
Nemotron-Cascade 2: Post-Training LLMs with Cascade RL and Multi-Domain On-Policy Distillation
Published:
Paper Model Weights 🤗 License
Zhuolin Yang*, Zihan Liu*, Yang Chen*, Wenliang Dai*, Boxin Wang*, Sheng-Chieh Lin, Chankyu Lee, Yangyi Chen, Dongfu Jiang, Jiafan He, Renjie Pi, Grace Lam, Nayeon Lee, Alexander Bukharin, Mohammad Shoeybi, Bryan Catanzaro, Wei Ping*†
* Equal technical contribution, with authors listed in reverse alphabetical order by first name.
† Leads the effort.
Overview
We introduce Nemotron-Cascade 2, an open 30B MoE model with 3B activated parameters, built on the pretrained Nemotron-Nano-V3, that delivers best-in-class reasoning and strong agentic capabilities. Despite its compact size, its mathematical and coding reasoning performance approaches that of frontier open models. It is the second open-weight LLM, after DeepSeek-V3.2-Speciale-671B-A37B, to achieve Gold Medal-level 🏅 performance in the 2025 International Mathematical Olympiad (IMO), the International Olympiad in Informatics (IOI), and the ICPC World Finals, demonstrating remarkably high intelligence density with 20× fewer parameters.
