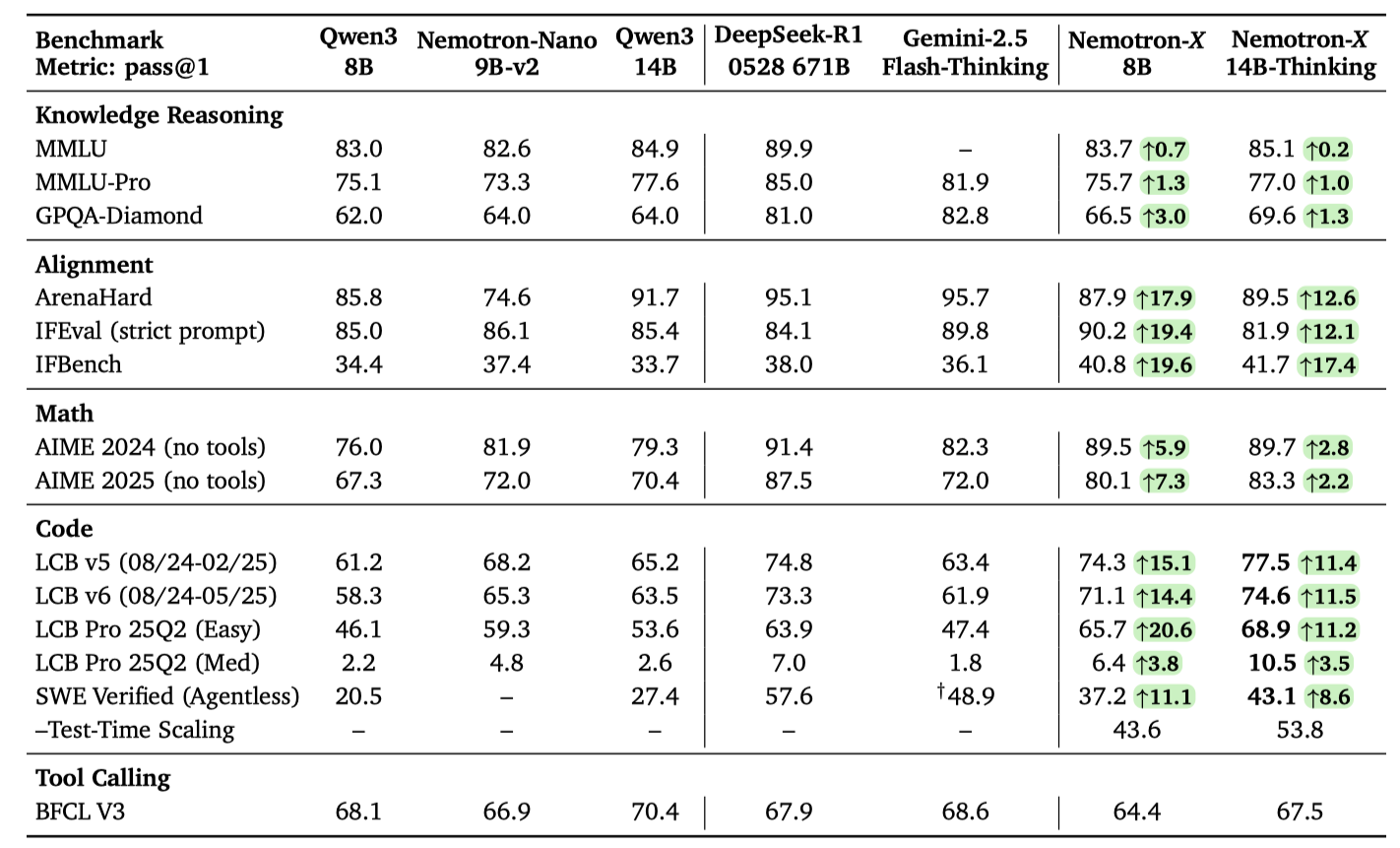
To demonstrate the effectiveness of Cascade RL, we compare the performance of Nemotron-Cascade models trained using Cascade RL with the performance of their initial SFT models. The $\uparrow$ number indicates the improvement achieved by applying the complete Cascade RL to initial SFT models.
