Abstract
We present a one-shot method to infer and render a photorealistic 3D representation from a single unposed image (e.g., face portrait) in real-time. Given a single RGB input, our image encoder directly predicts a canonical triplane representation of a neural radiance field for 3D-aware novel view synthesis via volume rendering. Our method is fast (24 fps) on consumer hardware, and produces higher quality results than strong GAN-inversion baselines that require test-time optimization. To train our triplane encoder pipeline, we use only synthetic data, showing how to distill the knowledge from a pretrained 3D GAN into a feedforward encoder. Technical contributions include a Vision Transformer-based triplane encoder, a camera data augmentation strategy, and a well-designed loss function for synthetic data training. We benchmark against the state-of-the-art methods, demonstrating significant improvements in robustness and image quality in challenging real-world settings. We showcase our results on portraits of faces (FFHQ) and cats (AFHQ), but our algorithm can also be applied in the future to other categories with a 3D-aware image generator.
For business inquiries, please visit our website and submit the form: NVIDIA Research Licensing.
Links

Results
One-shot Real-Time Novel View Synthesis
Given a single unposed RGB portrait, our method infer and render a photorealistic 3D representation in real-time. Our method runs at 24 fps on a consumer desktop and produces higher quality results than GAN-inversion baselines that run 1000x slower. While our model is trained only using synthetic data generated by EG3D, surprisingly, our encoder-based method works well “out of the box” on out-of-domain images (e.g., makeup, accessories, and even hand-drawn portraits).
Desktop Live Demo
Our method can be applied to a video by processing frames independently. Here, we lift a mobile phone RGB video to 3D in real-time. Our model is person-agnostic and can lift the image to 3D without any person-specific training or tuning.
3D Talking Head
When our method is combined with a 2D talking-head generator (e.g., face-vid2vid), our model can be used to create a 3D talking head. Given a 2D portrait generated by a user (e.g., by StyleGAN2), our method can be used to lift a 2D talking-head video to 3D.
Methodology
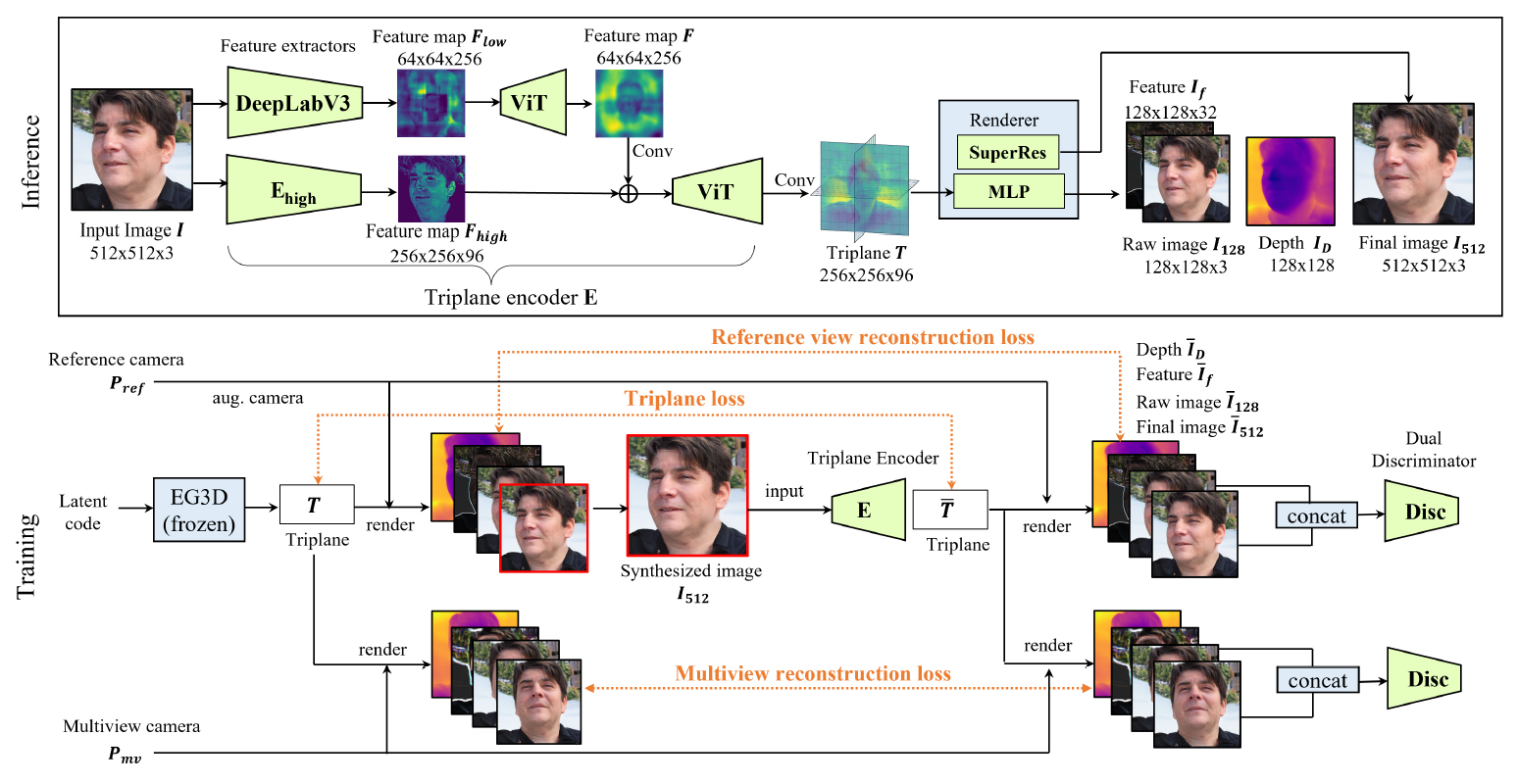
Figure 1: Overview of our encoder architecture and training pipeline for our proposed method.
