 Toronto AI Lab
Toronto AI Lab
|
|
|
We present a method to train a single, amortized model to output objects for various text prompts, allowing generalization, reduced training cost, and interpolations. |
|
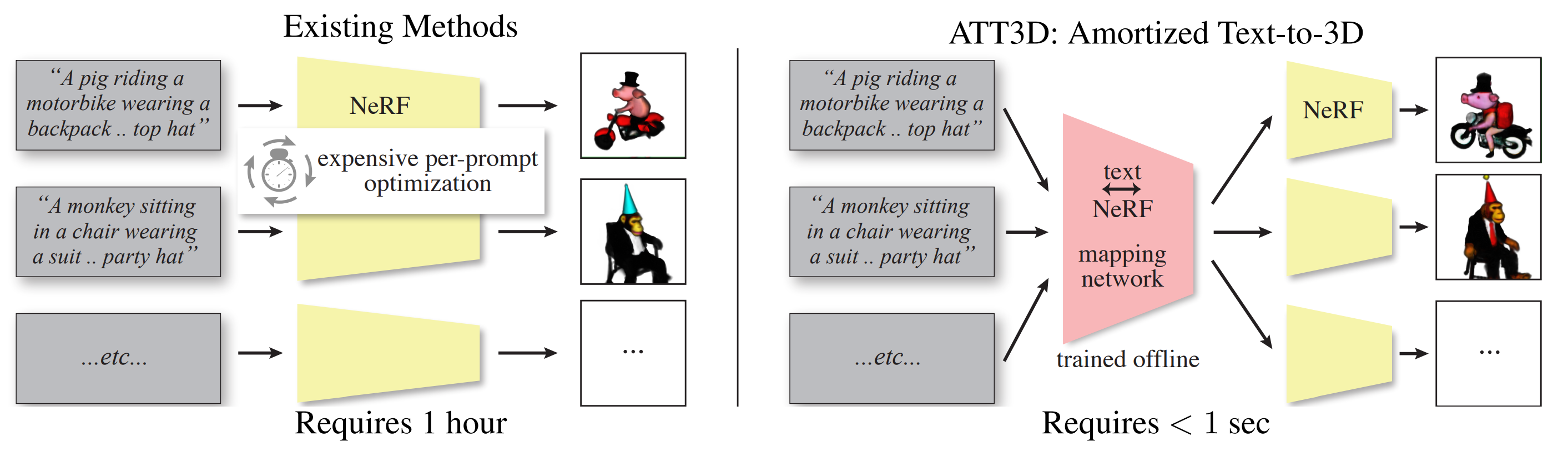
Abstract: Text-to-3D modeling has seen exciting progress by combining generative text-to-image models with image-to-3D methods like Neural Radiance Fields. DreamFusion recently achieved high-quality results but requires a lengthy, per-prompt optimization to create 3D objects. To address this, we amortize optimization over text prompts by training on many prompts simultaneously with a unified model, instead of separately. With this, we share computation across a prompt set, training in less time than per-prompt optimization. Our framework - Amortized Text-to-3D (ATT3D) - enables sharing of knowledge between prompts to generalize to unseen setups and smooth interpolations between text for novel assets and simple animations. |

|
Jonathan Lorraine, Kevin Xie, Xiaohui Zeng,
Chen-Hsuan Lin, Towaki Takikawa, Nicholas Sharp, Tsung-Yi Lin, Ming-Yu Liu, Sanja Fidler, James Lucas ATT3D: Amortized Text-to-3D Object Synthesis 
|
|