-
Our Nemotron-Cascade-14B-Thinking achieves best-in-class performance across most benchmarks. Remarkably, Nemotron-Cascade-14B-Thinking surpasses DeepSeek-R1-0528 (671B) by a clear margin across all LCB v5, v6, and Pro benchmarks.
Technical Contributions
Here are the key technical highlights and contributions of our work:
- Cascade RL Framework: We propose a cascaded, domain-wise RL training paradigm as shown in Figure above: (SFT $\rightarrow$ RLHF $\rightarrow$ IF-RL $\rightarrow$ Math RL $\rightarrow$ Code RL $\rightarrow$ SWE RL). The training pipeline for Nemotron-Cascade begins with a multi-stage SFT phase to equip the model with foundational skills. Subsequently, Cascade RL is applied across multiple domains to further enhance the model’s performance in these areas. The proposed Cascade RL framework offers Instruction-Following Multi-Stage SFT RLHF Math RL RL notable advantages: i) RLHF substantially improves overall response quality (e.g., reduces verbosity), thereby enhancing reasoning performance; ii) subsequent domain-specific RL stages rarely degrade the benchmark performance attained in earlier domains and may even improve it, since RL is resistant to catastrophic forgetting; and iii) RL hyperparameters and training curriculum can be tailored to each specific domain for optimal performance.
- Best-in-class Performance: Nemotron-Cascade 8B/14B models trained using Cascade RL method achieve state-of-the-art, best-in-class performance across a broad range of benchmarks encompassing all these domains. For example, our Nemotron-Cascade-14B-Thinking, with a inference budget of 64K-token, outperforms Gemini-2.5-Pro-06-05, o4-mini (medium), Qwen3-235B-A22B (thinking mode), and DeepSeek-R1-0528 on the LiveCodeBench v5/v6 (Jain et al., 2024). It also achieves silver-medal performance on the 2025 International Olympiad in Informatics (IOI).
- Unified Reasoning Models: We develop Nemotron-Cascade-8B unified reasoning model that enable user control over thinking and nonthinking modes at each conversational turn. We challenge the assumption that LLMs, especially smaller ones, lack the capacity to learn effectively from both non-thinking and thinking data, and demonstrate that the reasoning performance gap between 8B unified model in thinking mode and a dedicated 8B thinking model can be closed.
Open Source
We release the full collection of models and training data.
Model checkpoints
- Nemotron-Cascade-8B: a powerful general-purpose 8B unified model post-trained using Cascade RL, capable of operating in both instruct and thinking modes.
- Nemotron-Cascade-8B-Thinking: a powerful general-purpose 8B model post-trained using Cascade RL, capable of operating in thinking mode.
- Nemotron-Cascade-14B-Thinking: a powerful general-purpose 14B model post-trained using Cascade RL, capable of operating in thinking mode.
Data
- Nemotron-Cascade SFT Stage-I Data: the data used for the SFT stage-I of our Cascade RL training pipeline.
- Nemotron-Cascade SFT Stage-II Data: the data used for the SFT stage-II of our Cascade RL training pipeline.
- Nemotron-Cascade SFT SWE Data: the data used for the SFT stage for SWE of our Cascade RL training pipeline.
- Nemotron-Cascade RLHF Data: the data used for the RLHF stage of our Cascade RL training pipeline.
- Nemotron-Cascade Instruction-Following-RL Data: the data used for the Instruction-Following RL stage of our Cascade RL training pipeline.
- Nemotron-Cascade Math RL Data: the data used for the Math RL stage of our Cascade RL training pipeline.
- Nemotron-Cascade SWE RL Data: the data used for the SWE RL stage of our Cascade RL training pipeline.
- Nemotron-Cascade Rewawrd Model Training Data: the data used to train the reward model for the RLHF stage of our Cascade RL training pipeline.
Citation
@article{NemotronCascade_Scaling_Cascaded_Reinforcement_Learning,
title={Nemotron-Cascade: Scaling Cascaded Reinforcement Learning for General-Purpose Reasoning Models},
author={Wang, Boxin and Lee, Chankyu and Lee, Nayeon and Lin, Sheng-Chieh and Dai, Wenliang and Chen, Yang and Chen, Yangyi and Yang, Zhuolin and Liu, Zihan and Shoeybi, Mohammad and Catanzaro, Bryan and Ping, Wei},
year={2025}
}