Fast 4D Mesh Generation
Speed comparison between ours and ActionMesh, with both methods aligned to the same anchor mesh. Our method finishes 4D mesh generation in ~9 s, while ActionMesh requires ~120 s for the same input — a ~13× speed‑up. Click Run simulation to play the comparison in real time.
Abstract
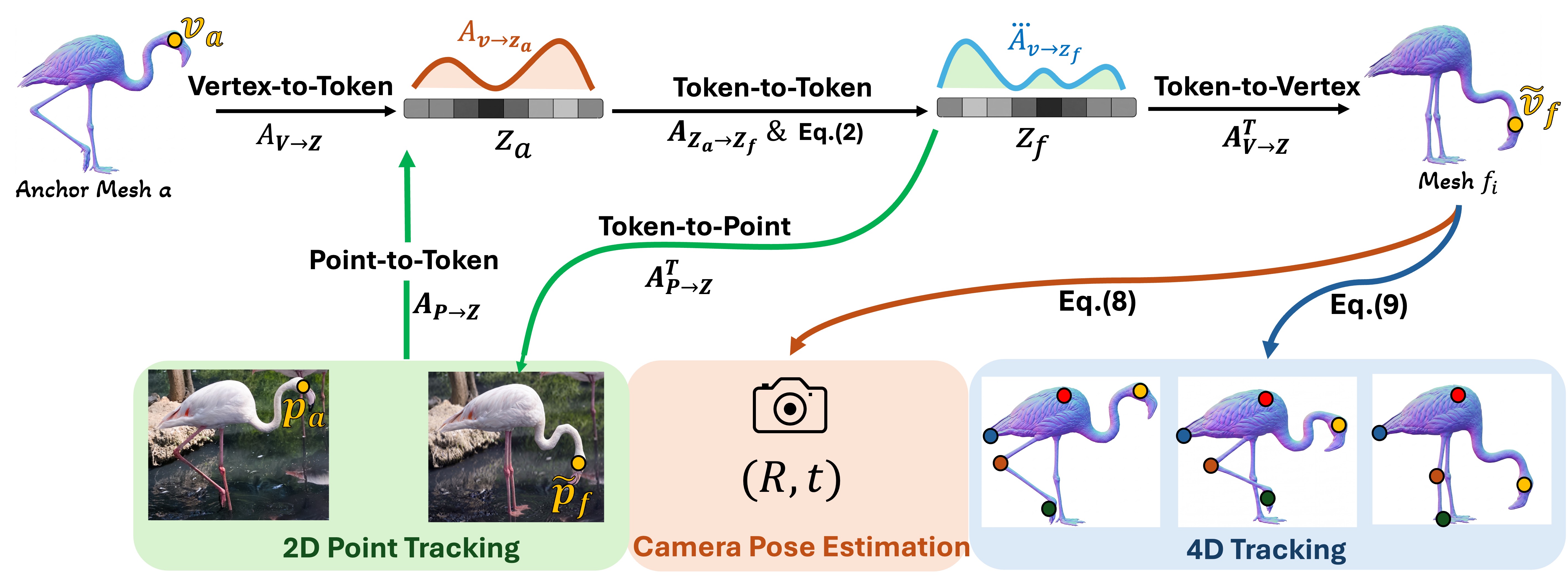
4D mesh generation has recently emerged as a powerful paradigm for recovering dynamic 3D structure from videos, but existing methods remain slow, computationally expensive, and difficult to scale to longer sequences. We introduce a training-free approach that accelerates 4D mesh generation while improving temporal correspondence quality. Our key observation is that temporal correspondences emerge inside a 4D backbone long before its generated meshes become visually accurate. We exploit this with a general framework we call Spatio-Temporal Attention Chain which propagates information across space and time. Starting from vertices on an anchor mesh, the chain maps vertices to latent tokens. It then follows temporal correspondences in latent space, and recovers frame-specific vertices through latent-to-vertex attention. This design avoids expensive explicit matching while preserving anchor mesh details and thereby improving dynamic mesh geometry and temporal consistency.
Compared to state-of-the-art, our method generates a 4D mesh in 9 seconds, achieving a 13× speedup while producing higher-quality results. Moreover, our approach scales to videos up to 16× longer without degrading mesh quality. Beyond generation, the improved correspondences enable competitive zero-shot performance on two downstream tasks: 2D object tracking and 4D tracking. We further show that our framework enables reliable camera estimation, a capability not supported by prior 4D mesh generation methods.
Spatio-Temporal Attention Chain
Alignment Comparison
Our predicted meshes show tighter pixel-level alignment with the input video frame. In the silhouette overlay (right panel of each comparison): green = our prediction, red = ground‑truth, yellow = overlap.
4D Mesh Generation
Ten ActionBench sequences. Our predicted meshes show higher mesh quality with fewer surface distortions across diverse subjects. Drag the interactive viewers below each video pair to inspect the geometry from any angle.
Autoregressive Long Sequences
4D mesh generation for long-sequence videos (up to 240 frames). Our autoregressive extension keeps the predicted geometry stable across hundreds of frames with no visible drift.
Mesh Placement into a Reconstructed Scene
Our attention-chain correspondences provide point-to-point
matches between the predicted 4D mesh and each input frame.
From these matches we recover a per-frame camera transformation
that aligns the 2D projection of the mesh with the video pixels
and, in turn, lets us drop the mesh into an externally
reconstructed 3D scene reconstructed by
DepthAnything3 [Lin et al; 2026].
Drag to orbit, scroll to zoom; use the panel on the left of the
viewer to step through frames and toggle the mesh, point cloud,
and camera frustums.
2D Tracking
Zero-shot 2D point tracking on TAP‑Vid‑DAVIS. We compare our method against Denoise‑to‑Track, the current zero-shot SoTA. Each colored dot is a tracked query point with its trail.
Cite Us
If you find our work useful, please cite our paper:
@inproceedings{samuel2026fast4dmesh,
title={Fast 4D Mesh Generation by Spatio-Temporal Attention Chains},
author={Dvir Samuel and Yuval Atzmon and Gal Chechik and Yoni Kasten},
year={2026}
}