Synthesizing high-quality 3D objects from text prompts has seen recent success (ex., DreamFusion, Magic3D, or Score Jacobian Chaining) but requires a lengthy per-prompt optimization. We solve this by optimizing a single, amortized model on many prompts. |
|
|
Use cases: We generalize - i.e., no additional optimization - to unseen testing prompts along the diagonal in red for a compositional dataset with template "a pig {activity} {theme}." Also, we demonstrate using our method – again, with no additional optimization – to create simple animations and continuums of novel assets by linearly interpolating between prompts embeddings. |
|
Our method: ATT3D
|
|
|
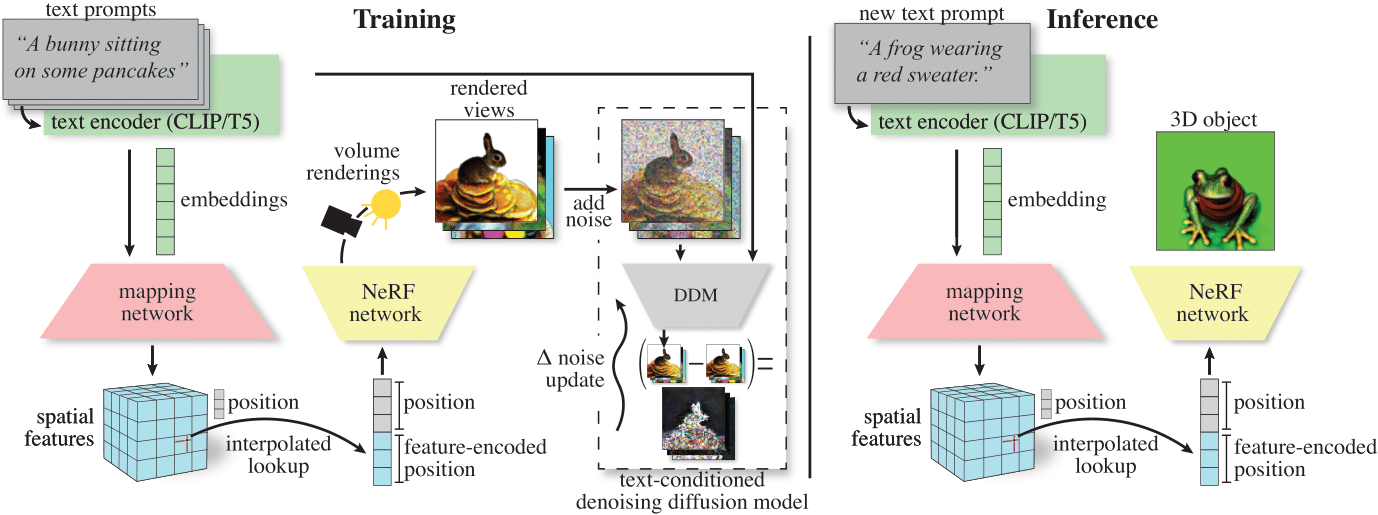
We augment the text-to-3D pipeline to re-use the text-to-image model's text-embedding to condition our 3D representation. We use a NeRF with an instant-NGP backbone, whose spatial parameters we modulate via a hypernetwork inputting text-embeddings. |
|
Benefit: Reduce compute time to train on a set of prompts
|
Our method: ATT3D. We train one, shared model for all prompts from DreamFusion.
|
|
Amortized optimization allows us to obtain a single model which produces 3D objects from a large set of prompts with varying geometric and texture details. |
Baseline: Per-prompt optimization. Each prompt requires a separate model.
