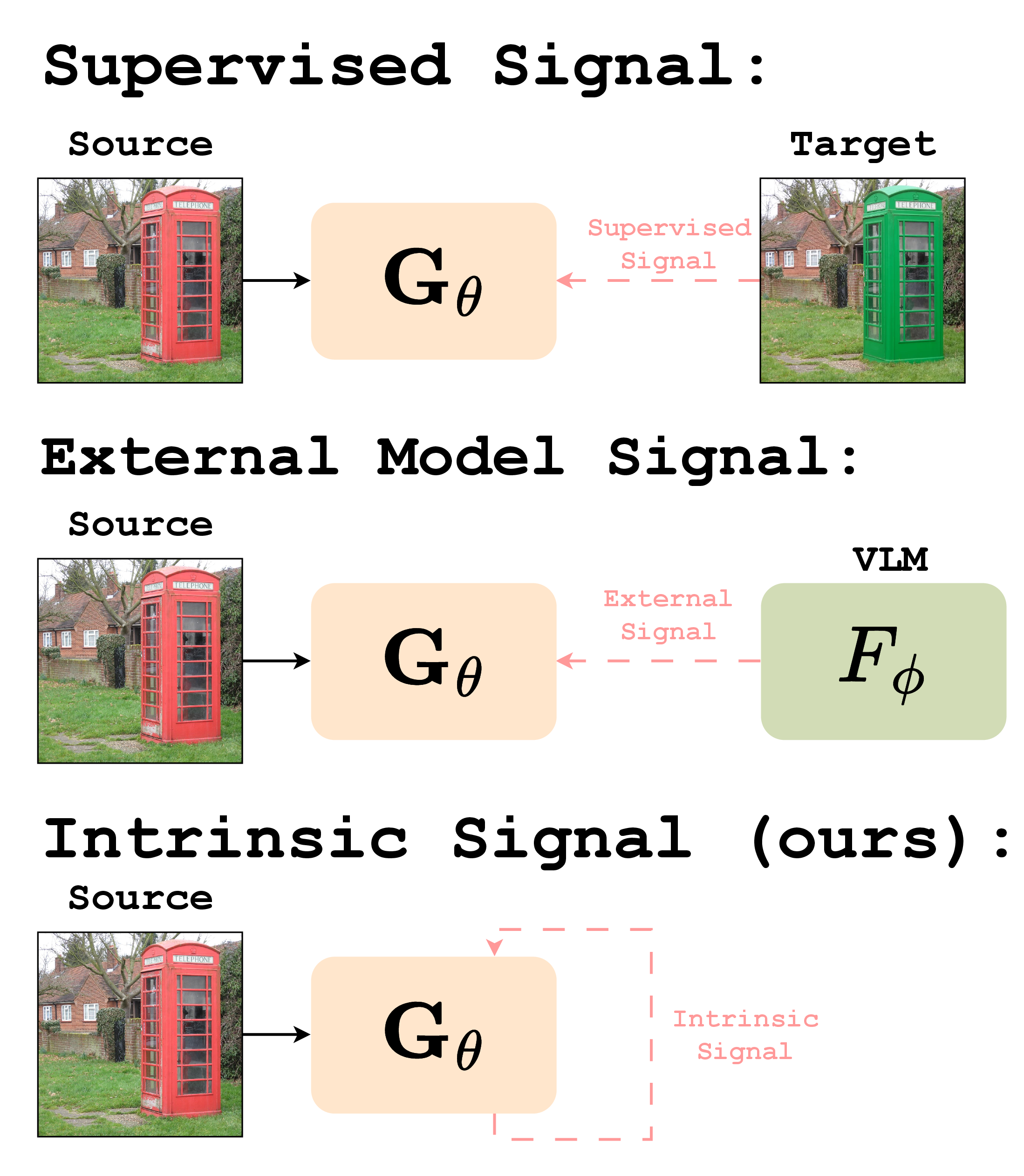




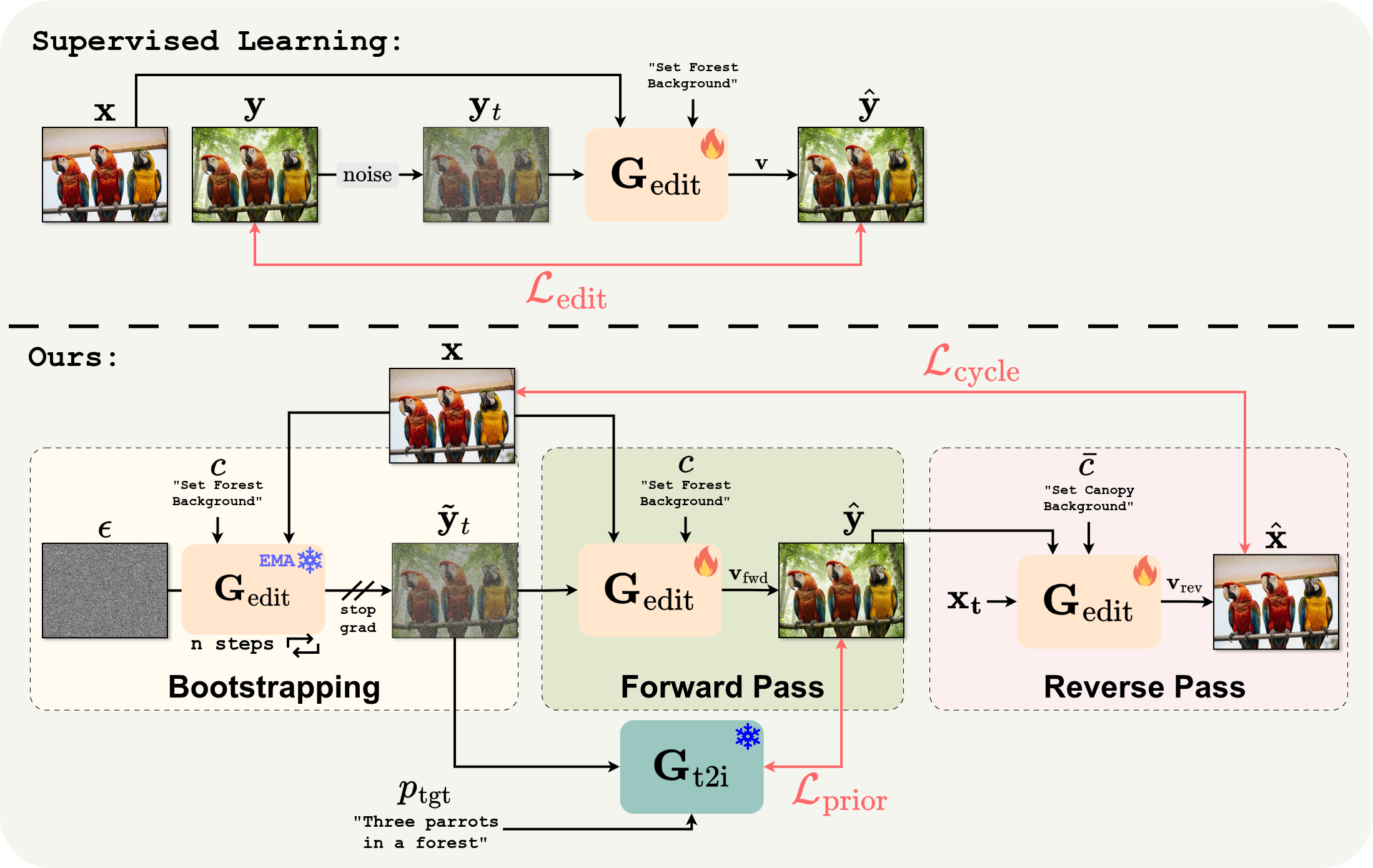
We evaluate on six unusual stylization targets not represented in common editing benchmarks: GTA V, Minecraft, American comic, low-poly 3D, voxel, and Lego. Our method is not trained on any of these styles, yet it outperforms supervised baselines (FLUX-Kontext, Qwen-Image-Edit) trained on millions of paired edits.




















