
◀▶
TRON (Ours)
UniRelight
arXiv preprint, 2026
TL;DR TRON is a relightable 3D-Gaussian pipeline that pairs the reconstructed scene with a single-step neural renderer adapted from a pretrained video-diffusion model, achieving photoreal rendering quality while preserving full 3D, material, and lighting control at interactive frame rates.
A reconstructed object harmonized into a relit scene — geometry, materials, and lighting all remain user-controllable.
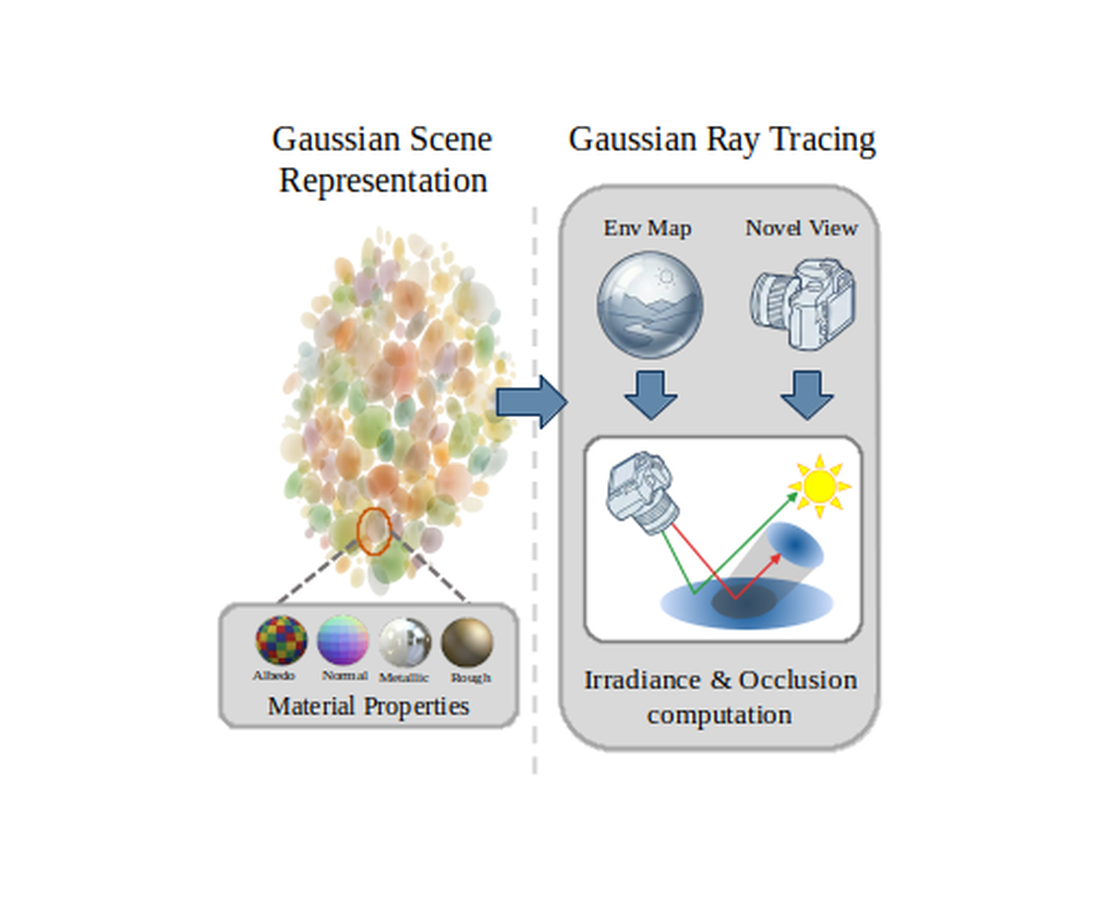


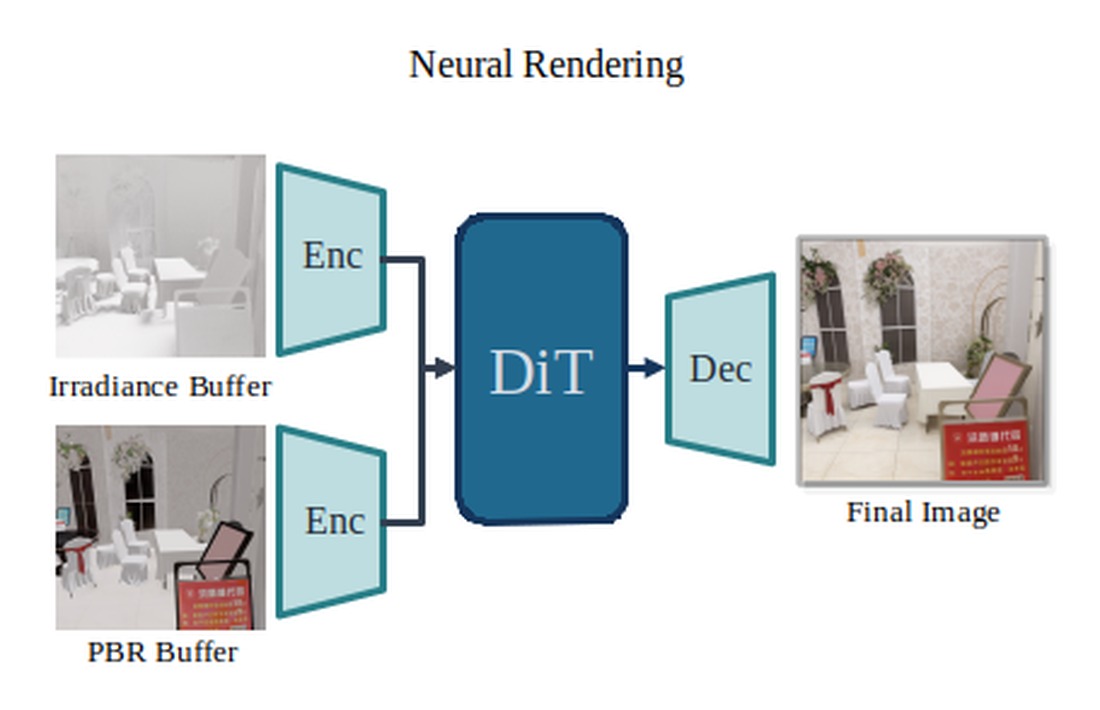

Relightable 3D reconstruction has long faced a hard trade-off: classical PBR-Gaussian pipelines are fast and 3D-consistent but visually limited, while recent video-diffusion relighters are photoreal but slow, expensive to run, and inconsistent over long time horizons. TRON resolves that trade-off by pairing the two: a 3D Gaussian Ray Tracing based scene with explicit materials and lighting carries the physics and the user-facing controls, and a paired single-step neural renderer closes the gap to photoreal video - fast enough to be interactive, faithful enough to compete with full diffusion models. The key insight enabling this is that the ray-traced PBR and irradiance images, while not photoreal on their own, are physically rich enough to act as conditions the neural renderer can translate into a final frame in a single step. Training that translator demands a careful curriculum, and our multi-phase strategy is what makes it work in practice. The result is a system that is simultaneously fast, controllable, and photoreal - enabling downstream edits (relighting, intensity, materials, dynamic-object harmonization) that neither classical nor diffusion-only baselines can offer together.