|
|
The existing per-prompt optimization strategy involves a lengthy optimization to overfit every text prompt. |
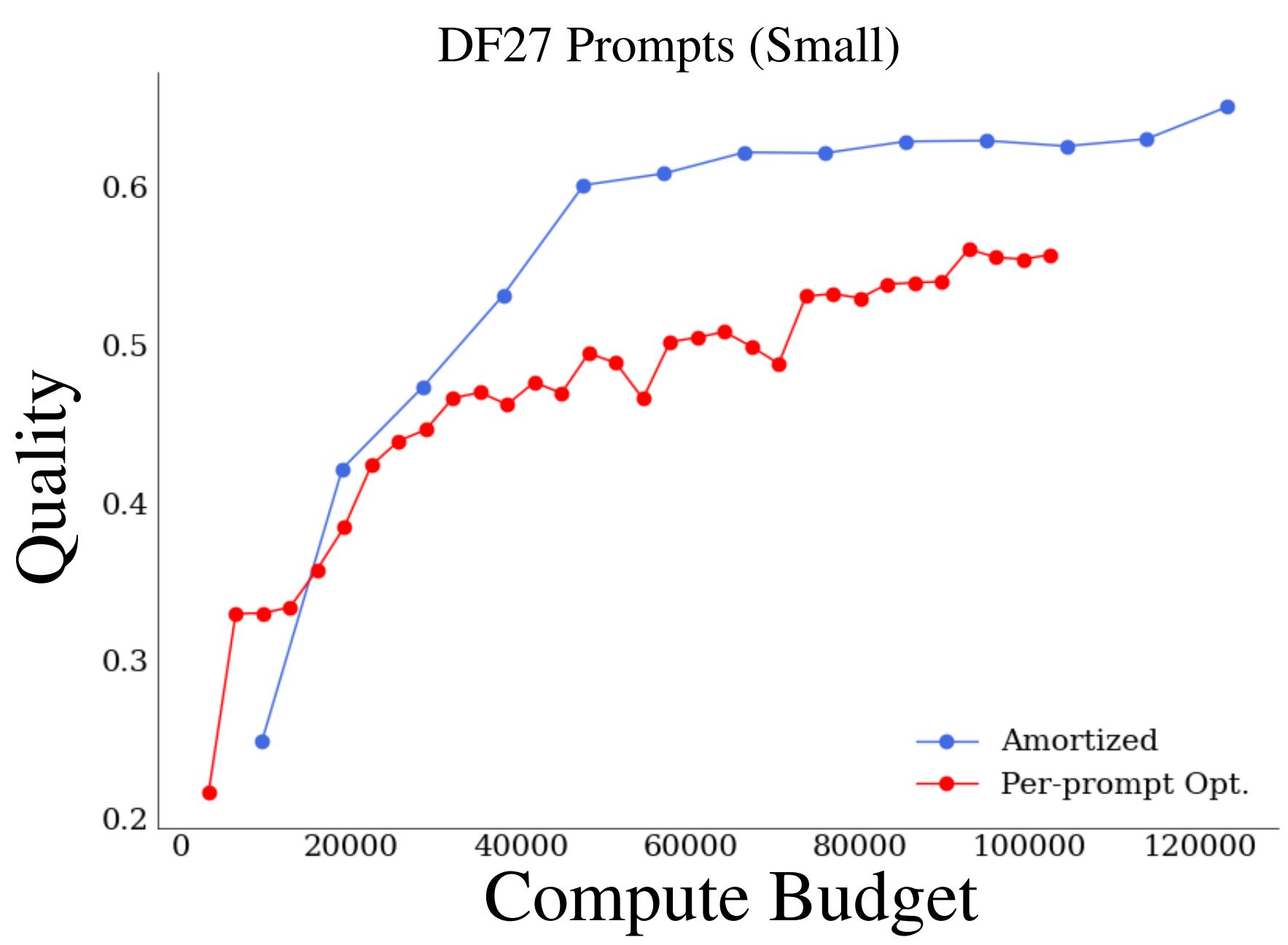
Amortized vs. Per-prompt optimization
|
|
|
We qualitatively and quantitatively compare amortized optimization and the 50% baseline. Amortization allows higher quality (measured by R-probability) for almost all compute budgets (measured by rendered frames per-prompt in optimization). |
Optimizing on an extended prompt set
|
|
We scale to optimizing our model on the extended set of 411 text prompts provided by DreamFusion and compare it to optimizing on the 27 prompts from the main paper. We achieve comparable quality with the exact same model size and compute budget, despite having far more prompts to fit. |
Component re-use

|
|
We show examples of prompts where amortization re-uses components, allowing for compute savings. |
Do we have any generalization?

