Our method provides a unified approach for generating 4D dynamic content from a text prompt with diffuion guidance, supporting both unconstrained generation and controllable generation, where appearance is defined by one or multiple images.
Adopting a two-stage approach, Dream-in-4D first utilizes 3D and 2D diffusion guidance to learn a static 3D asset based on the provided text prompt. Then, it optimizes a deformation field using video diffusion guidance to model the motion described in the text prompt. Featuring a motion-disentangled D-NeRF representation, our method freezes the pre-trained static canonical asset while optimizing for the motion, achieving high quality view-consistent 4D dynamic content with realistic motion.
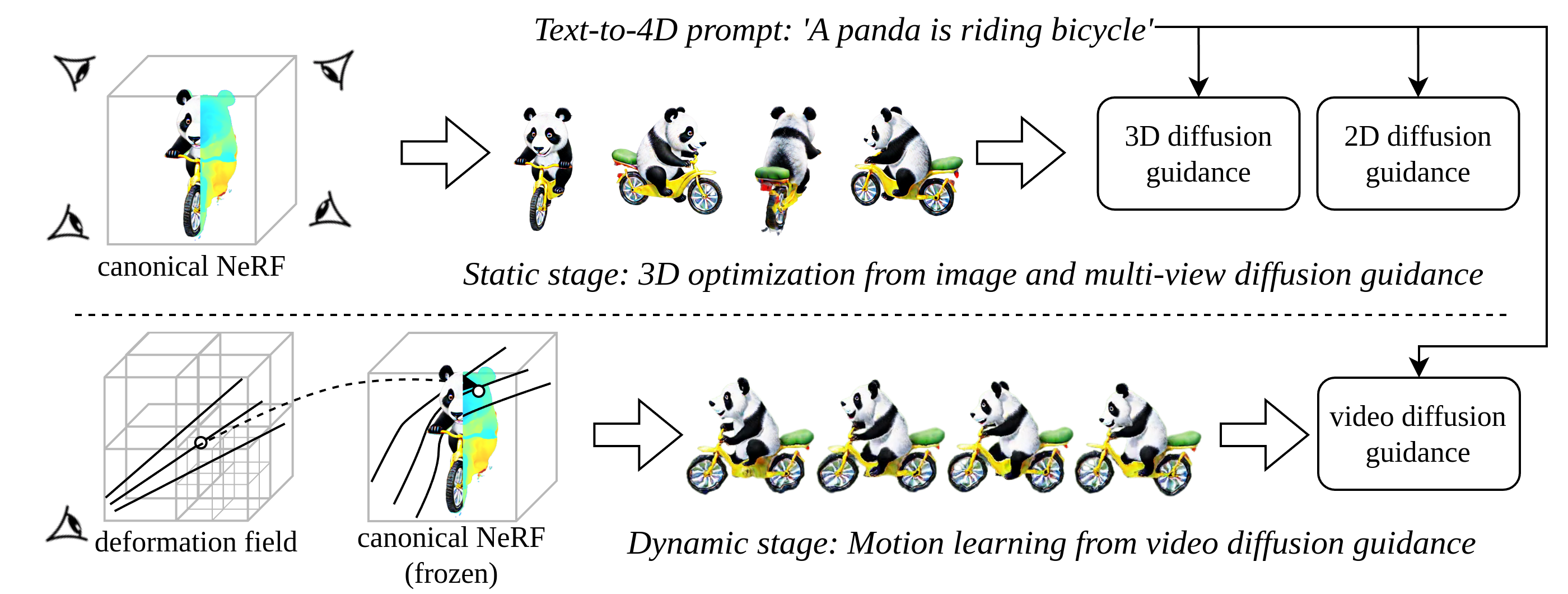
Dream-in-4D generates dynamic 3D scenes given a text prompt. We mainly use Zeroscope video diffusion model for our experiments, but our method works with other video diffusion models too (see results with Modelscope).
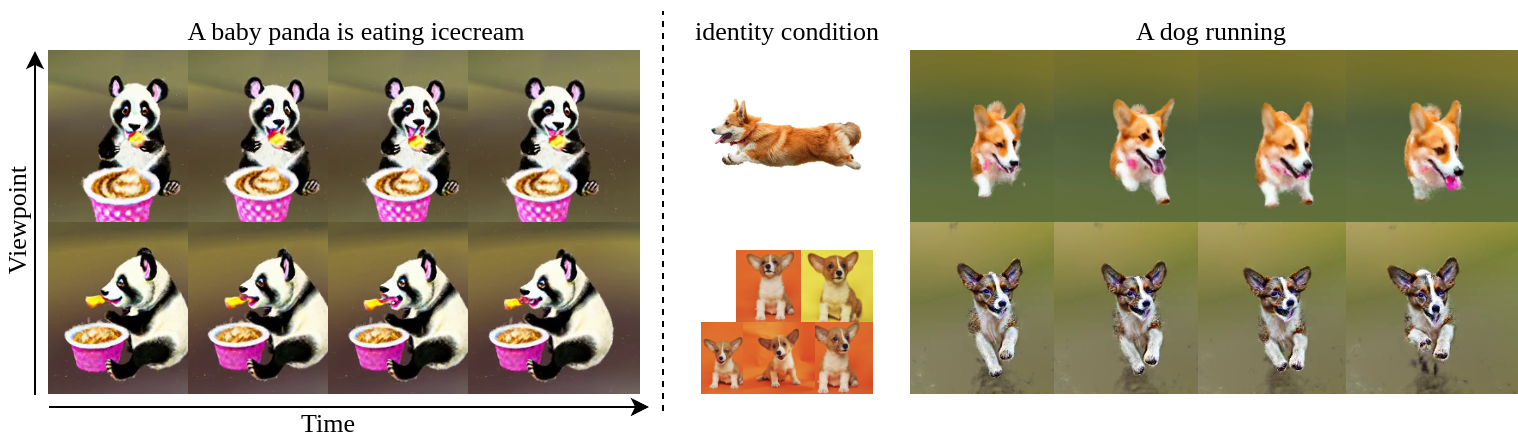
Dream-in-4D can control the object appearance with an input image. This is achieved by performing image-to-3D reconstruction in the static stage, and then animating the learned model in the dynamic stage.



Dream-in-4D can be personalized given 4-6 casually captured images of a subject.
We finetune StableDiffusion with Dreambooth, and use it together with MVDream to reconstruct a personalized static model (static stage), which we animate with video diffusion guidance (dynamic stage).
Hexplane representation leads to lower 3D asset quality in the dynamic stage. W/o 2D diffusion prior, the static stage fails to learn correct appearances or layouts. W/o deformation regularization loss, the learned motion is noisy. W/o multi-resolution features for the deformation field, the model fails to learn detailed motions.
Hexplane
w/o 2D diffusion prior
w/o deformation reg.
w/o multi-res. features
Ours
Clown fish swimming through the coral reef.
@InProceedings{zheng2024unified,
title = {A Unified Approach for Text- and Image-guided 4D Scene Generation},
author = {Yufeng Zheng and Xueting Li and Koki Nagano and Sifei Liu and Otmar Hilliges and Shalini De Mello},
booktitle = {CVPR},
year = {2024}
}