Abstract
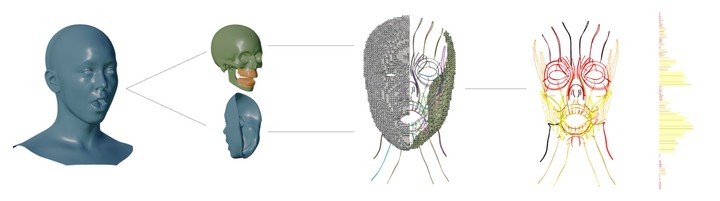
We present a volumetric, simulation-based pipeline for the automatic creation of strain-based descriptors from facial performance capture provided as surface meshes. Strain descriptors encode facial poses via length elongation/contraction ratios of curves embedded in the flesh volume. Strains are anatomically motivated, correlate strongly to muscle action, and offer excellent coverage of the pose space. Our proposed framework extracts such descriptors from surface-only performance capture data, by extrapolating this deformation into the flesh volume in a physics-based fashion that respects collisions and filters non-physical capture defects. The result of our system feeds into Machine Learning facial animation tools, as employed in Avatar: The Way of Water.