|
|
On the left, we show generalization to interpolated embeddings, producing suboptimal results, which we improve by amortizing over interpolants. On the right, we offer generalization to compositional prompts, showing promising results, which we improve by training on compositional prompt sets. |
|
Benefit: Generalize to new prompts
|
Amortized Optimization
|
Per-prompt Optimization
|
|
We test amortization's ability to generalize to unseen testing text prompts with a compositional prompt set using the template "a pig {activity} {theme}," with diagonal being held-out testing prompts (in red boxes). Interestingly, amortization learned a shared canonical object orientation. Per-prompt optimization does not have a way to generalize without optimization, so we display the initialization. |
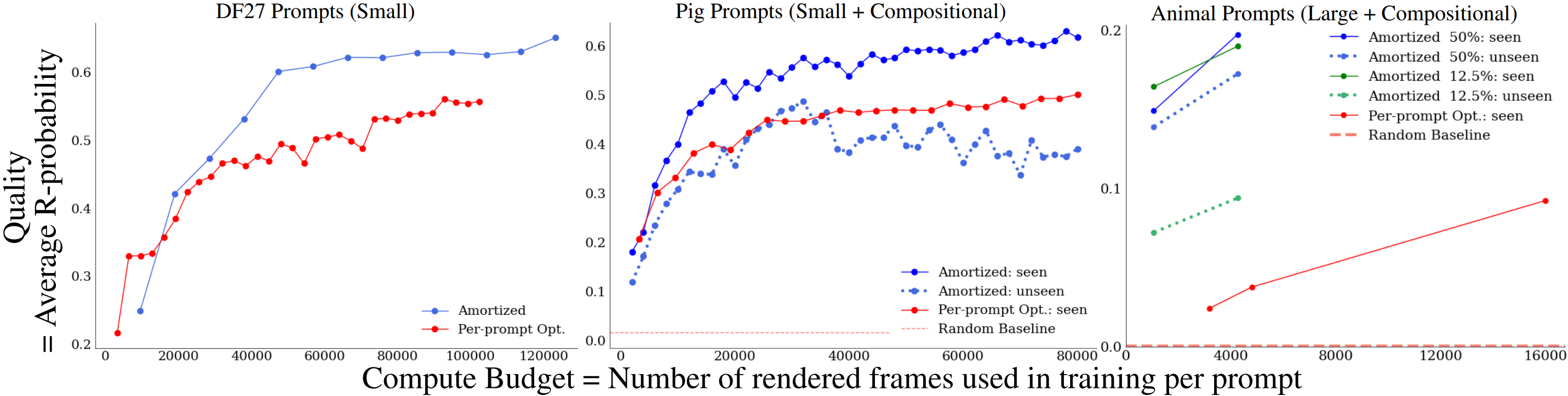
Quantitatively measuring generalization
|
|
We display the quality against compute budget for a split of seen & unseen (dashed) prompts with our method (in blue and green) & the per-prompt optimization baseline (in red). We train on the seen prompt split and evaluate (at each compute budget) zero-shot on unseen prompts. Takeaway: For any compute budget, we achieve a higher quality on both the seen & unseen prompts, with growing benefits for larger, compositional prompt sets. Left: The 27 DreamFusion prompts. Middle: The 64 compositional pig prompts. Per-prompt optimization cannot zero-shot generalize to unseen prompts, so we report a random initialization baseline. Right: The 2400 compositional animal prompts, with varying prompt proportions for training. The generalization gap is small when training on 50% of the prompts. The cheap testing performance is better than the expensive per-prompt method, with only 12.5% of the prompts. |
Per-prompt Optimization
|
Amortized 12.5% split, Unseen Prompts
|
Amortized 50% split, Unseen Prompts
|
|
A single model trained on the animal prompts generalizes to unseen prompts without extra optimization. Notably, when training on only 50% or 12.5% of the prompts, the unseen testing prompts – which cost no optimization – perform stronger than the per-prompt method, which must optimize on the data. |
|
Possible Benefit: More consistent output
|
Amortized optimization
|
||||
Per-prompt optimization
|
||||
|
Amortized optimization may create objects matching the prompts more consistently, helping explain better quantitative performance. Here, amortization always recovers a pig with a blue balloon in the same orientation, while per-prompt optimization may only make the background blue or fail altogether. |
|
Benefit: Finetune on prompts
|
Per-prompt Optimization
|
Amortized + Magic3D
|
Amortized Optimization
|
|
Amortization recovers the correct balloon, which we can finetune using Magic3D’s second stage. Per-prompt optimization fails to recover a blue balloon for "a pig wearing medieval armor holding a blue balloon", which we can not fix with finetuning. |