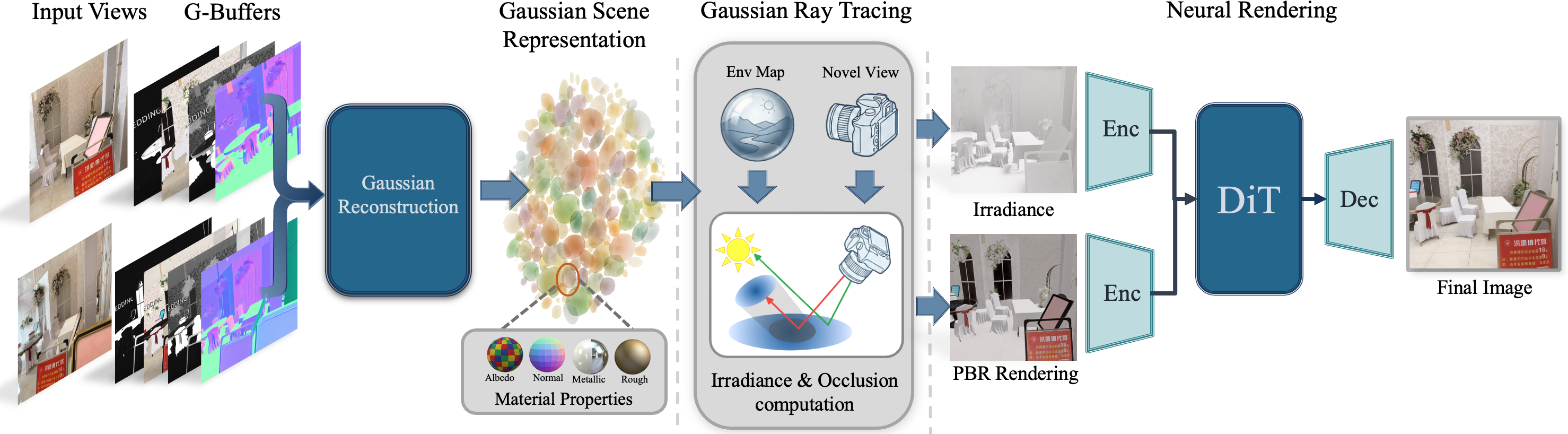
TRON architecture. During training, we apply an intrinsic decomposition model on all input views to get G-buffers and then (1) reconstruct a multi-view scene as a set of 2D Gaussians, and (3) extract G-buffer diffusion priors per view, which we lift and bake in 3D. At inference time, given an envmap and camera view, we (1) render a pair of buffers: PBR shaded and irradiance. (2) Then the Neural Renderer maps these pairs of buffers to a high-quality RGB output image.
Visualizing an NVS trajectory under two different environment maps. Use the buttons to switch between channels — from raw geometry properties (G-buffers) to ray-traced PBR and irradiance conditions to the final Neural Renderer output.
 Environment A
Environment A Environment B
Environment BBecause the scene retains explicit Gaussian geometry and PBR materials — and the renderer is conditioned on physical signals — the same reconstruction supports a broad range of edits: relighting under novel HDR envmaps, light-intensity edits, material editing, and harmonizing dynamic objects into the scene with consistent shadows that track their motion.
Dynamic shadows. A reconstructed armadillo falls into the scene — cast shadows track the object's motion.
Harmonized dynamic NVS. The same object remains photoreal across novel views.
Albedo editing. The armadillo's albedo is re-painted to a vivid blue — geometry, shading, and contact shadows are preserved as the renderer propagates the new diffuse colour.
Albedo + metallic editing. Same geometry, deeper blue albedo with a metallic finish — specular highlights emerge as the metallic parameter is increased.
Drag the slider to change scene illumination intensity — the camera keeps its current position when you slide.

Drag the handle to swipe between TRON (left) and a baseline (right). Switch scene and baseline with the two pill rows below.
Each video below shows the same camera position rendered with 16 different diffusion seeds, played in sequence. TRON conditions on physically-grounded ray-traced buffers and stays stable across seeds; the video-diffusion baselines flicker between seeds because they have no 3D anchor.
TRON (Ours)
UniRelight
DiffusionRenderer (Cosmos)
DiffusionRenderer (SVD)
@article{perel2026tron,
title = {{TRON}: Tracing Rays to Orchestrate a Neural Renderer for {3D} Gaussian Reconstructions},
author = {Perel, Or and Abu Alhaija, Hassan and Wang, Zian and Munkberg, Jacob and Atzmon, Matan and Fidler, Sanja and Shugrina, Masha},
journal = {arXiv preprint arXiv:2606.11314},
year = {2026}
}
We thank Nicolas Moenne-Loccoz, Yuxuan (Alex) Zhang, Miloš Hašan, Zheng Zeng, Jon Hasselgren, Vismay Modi, Sai Bangaru, Zan Gojcic, and Nicholas Sharp for valuable discussions and for their support with the prior work this paper builds upon.