In contrast to Nemotron-Cascade 1, the key technical advancements are as follows. After SFT on a meticulously curated dataset, we substantially expand Cascade RL to cover a much broader spectrum of reasoning and agentic domains. Furthermore, we introduce multi-domain on-policy distillation from the strongest intermediate teacher models for each domain throughout the Cascade RL process, allowing us to efficiently recover benchmark regressions and sustain strong performance gains along the way. We release the collection of model checkpoint and training data.
Highlights
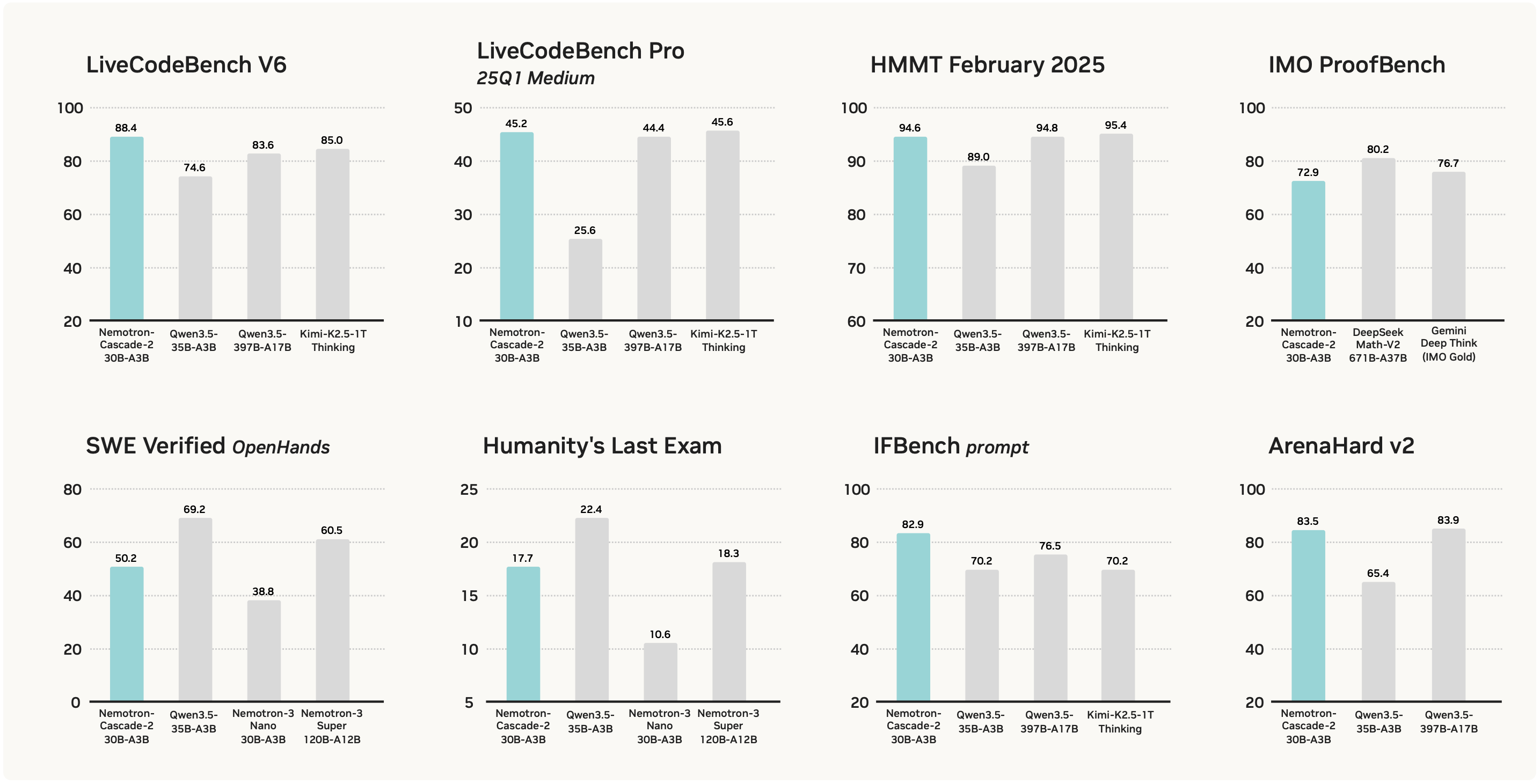
Main Results
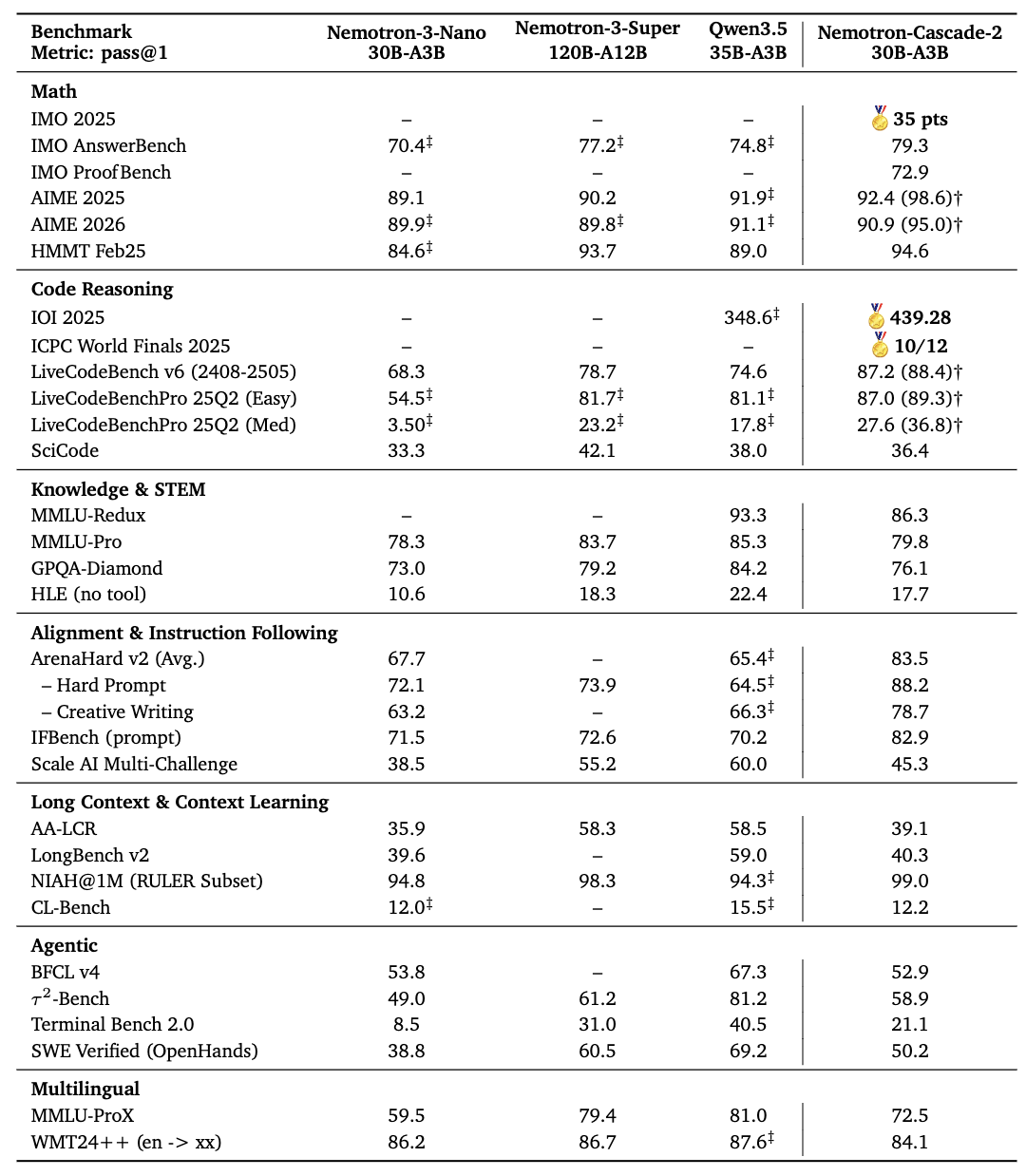
- Nemotron-Cascade-2-30B-A3B achieves gold-medal performance in both the IMO 2025 and IOI 2025, which demonstrate remarkably high intelligence density. One of our co-authors, who is an IMO 2015 gold medalist, reviewed and scored our model-generated solutions to verify this result.