Our method directly predicts a canonical triplane representation for volume rendering conditioned on an unposed RGB image. We found the architecture of the encoder to be integral to the performance of our model and propose to incorporate Vision-Transformer (ViT) layers to allow the model to learn highly-variable and complex correspondences between 2D pixels and the 3D representation. We use strictly synthetic data to train our model, but find that generalization in-the-wild requires sampling geometric camera parameters from distributions (instead of keeping them constant as in EG3D) in order to better align the synthetic data to the real world. We provide videos to demonstrate the importance of these design decisions.
ViT-Based Encoder
Without ViT layers, our method cannot capture the details of the subject, but retains the ability to predict a coherent 3D representation. * indicates the same training time.
Sampling Geometric Camera Parameters
Without sampling the focal length, principal point, and camera roll, our method cannot generalize to real images, instead predicting incorrect geometries and unrealistic images. * indicates the same training time.
Comparisons
We compare to the state-of-the-art methods on 3D reconstruction from a single portrait, comparing novel-view images and predicted geometry. Our method produces more faithful images and more detailed geometry.
Single-Image Results
Geometry Visualization
We provide an interactive geometry viewer. In the left column is the input image, and in the right is the pixel-aligned rendering and geometry from a novel view. Drag the separator to see the pixel-aligned geometry.












Additional Video Results on FFHQ and AFHQ
We include additional results for single-image inversion on FFHQ and AFHQ.
Lifting Stylized Images to 3D
We showcase lifting StyleGAN2-generated stylized images using our method. While never trained on stylized images, our method can surprisingly well handle paintings and drawings of human faces.
Frame-by-Frame Results on a Video
We apply our method frame-by-frame on an RGB video of a subject talking, showing high temporal consistency despite our method being applied independently per-frame.
Citation
@inproceedings{trevithick2023,
author = {Alex Trevithick and Matthew Chan and Michael Stengel and Eric R. Chan and Chao Liu and Zhiding Yu and Sameh Khamis and Manmohan Chandraker and Ravi Ramamoorthi and Koki Nagano},
title = {Real-Time Radiance Fields for Single-Image Portrait View Synthesis},
booktitle = {ACM Transactions on Graphics (SIGGRAPH)},
year = {2023}
}Acknowledgments
We thank David Luebke, Jan Kautz, Peter Shirley, Alex Evans, Towaki Takikawa, Ekta Prashnani and Aaron Lefohn for feedback on drafts and early discussions. We also thank Elys Muda for allowing use of the video. We acknowledge the significant efforts and suggestions of the reviewers. This work was funded in part at UCSD by ONR grants N000142012529, N000142312526, an NSF graduate research fellowship, a Jacobs Fellowship, and the Ronald L. Graham chair. Manmohan Chandraker acknowledges support of NSF IIS 2110409. Koki Nagano and Eric Chan were partially supported by DARPA’s Semantic Forensics (SemaFor) contract (HR0011-20-3-0005). The views and conclusions contained in this document are those of the authors and should not be interpreted as representing the official policies, either expressed or implied, of the U.S. Government. Distribution Statement ''A'' (Approved for Public Release, Distribution Unlimited). We base this website off of the StyleGAN3 website template.