|
Amortization provides a strong initialization to finetune for unseen prompts, outperforming the per-prompt strategy of optimizing from a random initialization. |
|
Benefit: Interpolate between prompts
|
"snowy rock"

|


|

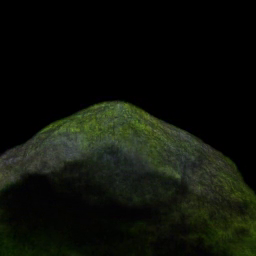
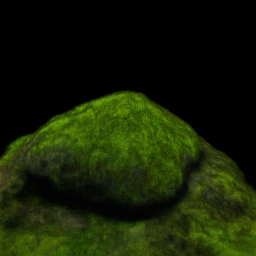
"jagged rock" "mossy rock"
|
|
Our method allows interpolations, unlike per-prompt optimization, which we use to generate a continuum of novel assets – ex., for landscapes and characters – or to create simple 3D animations – ex., for objects aging. Here, we train on three prompts, then generalize on linearly interpolated embeddings to develop a range of terrains. |

|
|
|
Some prompts (like the rocks) provide reasonable interpolants. In contrast, others (like dragons or prior dresses & houses) could benefit from higher-quality midpoints. Next, we show how augmenting our method allows a range of useful interpolant behavior. |
|
Benefit: Amortize over other information
|
Rendered frames from interpolating α with different training objectives
"a hamburger" "a pineapple"
Latent Interpolations

Loss Interpolations
|
|
We amortize over various interpolation types to produce qualitatively different results. On the top, we interpolate the embedding as before. On the bottom, we interpolate the weighting for the loss on each text prompt, producing objects satisfying both losses simultaneously. Notably, we train a single model to do well for any loss weighting via amortization. |
No Train Interpolation
|
Training Guidance Interpolation
|
|
We also amortize over the guidance weight - as an alternative for loss weighting - for a single, amortized model. We contrast with no interpolation at train time, which can naïvely dissolve between the prompts. |
"...dress made out of fruit..."
"...dress made out of garbage bags..."
|
"...cottage with a thatched roof"
"...a house in Tudor style"
|
"a frog wearing a sweater"
"a bear dressed as a lumberjack"
|
"a red convertible car with the top down"
"a completely destroyed car"
|
"a ficus planted in a pot"
"...cherry tomato plant in a pot..."
|
"...a majestic sailboat"
"a spanish galleon..."
|
"jagged rock"
"mossy rock"
|
"a baby dragon"
"a green dragon"
|
|
We display various interpolations between DreamFusion prompts using training guidance interpolation. We also interpolate between longer chains of prompts for more sophisticated results, like seasonality in a tree. |
|
Citation
|
|
Jonathan Lorraine, Kevin Xie, Xiaohui Zeng, Chen-Hsuan Lin, Towaki Takikawa, Nicholas Sharp, Tsung-Yi Lin, Ming-Yu Liu, Sanja Fidler, James Lucas. ATT3D: Amortized Text-to-3D Object Synthesis. The International Conference on Computer Vision (ICCV).
@article{lorraine2023att3d,
|