- Nemotron-Cascade-2-30B-A3B is built on the Nemotron-Nano-V3 base model, and improves upon Nemotron-Nano-V3 on nearly every benchmark, demonstrating the effectiveness of our post-training recipe.
- Nemotron-Cascade-2-30B-A3B outperforms both the latest released Qwen3.5-35B-A3B (2026-02-24) and the larger Nemotron-3-Super-120B-A12B~(2026-03-11) on key benchmarks spanning mathematics, code reasoning, alignment, and instruction following.
Technical Contributions
Here are the key technical highlights and contributions of our work:
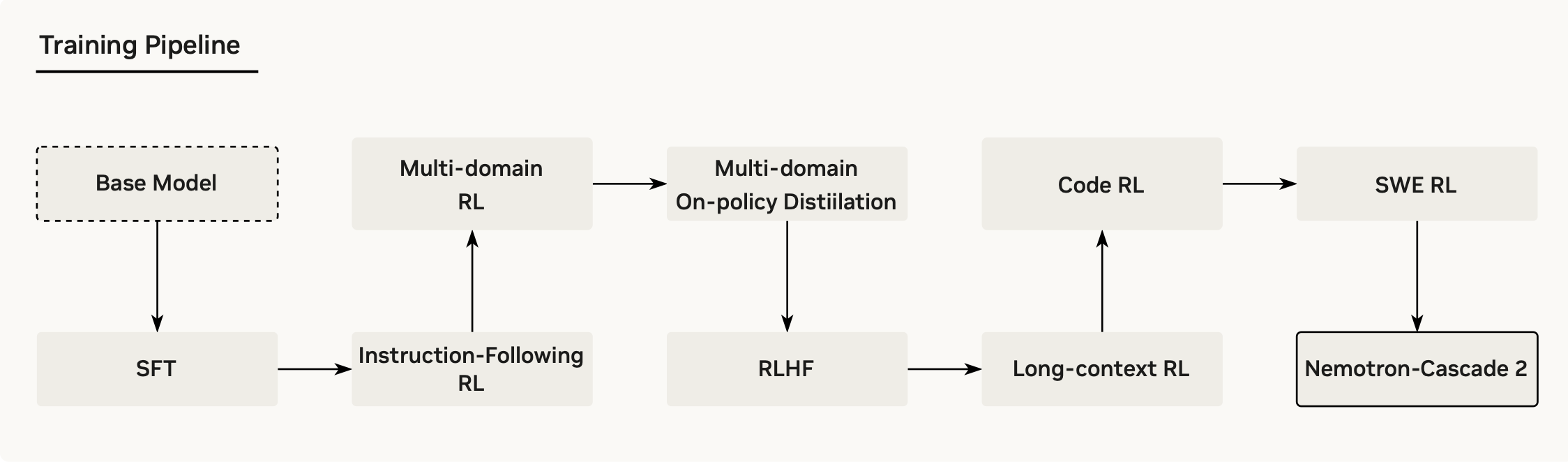
- Cascade RL Framework: Similar to its predecessor, Nemotron-Cascade 2 further scales Cascade RL on high-priority domains to preserve the benefits of domain-wise training, enabling us to push the limits of reasoning performance in key domains to state-of-the-art levels.
- Multi-domain On-policy Distillation: We incorporate on-policy distillation as an intermediate stage within Cascade RL. This process distills knowledge from the best-performing teacher models obtained during different stages of Cascade RL training for each specific domain. By leveraging these intermediate teachers, the model can effectively recover benchmark regressions that may arise when training in increasingly complex RL environments, while preserving strong performance across previously optimized domains.
Open Source
We release the full collection of models and training data.
Model checkpoints
- Nemotron-Cascade-2-30B-A3B: an open 30B Mixture-of-Experts (MoE) model with only 3B activated parameters post-trained using Cascade RL, capable of operating in both instruct and thinking modes.
Data
- Nemotron-Cascade-2 SFT Data: the data used for the SFT stage of Nemotron-Cascade-2 training pipeline.
- Nemotron-Cascade-2 RL Data: the data used for our Nemotron-Cascade 2 RL training pipeline.
Citation
@article{Nemotron_Cascade_2,
title={Nemotron-Cascade 2: Post-Training LLMs with Cascade RL and Multi-Domain On-Policy Distillation},
author={Yang, Zhuolin and Liu, Zihan and Chen, Yang and Dai, Wenliang and Wang, Boxin and Lin, Sheng-Chieh and Lee, Chankyu and Chen, Yangyi and Jiang, Dongfu and He, Jiafan and Pi, Renjie and Lam, Grace and Lee, Nayeon and Bukharin, Alexander and Shoeybi, Mohammad and Catanzaro, Bryan and Ping, Wei},
year={2026}
}