
Enable NVFP4 Inference for Nemotron with Quantization-Aware Distillation
Published:
QAD Tech Report
Nemotron-3-Nano-30B-A3B-NVFP4 Model Card
Authors of this blog: NVIDIA Nemotron team & ModelOpt team
Nemotron 3 Nano NVFP4
Nemotron 3 Nano is a 30B-A3B hybrid MoE model of the Nemotron 3 family, initially released in BF16 and FP8 precisions. We just released the NVFP4 version of Nemotron 3 Nano. Unlike GPT-OSS MXFP4, which only has weights quantized, Nemotron 3 Nano NVFP4 has both weights and activation quantized, enabling a further 2x FLOPS utilization on Blackwell Tensor Core.
NVFP4, trained with Quantization-aware distillation (QAD), achieves close-to-BF16 accuracy across various benchmarks as shown in the following plot. For details, please refer to the Model Card.
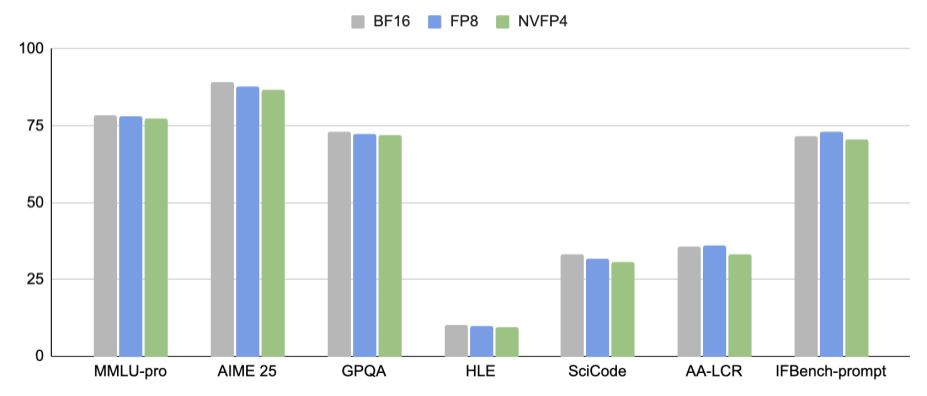
On Blackwell, NVFP4 enables 4x FLOPS over BF16. In addition, NVFP4 brings about 1.7x memory saving over FP8, making Nemotron 3 Nano an appealing choice for local deployment on consumer GPUs such as RTX 5090.
Quantization-aware distillation (QAD)
Nemotron 3 Nano and earlier generations of Nemotron Nano are trained with quantization-aware distillation (QAD). QAD starts from the original high-precision (BF16) model as a frozen teacher, and trains an NVFP4-quantized student to match the teacher’s output distribution. Concretely, instead of learning from hard labels, the student learns from the teacher’s soft targets by minimizing KL divergence between teacher and student logits.
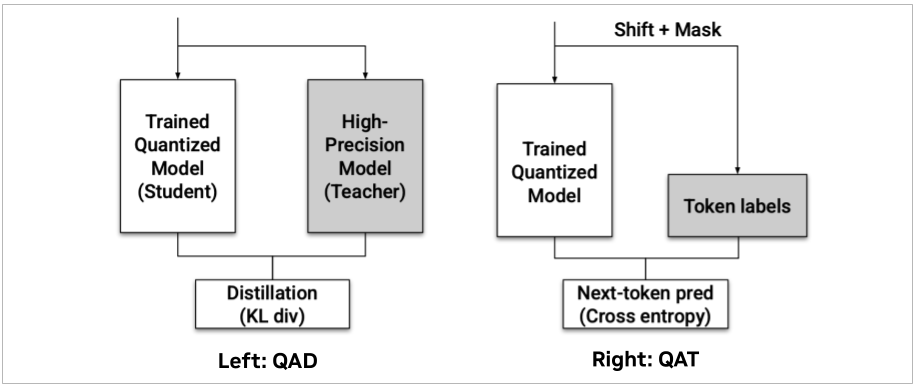
QAD is designed to address practical issues with post-training quantization (PTQ) and quantization-aware training (QAT) for modern LLMs. PTQ is simple as it requires no training, but for small models the accuracy drop can be non-negligible. QAT can often recover accuracy, but it typically reuses the task loss (e.g., next-token cross-entropy) and implicitly requires going through multi-stage post-training pipelines (SFT, RL, model merging), which requires significant engineering effort and produces unstable results.
In contrast, QAD directly aligns the NVFP4 student back to the original BF16 teacher distribution, avoiding “re-learning” with task loss and making it much easier to apply as a single post-training stage. QAD consistently recovers NVFP4 checkpoints to near-BF16 accuracy.
Resources
- NVIDIA-Nemotron-3-Nano-30B-A3B-NVFP4 will be available at inference service providers, including Baseten, and Deep Infra.
- Hugging Face NVFP4 checkpoints:
- QAD code examples:
Citation
@article{quantizationawaredistillation2026nvidia,
title={Quantization-Aware Distillation for NVFP4 Inference Accuracy Recovery},
author={NVIDIA},
year={2026}
}